test: Require no alerts during upgrades #25904
Conversation
|
[APPROVALNOTIFIER] This PR is APPROVED This pull-request has been approved by: smarterclayton The full list of commands accepted by this bot can be found here. The pull request process is described here DetailsNeeds approval from an approver in each of these files:
Approvers can indicate their approval by writing |
|
/retest |
|
/test e2e-gcp-upgrade |
|
/retest |
d2e549b to
9353bfd
Compare
test/e2e/upgrade/alert/alert.go
Outdated
| time.Sleep(alertCheckSleep) | ||
| cancel() | ||
| g.By("Waiting before checking for alerts") | ||
| time.Sleep(2 * time.Minute) |
There was a problem hiding this comment.
Not clear to me why we're reducing from alertCheckSleepMinutes = 5 to 2m here. I don't have strong feelings either way, but it's nice when folks who do feel like a constant needs tweaking explain their motivation for the tweak, so the rest of us don't forget to consider whatever the motivation was in future changes.
There was a problem hiding this comment.
Actually, I'm wondering if we should be checking for zero pending alerts here. Since the wait is basically arbitrary.
There was a problem hiding this comment.
Pending alerts might flap. In the case where we don't alert for a condition if the control plane is not ready (or in the future if a particular node is down), as soon as the control plane is ready or the node is up, we will meet the criteria of the alert for pending if a pod can't come up in the monitoring interval.
There was a problem hiding this comment.
I originally made this 5 minutes based on my test runs and what I thought would always be long enough to ensure the upgrade is complete without being excessively long.
Seems the use of constants is different than what I'm used to although not necessarily wrong.
There was a problem hiding this comment.
Things happen during updates that may trip alerts into pending without anything actually concerning happening. I suspect we want to allow that. But even if we decide we don't want to allow pending alerts, this current pivot to blocking almost all firing alerts is already big enough, that I'd prefer to punt pending discussion to follow-up work.
There was a problem hiding this comment.
I'm changing this so that after upgrade there should be no pending alerts. I see none that aren't serious bugs in the few samples I have here.
I'm changing the interval to 1m and requiring no pending.
9353bfd to
85363fe
Compare
|
I changed the pending check, it didn't make sense (you can't know by looking at a prometheus instance when it was up, because you can't tell the difference between planned outage and crash). Now the check is "is the watchdog alert firing continuously during upgrade EXCEPT when this other rule is not firing". The real invariant we're trying to maintain is that "if you query thanos-querier for the range of time over the upgrade, the watchdog query shows up" which is really "thanos querier sees all the data and doesn't violate its SLO to be up continuosly across safe rolling updates" which is a product SLO. |
test/e2e/upgrade/alert/alert.go
Outdated
| // when the cluster is running. We do not use the prometheus_* metrics because they can't be reviewed | ||
| // historically. | ||
| // TODO: switch to using thanos querier and verify that we can query the entire history of the upgrade | ||
| watchdogQuery := fmt.Sprintf(`sum_over_time((ALERTS{alertstate="firing",alertname="Watchdog",severity="none"} * scalar(absent(max(openshift:prometheus_tsdb_head_samples_appended_total:sum*0+1))))[%s:1s]) > 0`, testDuration) |
There was a problem hiding this comment.
