MSM tuning for high core count #227
Conversation
|
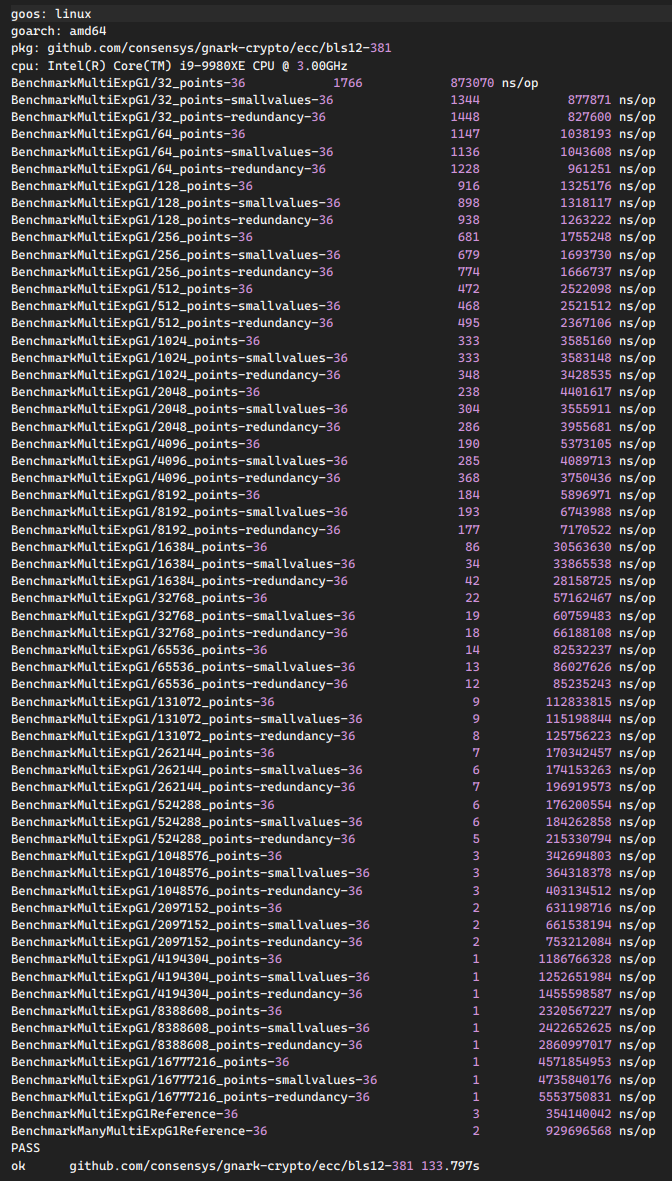
After bf04281 References BLS12-381Gnark
Gnark has a performance issue between 8192 and 16384 points and is likely changing strategy to something that is not effective on 18 cores. cc @yelhousni @gbotrel blstrs
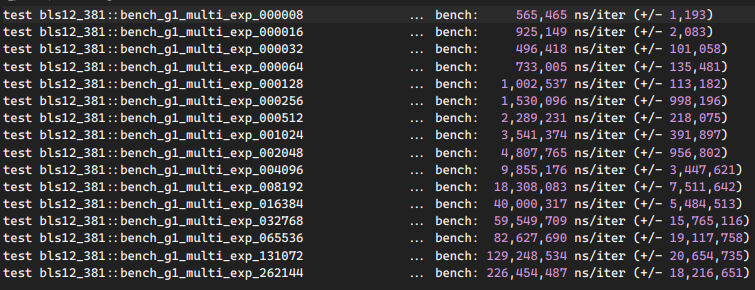
BLST multithreading doesn't scale to high-core count and for example is 2.39x slower for 65536 (2^16) inputs Bellman
Constantine is 5.22x faster than Bellman (Zcash backend) BN-254 SnarksConstantine
Gnark
Constantine is 3.18x faster than Gnark at 65536 inputs. Bellman CE
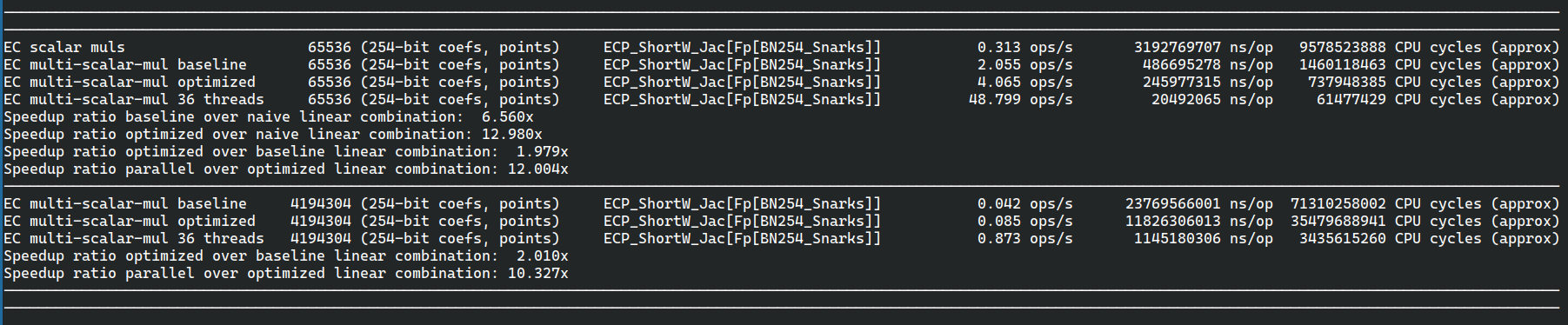
Constantine is 1.35x faster than Bellman CE barretenbergBarretenberg 65536 points Barretenberg is about ~25% faster on 18 cores Barretenberg 4194304 points
