Fix druid connector bugs related to pushed down queries#14967
Fix druid connector bugs related to pushed down queries#14967zhenxiao merged 2 commits intoprestodb:masterfrom
Conversation
 zhenxiao
left a comment
zhenxiao
left a comment
There was a problem hiding this comment.
hi @weidongduan37 there is some work going on for timestamp pushdown:
#14952
I think we might merge that soon.
There was a problem hiding this comment.
I think better not through PrestoException here. Could we do:
checkState(!hasAggregation && !hasFilter, ...)
There was a problem hiding this comment.
Throw PrestoException here is intended here I think. checkState will make query failed directly. if query are like:
select a , sum(b) from druid_table where c = 'xxx' group by 1 having sum(b) > 0;
Throw PrestoException will help make the filter sum(b) > 0(on top of aggregation node) executed in presto(not in druid). The reason not push down such filter right now is because we could not make sure all filters on top of aggregation node could be pushed down. Following code will catch this exception and make queries work(DruidQueryGenerator.java):
public Optional<DruidQueryGeneratorResult> generate(PlanNode plan, ConnectorSession session)
{
try {
DruidQueryGeneratorContext context = requireNonNull(plan.accept(
new DruidQueryPlanVisitor(session),
new DruidQueryGeneratorContext()),
"Resulting context is null");
return Optional.of(new DruidQueryGeneratorResult(context.toQuery(), context));
}
catch (PrestoException e) {
log.debug(e, "Possibly benign error when pushing plan into scan node %s", plan);
return Optional.empty();
}
}
There was a problem hiding this comment.
After check #14952 changes, I think we are trying to solve different cases. His code focuses on time with timezone. I think our code is compatible.
By the way, the 1st and 3rd example he gave could be pushed down by original code. His change may be helpful for the 2nd example.
First:
select * from druid.wikipedia where __time > timestamp '2016-06-26 18:00:00.000'
Second:
select * from druid.wikipedia where __time > timestamp '2016-06-26 19:00:00.000 UTC';
Third:
select * from druid.wikipedia where __time > CAST('2016-06-26 18:00:00.000' as TIMESTAMP);
And the pushed down dql will be as following by original code:
first:
select col1,col2,.. from druid.wikipedia where __time > '2016-06-26 18:00:00.000'
third:
select col1, col2,.. from druid.wikipedia where __time > '2016-06-26 18:00:00.000'
There was a problem hiding this comment.
Can I have the query you are using for test? For the query below I ran, this 'if' statement is not reachable.
select * from druid.wikipedia where __time > timestamp '2016-06-26 19:00:00.000';
Because for the call 'greater_than(__time, timestamp)', it will go through line 177. And the second argument of this call is a constant which will go to the 'visitConstant' method and then call the getLiteralAsString
There was a problem hiding this comment.
