A CLI tool specifically designed to scrape this webpage: https://www.jobspider.com/job/
- Make sure you have virtualenv package installed on your local machine and the cloned repository is your current directory. If not:
pip install virtualenv
- Create environment with environment name(here
venv):
virtualenv venv
- Activate the environment with:
source venv/bin/activate
- To install the dependencies for this project, use the
requirements.txtfile:
pip install -r requirements.txt
- Again, make sure you are inside the repository. To use the command and get help, type:
$ python3 scrape_cli.py -h
-
There are two command options:
--category <number>and--domain <keyword>:-
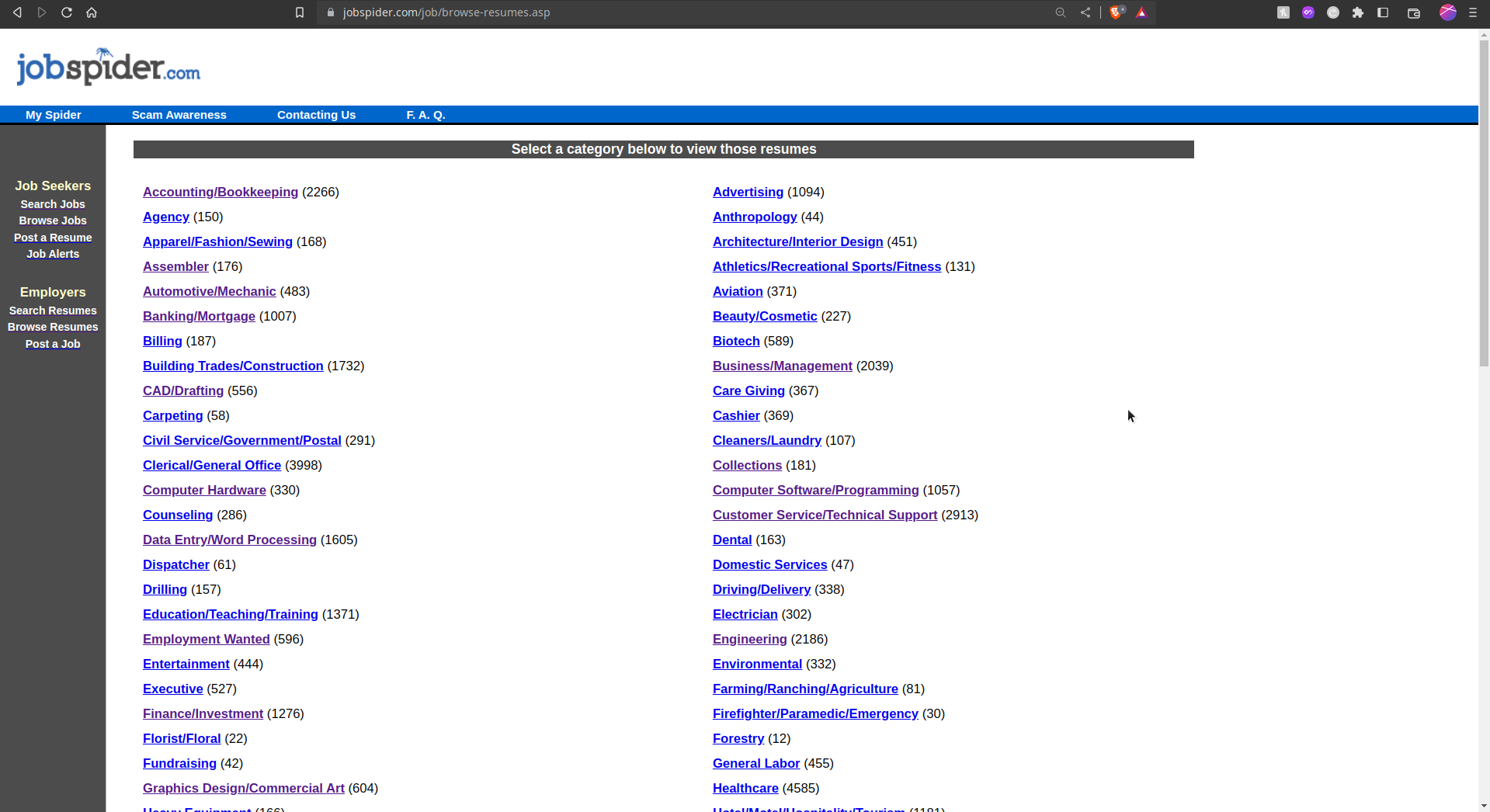
For scrapping the Resumes by category, go to this url: https://www.jobspider.com/job/browse-resumes.asp and select the category:

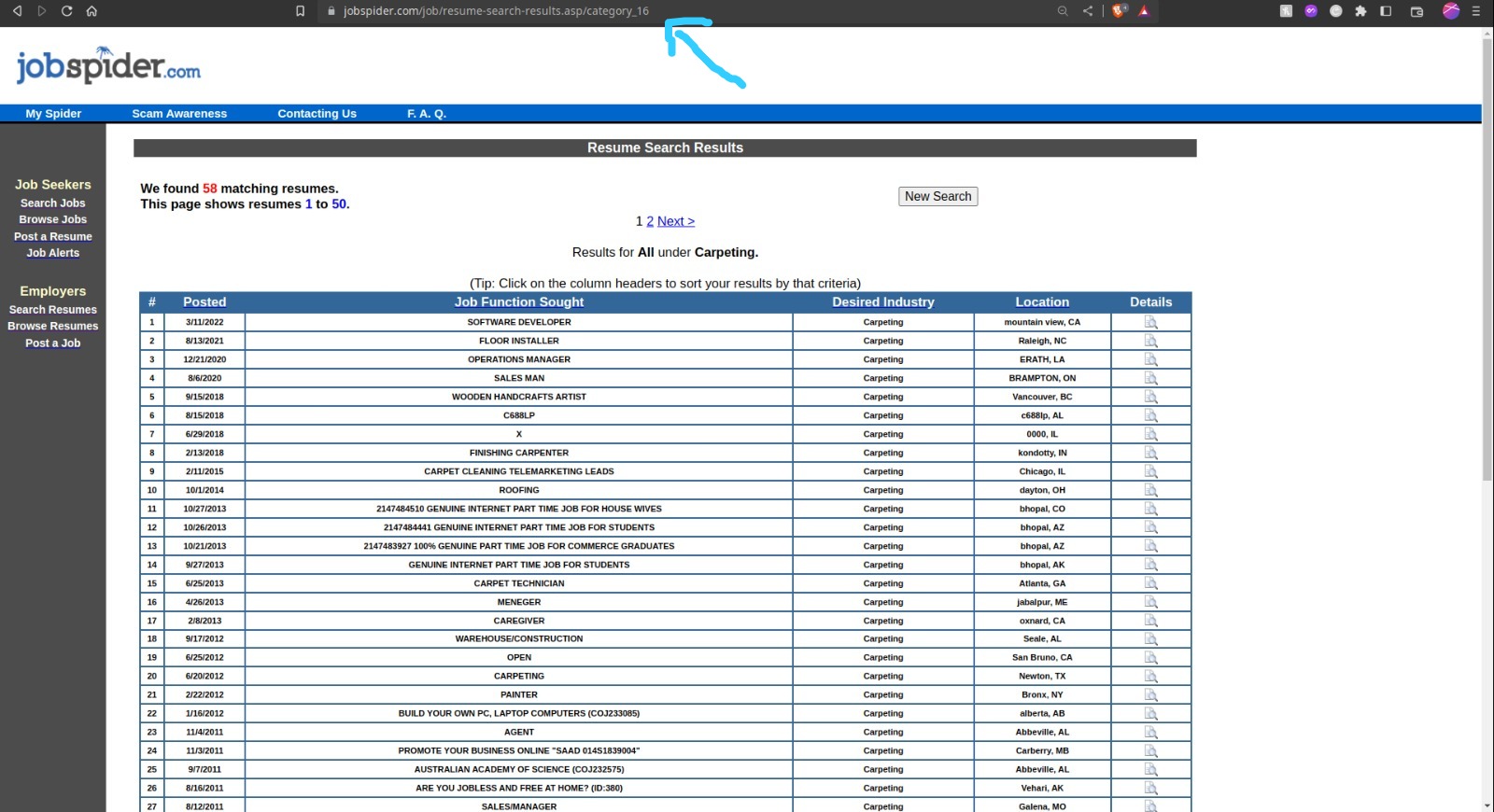
Check the category number in the url-

Go back to your command line and enter the category number argument (here in the image, 16)
$ python3 scrape_cli.py -c 16 -
For scrapping by search keyword, go to this url: https://www.jobspider.com/job/resume-search.asp

Enter the same keyword used in the search box in the command line argument like this
$ python3 scrape_cli.py -d developer
-

If done correctly you'll get a final web scrapped summary of resumes!