Conversation
|
Codenotify: Notifying subscribers in CODENOTIFY files for diff 0907cd8...4df29ad.
|
fae04e0 to
fcd6929
Compare
543459e to
74c92d1
Compare
 steveburnett
left a comment
steveburnett
left a comment
There was a problem hiding this comment.
Only a very tiny nit, otherwise LGTM!
There was a problem hiding this comment.
There are some pitfalls (mainly memory-wise) we use KLL in presto_cpp, not sure if they are applicable to this Java implementation or not:
- The sketch is initialized with a fairly large pre-allocated array depending on the error bound. This would cause large memory usage when the number of groups are high and each group only accumulates very few items.
- The serialized form is not very compact and can occupy more memory than it needs. This is ok for the partial aggregation side but would cause memory issue on the final aggregation side.
There was a problem hiding this comment.
Thanks for bringing up these points! Was there anything you did to mitigate them?
re: 1. I haven't checked the code, but didn't consider the performance with a high number of groups since the main target use case for introducing the function is to provide table and partition-level statistics for the optimizer. If you have any thoughts on optimization I would happily discuss.
re: 2: I haven't measured the serialized size but according to the charts on the Apache Datasketches website, a "standard" k value of 200 produces sketches in the range of 2-4k bytes serialized with floats after consuming 1M+ items. Let's generously assume that with doubles, we would consume double the space, so about 8k.
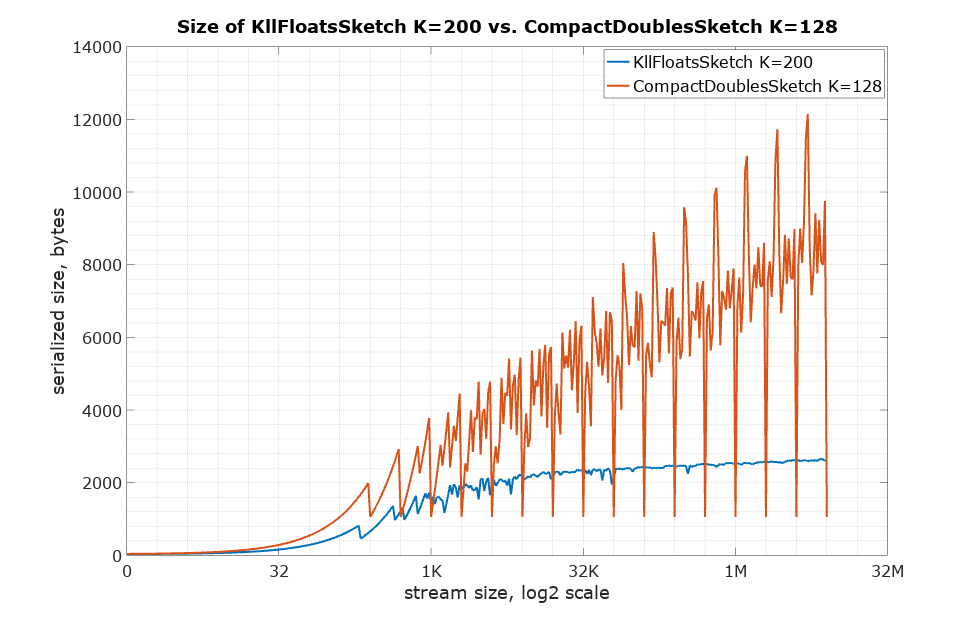
Do you know which parameters effect the number of partial aggregations sent to the final agg? I assumed it's the size of the cluster but, I could be wrong. Even if coalescing 1k KLL sketches in one node this should only consume 8k * 1000 = ~8MB of memory. I feel that shouldn't pose any issue. But it really depends on how many sketches are sent to the final agg step.
There was a problem hiding this comment.
@Yuhta what sort of memory issues were observed?
There was a problem hiding this comment.
For 1 it's easy to fix in the sketch itself, just need to make the sketch grows the bottom layer when the number of elements it keeps is small. You may need to submit PR to datasketches project to fix it though, or copy the code over.
For 2 the size of serialization also depends on how the input data looks like. The worst case comparing to Q/T-digest comes from a lot of identical inputs. In this case Q-digest does not increase the memory usage but KLL does, because it keeps samples of inputs instead of distribution. This multiplied by the number of groups and the fan-in factor of final aggregation sometimes blows it up. One mitigation we did is to compact the sketch before the serialization, this does not resolve the problem completely but we have been good since then on production data.
Both issues can be fixed later though, I just mention it here so we are not surprised when these issues showing up.
...main/java/com/facebook/presto/operator/aggregation/sketch/kll/KllSketchAggregationState.java
Outdated
Show resolved
Hide resolved
...main/java/com/facebook/presto/operator/aggregation/sketch/kll/KllSketchAggregationState.java
Outdated
Show resolved
Hide resolved
756aeb7 to
6a40813
Compare
steveburnett
left a comment
There was a problem hiding this comment.
LGTM! (docs)
New pull of branch and new local build of docs.
...src/test/java/com/facebook/presto/operator/aggregation/TestKllSketchAggregationFunction.java
Outdated
Show resolved
Hide resolved
There was a problem hiding this comment.
Do we also need to add documentation for sketch_kll_with_k ?
There was a problem hiding this comment.