Hi,
I use the following test case for original code before I change:
SELECT * FROM druid.druid.wikipedia where __time > timestamp '2015-09-12 00:00:00.000' limit 1;
You could check following plan:
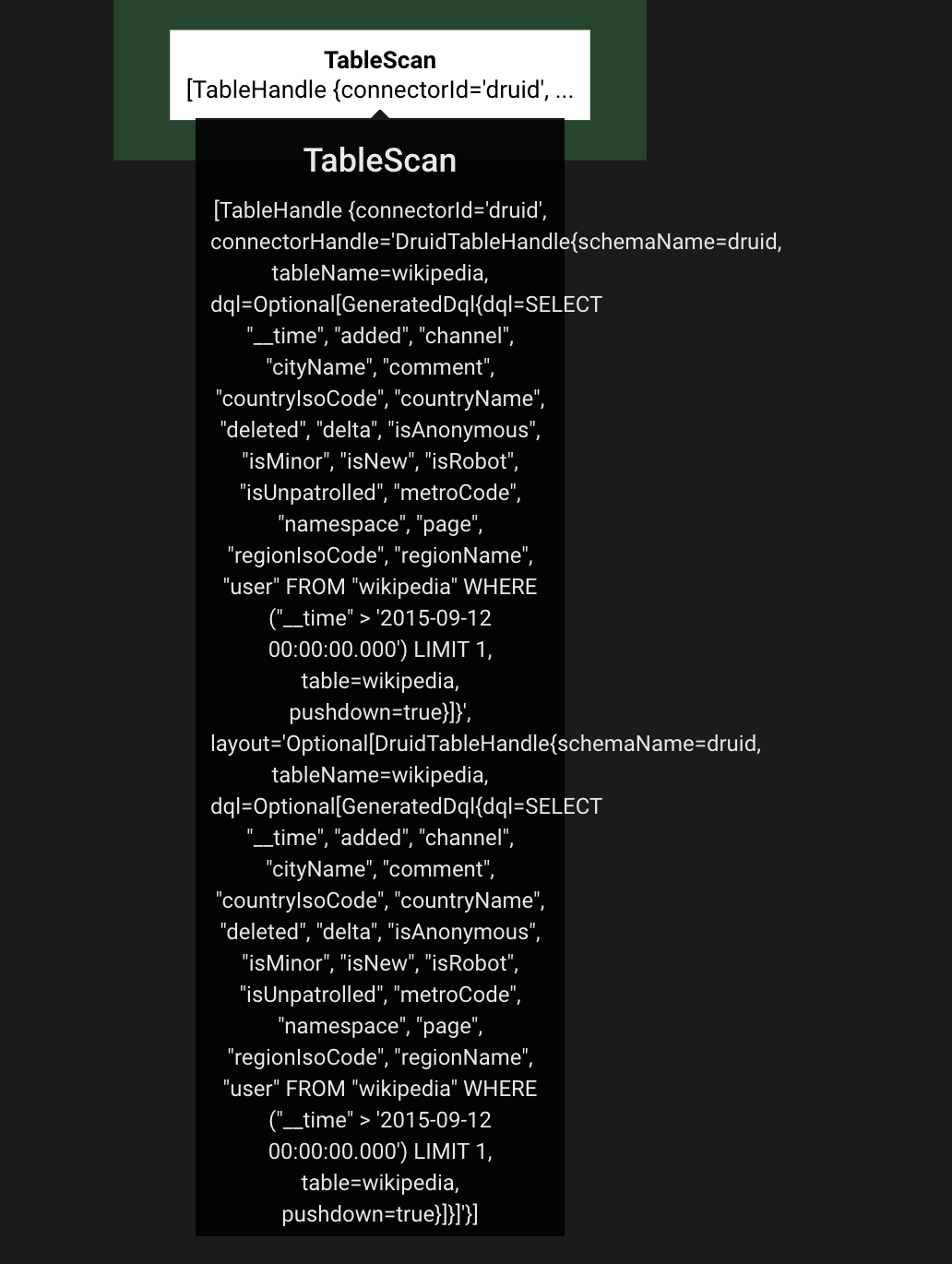
And will not go to line 177 as following,
