{kind=link}
{kind=link}
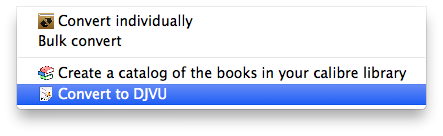
This plugin adds DJVU output conversion for Postscript documents (*.pdf, .ps). Files can be converted through a GUI menu and optionally as FileType hook for automatically converting imports of all Postscript documents.
DjVU format is ideal for reading large black & white scanned Google Books on E-Readers with >300MB RAM and >2GB flash. Big 100+ page books scanned into PDF format usually slow these devices' built-in software to a halt.
To read DJVU files on the Kindle, I suggest koreader/koreader.
PDF is still better for vector/markup based "ebooks" so this plugin will not try to convert documents it detects having less than 1 raster image per page.
-
Right click the preferences button in calibre, select get new plugins, scroll down the list and choose the DjVuMaker plugin to install
- Or clone this repo and install from source
git clone https://github.com/kfix/calibre_plugin_djvumaker cd calibre_plugin_djvumaker calibre-customize -b ./ -
[Required] Build the conversion programs (fixme: works only on macOS, check next section for solution for other systems)
calibre-debug -r djvumaker -- backend install djvudigital -
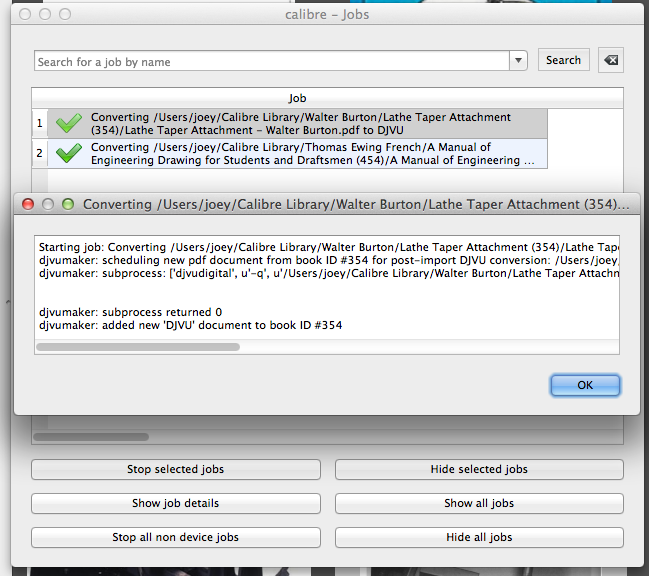
(Re)start Calibre and start converting your PDF books!
-
[Optional] go to Preferences -> Interface::Toolbars so you can place the DJVU menu where you see fit.
For all having troubles with building GsDjvu there is possibility to install secondary backend - pdf2djvu. The pdf2djvu is a pdf to djvu converter developed by Jakub Wilk (GitHub). Although produces less compresed files than djvudigital it's installation is much simplier. For Windows (fixme: works only on Windows) there is also a posibility to install it through this plugin:
calibre-debug -r djvumaker -- backend install pdf2djvu
calibre-debug -r djvumaker -- backend set pdf2djvuAlso you can just add pdf2djvu to your path and:
calibre-debug -r djvumaker -- backend set pdf2djvu
The main diferences betwent pdf2djvu and djvudigital are listed here.
There are a few implementations of DjVU tools in the wild, but the fastest and most robust free one is the DjVuLibre suite and its Ghostscript plugin "GsDjvu". GsDjvu was witlessly licensed by AT&T with a "free" but GPL-incompatible license which makes pre-compiled packages impossible to publically distribute. Therefore both packages must be built by the user in a complicated procedure, which the plugin tries to facilitate when installed into Calibre.
Calibre's conversion API currently supports two pipelines:
- markup-based ebooks (book.xfmt > book.OEB > book.yfmt): useless for working on image-based scans.
- comic books (*.cbz): unusably slow for library books due to its over-reliance on Python for its transform pipeline.
Only ghostscript+gsdjvu delivers usable conversion times for large scanned books. Patching Calibre's conversion API to add a 3rd pipeline to support them would be far more involved than this sub-500-line plugin (excluding these explanations :-).
usage: calibre-debug -r djvumaker -- [-h] [-V] command ...
positional arguments:
command
backend Backends handling.
{install,set} installs or sets backend
{pdf2djvu,djvudigital} choosed backend
convert Convert file to djvu.
-p PATH, --path PATH convert file under PATH to djvu using default settings
-i ID, --id ID convert file with ID to djvu using default settings
--all convert all pdf files in calibre's library, you have to turn on postimport
conversion first, works for every backend
postimport Change postimport settings
-y, --yes sets plugin to convert PDF files after import (sometimes do not work for pdf2djvu)
-n, --no sets plugin to do not convert PDF files after import (default)
install_deps (depreciated) alias for `calibre-debug -r djvumaker -- backend install djvudigital`
convert_all (depreciated) alias for `calibre-debug -r djvumaker -- convert --all`
optional arguments:
-h, --help show help message and exit
-V, --version show plugin's version number and exit