- 2024-05-15: The paper got accepted into ACL 2024 main! 🎉
This is the official repository for the paper "Understanding the Effects of Noise in Text-to-SQL: An Examination of the BIRD-Bench Benchmark".
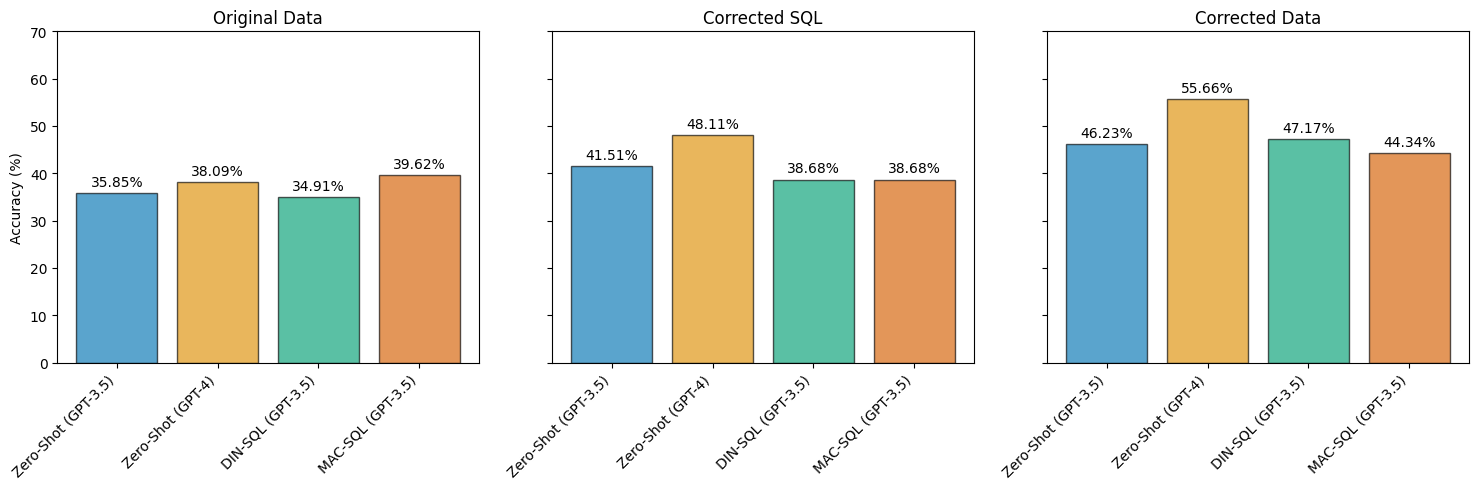
We found that the popular BIRD-Bench text-to-SQL dataset and benchmark contains significant noise in questions and SQL queries, and investigate the effect of noise on model performance. The presence of incorrect gold SQL queries, which then generate incorrect gold answers, has a significant impact on the benchmark's reliability. Surprisingly, when evaluating models on corrected SQL queries, zero-shot baselines surpassed the performance of state-of-the-art prompting methods as can be seen in the above picture. We conclude that informative noise labels and reliable benchmarks are crucial to developing new Text-to-SQL methods that can handle varying types of noise.
As part of the study, we curate three different datasets which can all be found in the /datasets folder based on the identified errors and annotations:
financial.jsonThe original financial domain of BIRD-Bench, which consists of 106 question and SQL query pairs.financial_corrected.jsonA version of the financial domain where noise has been removed from both questions and SQL queries.financial_corrected_sql.jsonA version of the financial domain where only noise in the SQL queries has been removed.
The finalized annotations and corrections agreed upon by the annotators are in the /annotations folder. It includes files for the 106 financial data points and 20 sampled points from each of the other domains (california_schools, superhero, thrombosis_prediction, toxicology) in both Excel and CSV formats. The CSV files can be viewed directly on GitHub. Additionally, there's a UML database schema diagram for the financial domain to aid in understanding the annotations. The annotations where made according to the following categories:
| Category | Annotation |
|---|---|
| Spelling/Syntactical error | 1 |
| Vague/Ambiguous Questions | 2 |
| Incorrect SQL | 3 |
| Synonyms | 4 |
| String Capitalization | 5 |
| Question does not map to DB | 6 |
Statistics over the found noise and errors can be seen in the tables below.
Table 1: Statistics of the total amount of data points that contains errors and the amount of errors in questions and gold queries across five domains.
| Statistic | Financial | California Schools | Superhero | Toxicology | Thrombosis Prediction |
|---|---|---|---|---|---|
| Data points with noise | 52/106 (49%) | 9/20 (45%) | 3/20 (15%) | 7/20 (35%) | 8/20 (40%) |
| Noisy questions | 44/106 (41.5%) | 5/20 (25%) | 2/20 (10%) | 6/20 (30%) | 3/20 (15%) |
| Erroneous gold queries | 22/106 (20.7%) | 8/20 (40%) | 1/20 (5%) | 2/20 (10%) | 6/20 (30%) |
| Noise Type | Financial | California Schools | Superhero | Toxicology | Thrombosis Prediction |
|---|---|---|---|---|---|
| Spelling/Syntactical Errors | 23 | 2 | 1 | 4 | 2 |
| Vague/Ambiguous Questions | 17 | 1 | 1 | 1 | 1 |
| Incorrect SQL | 22 | 8 | 1 | 2 | 6 |
| Synonyms | 2 | 0 | 0 | 0 | 0 |
| String Capitalization | 7 | 0 | 0 | 0 | 0 |
| Question does not map to DB | 1 | 4 | 1 | 0 | 0 |
| Total number of errors | 72 | 15 | 4 | 7 | 9 |
Install the dependencies:
pip install -r requirements.txt
Set the OPENAI_API_KEY environment variable:
export OPENAI_API_KEY="YOUR_OPENAI_API_KEY"
Only implementations of the zero-shot model and the DIN-SQL model used in the experiments can be found in this repository. For the MAC-SQL model, we instead refer to the models own repository which can be found here, and the datasets found in the /datasets folder.
Use the following command format to run a model:
python run_model.py [--model MODEL_NAME] [--dataset DATASET_NAME] [--llm LLM_NAME]
--modelsets which of the two models to use. The available options arezero_shotanddin_sql--datasetsets which of the datasets to use. The available options arefinancial,financial_correctedandfinancial_corrected_sql--llmsets which of the openAI LLMs to use. See here for the available models.
Bibtex:
@misc{wretblad2024understanding,
title={Understanding the Effects of Noise in Text-to-SQL: An Examination of the BIRD-Bench Benchmark},
author={Niklas Wretblad and Fredrik Gordh Riseby and Rahul Biswas and Amin Ahmadi and Oskar Holmström},
year={2024},
eprint={2402.12243},
archivePrefix={arXiv},
primaryClass={cs.CL}
}