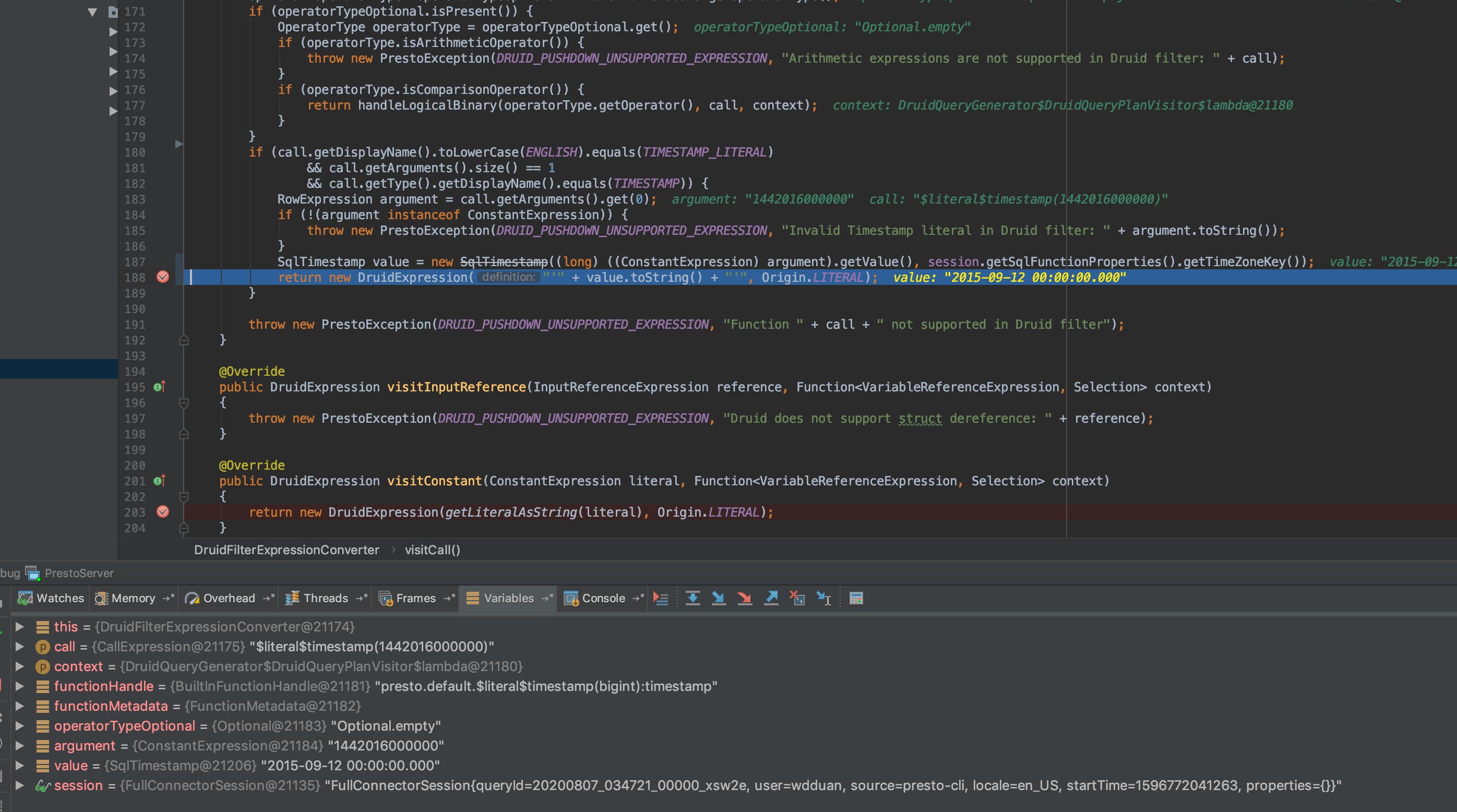
After the code I change:
SELECT * FROM druid.druid.wikipedia where __time > timestamp '2015-09-12 00:00:00.000' limit 1;
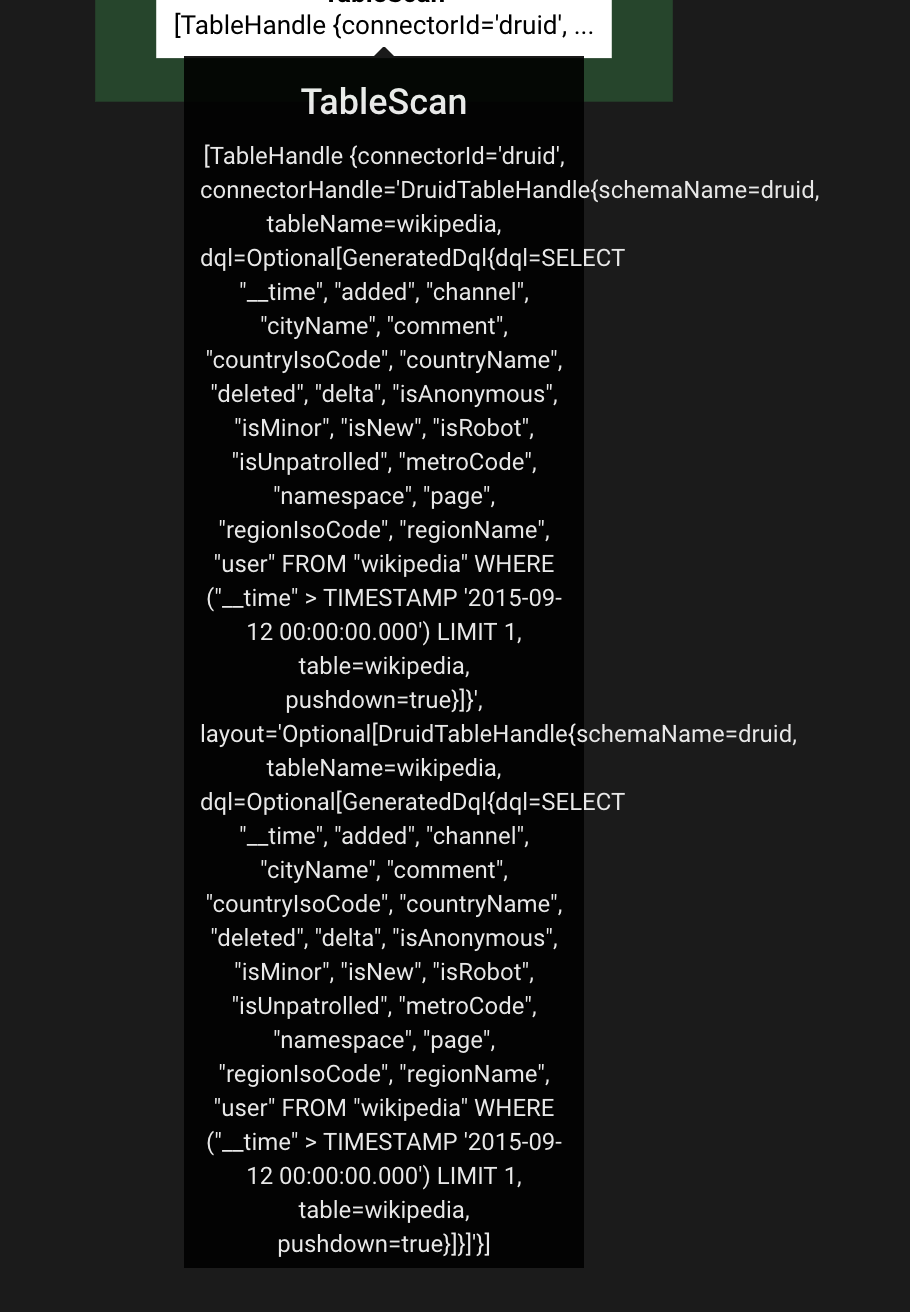
SELECT * FROM druid.druid.wikipedia where __time = timestamp '2015-09-12 00:00:00.000' limit 1;