Poking at the CI job with PromeCIeus: update from 2021-02-22T20:35:58Z to 2021-02-22T21:40:29Z, and Prom was down from 21:24 to 21:26:
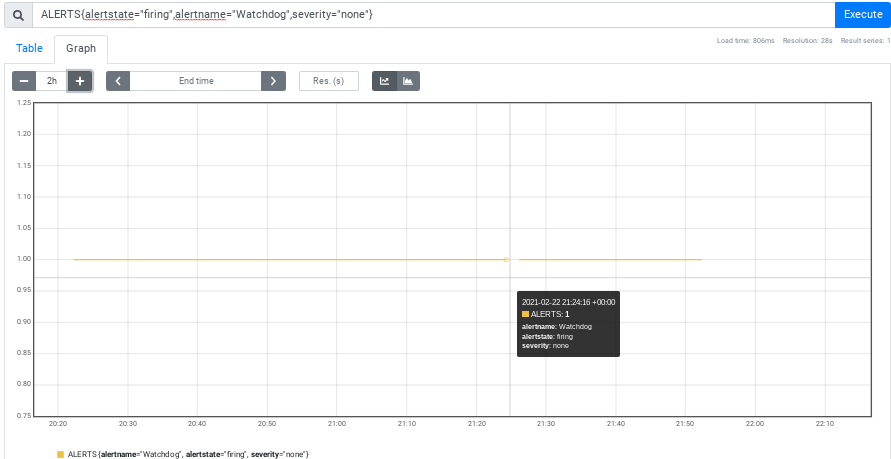
Is Prom going down like that mid-update acceptable? If it is, I think we should drop the Watchdog guard. If not, I think we should drop the scalar(absent(... business.
There was a problem hiding this comment.
This is the thanos-querier change i mentioned in slack.
| // Query to check for any critical severity alerts that have occurred within the last alertPeriodCheckMinutes. | ||
| criticalAlertQuery := fmt.Sprintf(`count_over_time(ALERTS{alertname!~"Watchdog|AlertmanagerReceiversNotConfigured|KubeAPILatencyHigh",alertstate="firing",severity="critical"}[%dm]) >= 1`, alertPeriodCheckMinutes) | ||
| // There should be no pending alerts 1m after the upgrade completes | ||
| pendingAlertQuery := `ALERTS{alertname!~"Watchdog|AlertmanagerReceiversNotConfigured",alertstate="pending",severity!="info"}` |
There was a problem hiding this comment.
nit: I think we can drop Watchdog here, because it should never be pending.
|
Update job hit the |
33e96a8 to
eb03751
Compare
|
Last failure was an actual upgraed failure (nodes were still upgrading after cluster allegedly reached level = bad). /test e2e-gcp-upgrade |
|
Specifically excluded etcdMemberCommunicationSlow from pending - it is reasonable for it to go pending due to the IO latency caused by the node OS upgrade impacting disk latency impacting etcd network latency (last master upgrades right before upgrade completes causing instantaneous etcd spike, etcd alert has a 5m rate to smooth peaks, we test 1-2m after, we hit the alert). |
|
/test e2e-gcp-upgrade |
23359d3 to
7a1b7f8
Compare
|
/retest |
|
/test e2e-gcp-upgrade |
|
/retest |
2 similar comments
|
/retest |
|
/retest |
7a1b7f8 to
9c4fac8
Compare
This ensures that default queries aggregate results from the running instances (during upgrades) and helps us test invariants like "there is always an alert firing even during upgrades". Note that this makes reconstructing a test more complex because we can no longer exactly reproduce a query (by downloading the prometheus data from a job) but that was already true because we would get round robined to one of the instances and some data is implicitly missing.
9c4fac8 to
cebf276
Compare
|
/test e2e-gcp-upgrade |
cebf276 to
8c16c82
Compare
|
/test e2e-gcp-upgrade Was the pods going back to pending issue |
|
/retest I think this is ready for merge (pending is always flake, we have all the exceptions catalogued with bugs), will push it through |
|
/retest |
|
/retest |
8c16c82 to
28d890b
Compare
It is unacceptable to fire alerts during normal upgrades. Tighten the constraints on the upgrade tests to ensure that any alerts fail the upgrade test. If the test is skipped, continue to report which alerts fired. Test over the entire duration of the test like we do in the post-run variation.
28d890b to
59ef04b
Compare
|
/retest |
|
@smarterclayton: The following tests failed, say
Full PR test history. Your PR dashboard. DetailsInstructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository. I understand the commands that are listed here. |
|
I am going to merge this to start preventing regressions of new alerts. We have all known alerts over the last ~20 or so runs in an exception or fixed. Goodbye alerts during upgrade. |
Since pendingAlertQuery landed in 59ef04b (test: Require no alerts during upgrades, 2021-03-17, openshift#25904), it has been measuring pending alerts firing when the test was one, and the value has always been 1. That would get rendered as: alert ... pending for 1 seconds with labels... regardless of how long the alert had been pending before the query was run. This commit replaces the query with a new one that: * Uses: ALERTS{...} unless ALERTS offset 1s to trigger on edges where the alert began firing. * Uses last_over_time to find the most recent edge trigger. * Uses: time() - last_over_time(time() * ...) to figure out how long ago that most-recent trigger was. * Multiplies by ALERTS again to exclude alerts that are no longer pending by the time the query runs.