I noticed new content had been added addressing this, so I pulled the branch and made a local build of the docs just now. Here's a screenshot of the newly-added sketch_kll_with_k entry:

...a/com/facebook/presto/operator/aggregation/sketch/kll/KllSketchWithKAggregationFunction.java
Outdated
Show resolved
Hide resolved
...src/test/java/com/facebook/presto/operator/aggregation/TestKllSketchAggregationFunction.java
Outdated
Show resolved
Hide resolved
...n/java/com/facebook/presto/operator/aggregation/sketch/kll/KllSketchAggregationFunction.java
Outdated
Show resolved
Hide resolved
presto-main/src/test/java/com/facebook/presto/operator/scalar/TestKllSketchFunctions.java
Outdated
Show resolved
Hide resolved
...ain/src/test/java/com/facebook/presto/operator/aggregation/TestKllSketchStateSerializer.java
Outdated
Show resolved
Hide resolved
...ain/src/test/java/com/facebook/presto/operator/aggregation/TestKllSketchStateSerializer.java
Outdated
Show resolved
Hide resolved
6a40813 to
905e17b
Compare
 vivek-bharathan
left a comment
vivek-bharathan
left a comment
There was a problem hiding this comment.
lgtm. Just nits from my side
Good work on the memory accounting!
There was a problem hiding this comment.
Is this a real risk? Should this be user-configurable in that case?
There was a problem hiding this comment.
I could see a case where it might be desirable to have it be configurable, but that's why we have the sketch_kll_with_k function so users can pass any value they want. I put this here to (1) extract constant value from all of the call sites and (2) provide a stable default in the case the library changes the default after an upgrade. A different value will affect the storage size of the sketch, so I wanted something that would be stable within the Presto code base.
There was a problem hiding this comment.
These two addMemoryUsage(s) should cancel each other right?
There was a problem hiding this comment.
They might not - since state is mutable, Line 67 creates a new sketch which may have a different size than the result of state.getSketch() at that time. So, we need to subtract the current state (Line 68), set the new state (line 69) and re-calculate the size (Line 70)
...main/java/com/facebook/presto/operator/aggregation/sketch/kll/KllSketchAggregationState.java
Outdated
Show resolved
Hide resolved
c026de4 to
d817bec
Compare
This change adds KLL Sketch support from the Apache DataSketches library. One of the benefits of KLL sketches is that the implementation supports more datatypes than the existing quantile digest and T-Digest implementations. The following functions are added - `sketch_kll`: computes a KLL sketch - `sketch_kll_with_k`: computes a kll sketch with the given value for k - `sketch_kll_quantile`: queries the sketch for a particular quantile - `sketch_kll_rank`: queries the sketch for a particualr rank (inverse of the quantile function)
d817bec to
4df29ad
Compare
|
I think we need to document the serialized binary format, similar to T-Digest and QDigest. Otherwise, they're completely unreadable by any other system. |
The serialized binary format is specified by the Apache Datasketches library. This is already noted in the docs changes. If this is confusing I can try to update the phrasing |
|
I can't find where they explicitly document the binary format--is there a link for that? |
|
The binary format is not documented unfortunately. However, all versions (cpp, java, go, etc) of the datasketches libraries can serialize and deserialize the sketches. e.g. java can deserialize cpp serialized sketches, and vice versa. AFAIK this is the case for all sketches coming from the datasketches library. |
4df29ad
...main/java/com/facebook/presto/operator/aggregation/sketch/kll/KllSketchAggregationState.java
Show resolved
Hide resolved
|
Just for some continuity on the discussion of sketch serialized format compatibility, we brought this to their community in hopes to clarify the guarantees that the maintainers provide. This resulted in some changes to the datasketches documentation in apache/datasketches-website#162 and subsequently apache/datasketches-website#163 |
|
Possible follow up: if KLL has a provable error bound, could we use it to replace Q-Digest inside of approx_distinct? The only reason approx_distinct uses Q-Digest under the hood, in spite of its poor performance compared to T-Digest, is it has a provable error bound. |
|
I'm not familiar with the code for This could be a good project/experiment for a new Presto contributor |
|
The binary format is defined here: https://github.com/apache/datasketches-java/blob/master/src/main/java/org/apache/datasketches/kll/KllPreambleUtil.java Obviously the format for items cannot be defined for arbitrary type T, and the exact size of the levels array is not fixed. But the serialized header is defined, as is the order of the non-fixed-size/format data. |
|
@Yuhta, The KLL sketch always serializes ( It is true that if the sketch image were compressed it would become even smaller, but that can be costly in terms of time. That is not an option we currently offer as part of the sketch, but as long as one is using lossless compression algorithms, it is something you could do yourself. If you could elaborate you concern a bit more it would help us understand the issue. Thanks! |
Description
This change adds KLL Sketch support from the Apache DataSketches library. One of the benefits of KLL sketches is that the implementation supports more datatypes than the existing quantile digest and T-Digest implementations. It also has provably-bounded error compared to the T-Digest
The following datatype is added
kllsketch(T): Basically a wrapper aroundvarbinary, similar totdigestandqdigesttypesThe following functions are added
sketch_kll: computes a KLL sketchsketch_kll_with_k: computes a kll sketch with the given value for ksketch_kll_quantile: queries the sketch for a particular quantilesketch_kll_rank: queries the sketch for a particular rank (inverse of the quantile function)Motivation and Context
Eventual use by the optimizer after #21236. But also good to have since HMS is releasing support for them soon.
Impact
Two new aggregation functions, two new scalar functions
Test Plan
Standard aggregation unit tests and scalar function unit tests
Contributor checklist
Release Notes