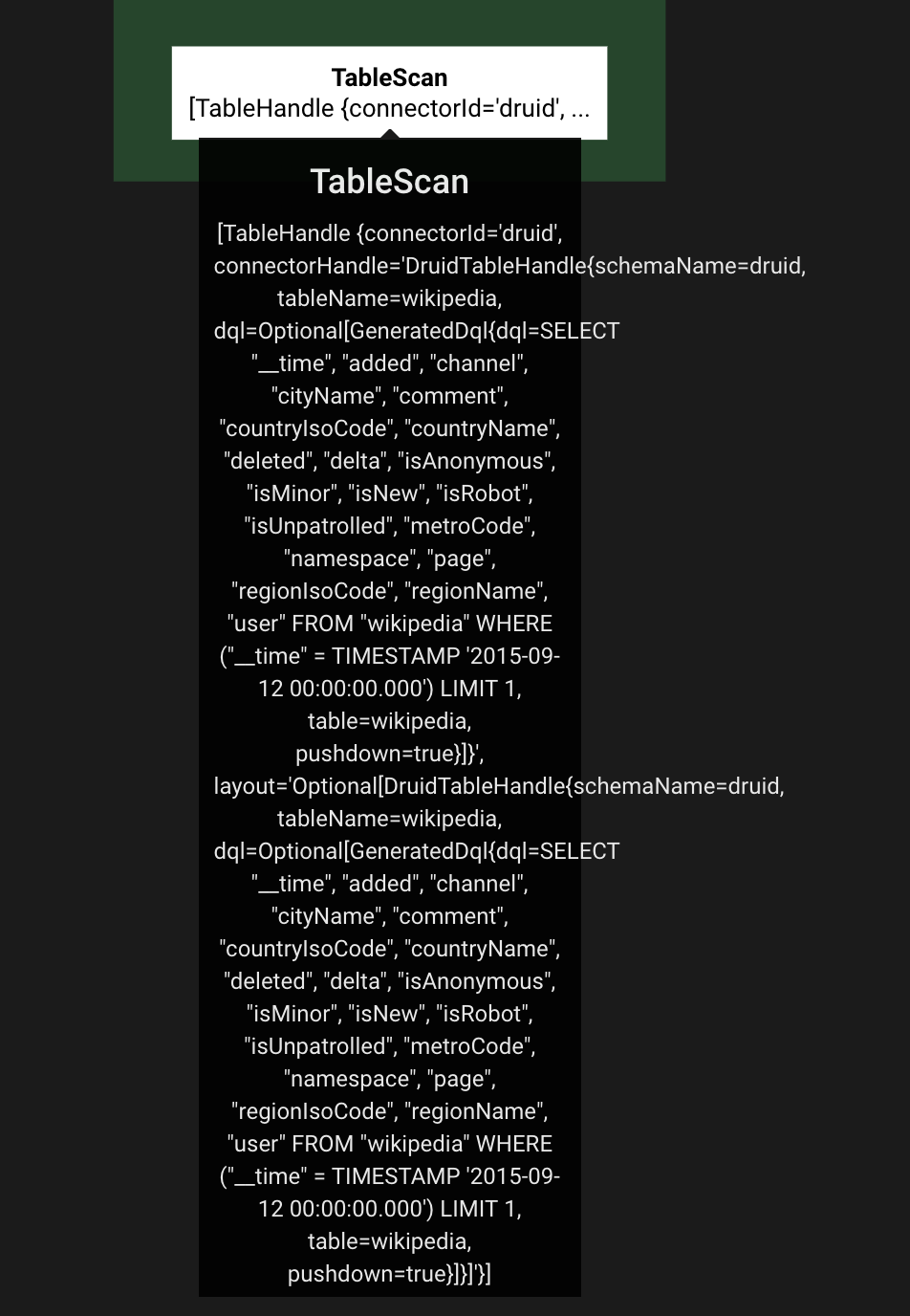
Hopefully It's helpful.
There was a problem hiding this comment.
Got it with many thanks!
Looks like the difference is on the RowExpression. The timestamp I got is a constant expression, but you got is a call of '$literal$timestamp' . I will look into it. Thanks!
There was a problem hiding this comment.
have you rebased onto the most recent master? I think some of the behavior might changed, just guessing, it could explain why we are seeing different RowExpression type. Thanks!
There was a problem hiding this comment.