Since pendingAlertQuery landed in 59ef04b (test: Require no alerts during upgrades, 2021-03-17, openshift#25904), it has been measuring pending alerts firing when the test was one, and the value has always been 1. That would get rendered as: alert ... pending for 1 seconds with labels... regardless of how long the alert had been pending before the query was run. This commit replaces the query with a new one whose value is actually the number of seconds that a currently-pending alert has been firing. The new query: * Uses: ALERTS{...} unless ALERTS offset 1s to trigger on edges where the alert began firing. * Uses last_over_time to find the most recent edge trigger. * Uses: time() - last_over_time(time() * ...) to figure out how long ago that most-recent trigger was. * Multiplies by ALERTS again to exclude alerts that are no longer pending by the time the query runs.
Since pendingAlertQuery landed in 59ef04b (test: Require no alerts during upgrades, 2021-03-17, openshift#25904), it has been measuring pending alerts firing when the query was run, and the value has always been 1. That would get rendered as: alert ... pending for 1 seconds with labels... regardless of how long the alert had been pending before the query was run. This commit replaces the query with a new one whose value is actually the number of seconds that a currently-pending alert has been firing. The new query: * Uses: ALERTS{...} unless ALERTS offset 1s to trigger on edges where the alert began firing. * Uses last_over_time to find the most recent edge trigger. * Uses: time() - last_over_time(time() * ...) to figure out how long ago that most-recent trigger was. * Multiplies by ALERTS again to exclude alerts that are no longer pending by the time the query runs.
Since pendingAlertQuery landed in 59ef04b (test: Require no alerts during upgrades, 2021-03-17, openshift#25904), it has been measuring pending alerts firing when the query was run, and the value has always been 1. That would get rendered as: alert ... pending for 1 seconds with labels... regardless of how long the alert had been pending before the query was run. This commit replaces the query with a new one whose value is actually the number of seconds that a currently-pending alert has been firing. The new query: * Uses: ALERTS{...} unless ALERTS offset 1s to trigger on edges where the alert began firing. * Uses last_over_time to find the most recent edge trigger. * Uses: time() + 1 - last_over_time(time() * ...) to figure out how long ago that most-recent trigger was. The +1 sets the floor at 1, for cases where one second ago we were not firing, but when the query is run we are firing. * Multiplies by ALERTS again to exclude alerts that are no longer pending by the time the query runs. * Uses sort_desc so we complain first about the alerts that have been pending the longest.
Since pendingAlertQuery landed in 59ef04b (test: Require no alerts during upgrades, 2021-03-17, openshift#25904), it has been measuring pending alerts pending when the query was run, and the value has always been 1. That would get rendered as: alert ... pending for 1 seconds with labels... regardless of how long the alert had been pending before the query was run. This commit replaces the query with a new one whose value is actually the number of seconds that a currently-pending alert has been pending. The new query: * Uses: ALERTS{...} unless ALERTS offset 1s to trigger on edges where the alert began pending. * Uses last_over_time to find the most recent edge trigger. * Uses: time() + 1 - last_over_time(time() * ...) to figure out how long ago that most-recent trigger was. The +1 sets the floor at 1, for cases where one second ago we were not pending, but when the query is run we are pending. * Multiplies by ALERTS again to exclude alerts that are no longer pending by the time the query runs. * Uses sort_desc so we complain first about the alerts that have been pending the longest.
It is unacceptable to fire alerts during normal upgrades. Tighten
the constraints on the upgrade tests to ensure that any alerts
fail the upgrade test. If the test is skipped, continue to report
which alerts fired. Test over the entire duration of the test like
we do in the post-run variation.