Yes, you are right. I try on recent release 0.238.2, the logic is still same as what I say. But on recent master, the behavior is just as what you said. I think there may be some changes in presto-main or presto-spi that does not take druid connector into consideration. I am worried that there may be other potential affects besides this one we find. (I doubt that the recent change in planOptimizers result in this incompatibility)
There was a problem hiding this comment.
hi, @zhenxiao, I could revert my code related to time pushed down, And hope the PR from beinan will fix it due to the change out of druid connector. Is it ok from your opinion? Or is it better to involve others to find out which commit result in this unexpected problem to avoid potential affects?
There was a problem hiding this comment.
thanks for the discussion @weidongduan37 @beinan
sure. go ahead. Let's rebased on most recent master, and revert time pushdown changes in this PR.
I will follow up with optimizer changes. My guess is RowExpression is replacing Expression recently.
There was a problem hiding this comment.
I don't think we can ignore the timezone here. The session here is the ConnectorSession, we cannot assume the connection to druid is always using UTC (though now it's just using UTC).
By default, time operations use the UTC time zone. You can change the time zone by setting the connection context parameter "sqlTimeZone" to the name of another time zone, like "America/Los_Angeles", or to an offset like "-08:00". If you need to mix multiple time zones in the same query, or if you need to use a time zone other than the connection time zone, some functions also accept time zones as parameters. These parameters always take precedence over the connection time zone.
from Druid https://druid.apache.org/docs/latest/querying/sql.html#time-functions
There was a problem hiding this comment.
Hi,
The original code is definitely a bug here and the result is not consistent with other connector like Hive. For example, the client is in Asia/Shanghai. If I do not change the code:
presto> select now();
_col0
---------------------------------------
2020-08-07 13:11:15.704 Asia/Shanghai
(1 row)
presto> SELECT __time FROM druid.druid.wikipedia where __time > timestamp '2015-09-12 00:00:00.000' and __time < timestamp '2015-09-12 01:00:00.000' limit 10;
__time
-------------------------
2015-09-12 08:46:58.771
2015-09-12 08:47:00.496
2015-09-12 08:47:05.474
2015-09-12 08:47:08.770
2015-09-12 08:47:11.862
2015-09-12 08:47:13.987
2015-09-12 08:47:17.009
2015-09-12 08:47:19.591
2015-09-12 08:47:21.578
2015-09-12 08:47:25.821
(10 rows)
Query 20200807_040053_00004_xsw2e, FINISHED, 1 node
Splits: 17 total, 17 done (100.00%)
0:02 [10 rows, 90B] [4 rows/s, 43B/s]
Is it reasonable?
The result is out of my constraint:
__time > timestamp '2015-09-12 00:00:00.000' and __time < timestamp '2015-09-12 01:00:00.000'
This behavior is not consistent with other connectors, like hive.
The key point here is: ((ConstantExpression) argument).getValue() is already in UTC before go into druid connector. The client will convert the result time to Asia/Shanghai again.
You could try to query other connector like hive.
There was a problem hiding this comment.
I agree with you, it's definitely a bug, but I think the root cause is we are not passing the timezone into druid by the context parameter "sqlTimeZone".
According to the doc, the default timezone in Druid is UTC, so we can just use the millisecond value in UTC as you said ((ConstantExpression) argument).getValue() is already in UTC. For sure, your change could fix the issue, but we might lost the flexibility of setting the sqlTimeZone on client side.
Just for now, I'm fine with either way, your call.
presto-druid/src/main/java/com/facebook/presto/druid/DruidQueryGeneratorContext.java
Outdated
Show resolved
Hide resolved
"having" condition for sql involves "group by" is common case, and it will generate a FilterNode on top of AggregationNode. Previously, The SQL will fail directly, and now it allows such case. However, such filter is not pushed down to Druid, just filter at presto side because we could not confirm all filters on top of AggregationNode have corresponding 'dql' pattern to describe it.
7007046 to
28da710
Compare
|
@zhenxiao, I have already reverted code back related to __time pushed down, and follow your suggestion to simplify the logic. Thanks. |
zhenxiao
left a comment
There was a problem hiding this comment.
thank you, @weidongduan37 LGTM
No description provided.