Barrentenberg is about ~23% faster |


…e scoped barriers
|
53ae971 adds reentrancy / nested parallelism. Some parallel sections used
The new barrier improves performance by 15% to 50% Perf before
Perf after |
|
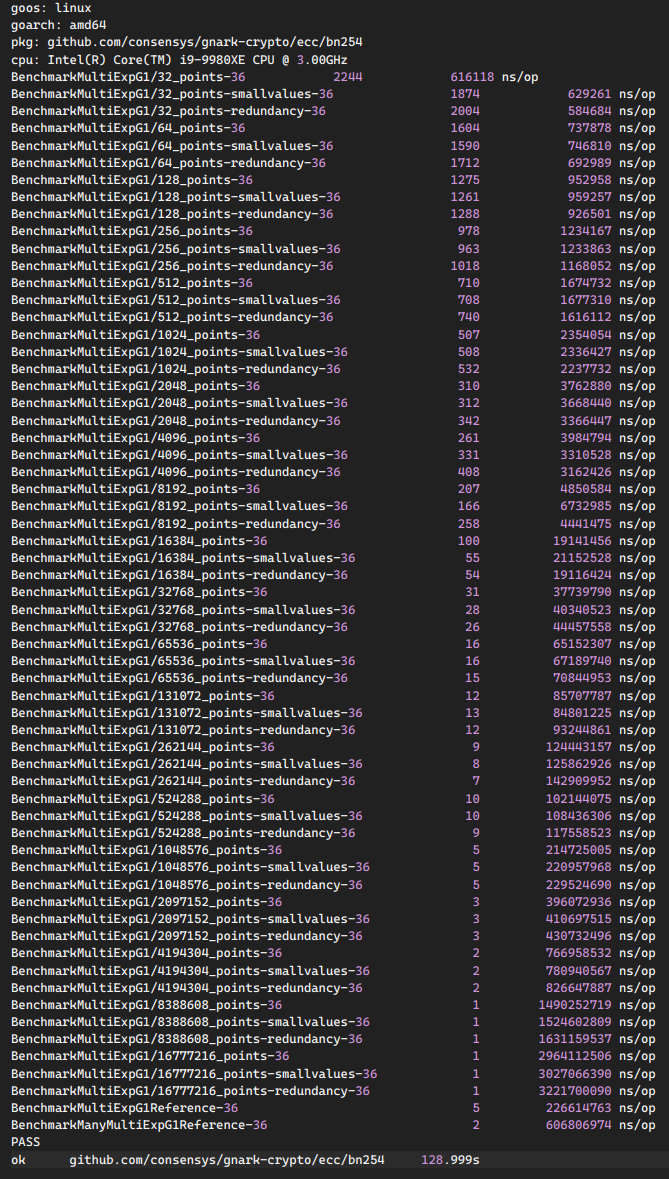
Rebench on BN254-Snarks
Now 50% faster / better CPU usage and 1% faster than Gnark ¯\_(ツ)_/¯ and 22.59% faster than Barretenberg. No change though. |
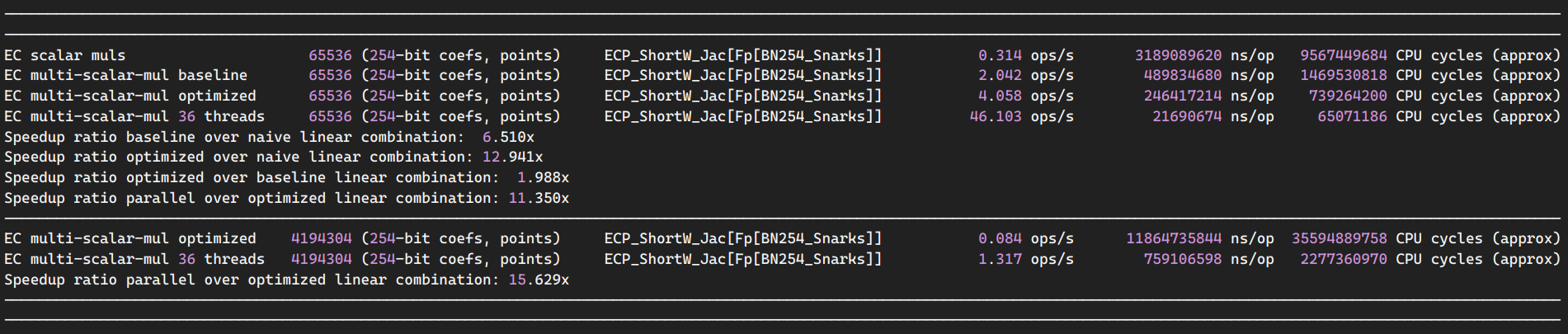
|
10% faster by increasing collision queue depth
|
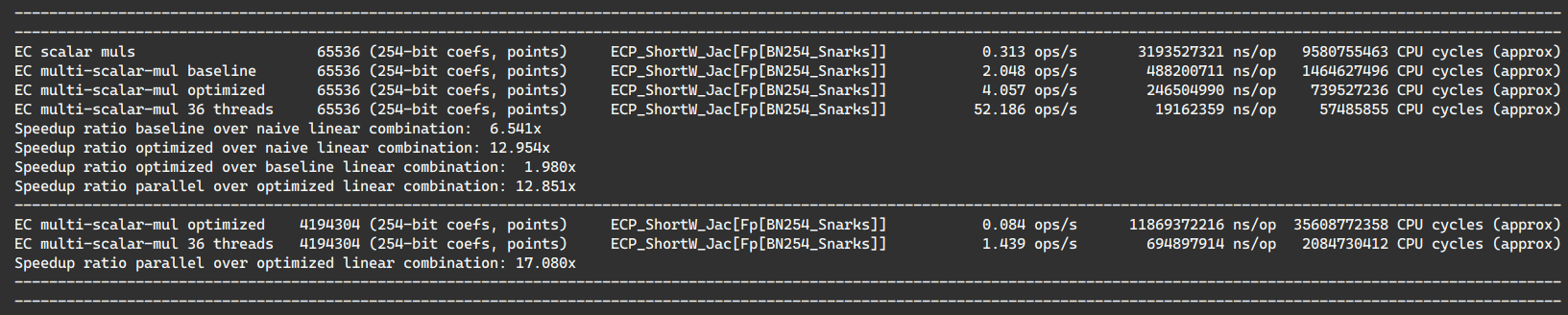
This PR optimizes multi-scalar-multiplication for machines with a high-core-count.
On a i9-9980XE (Skylake X, 18 cores, overclocked and liquid-cooled all-clocked turbo 4.1GHz)
Features
Reentrancy / nested parallelism: A new precise barrier
syncScopehas been introduced to the threadpool.Contrary to
syncAllwhich can only be called in the root thread and so prevents nested parallelism,syncScopecan be called from any thread. Hence parallel MSM and parallel sum reductions / batch additions can be called from within other parallel function, for example a ZK prover that needs to schedule multiple parallel MSMs in parallel.Bug fix
The parallel speedup bench reported the perf ratio of the last iteration instead of the average of all iterations.
Given that most of Constantine is constant-time and the CPU was primed/hot, there were few variations but still ...
Before
After
Observations
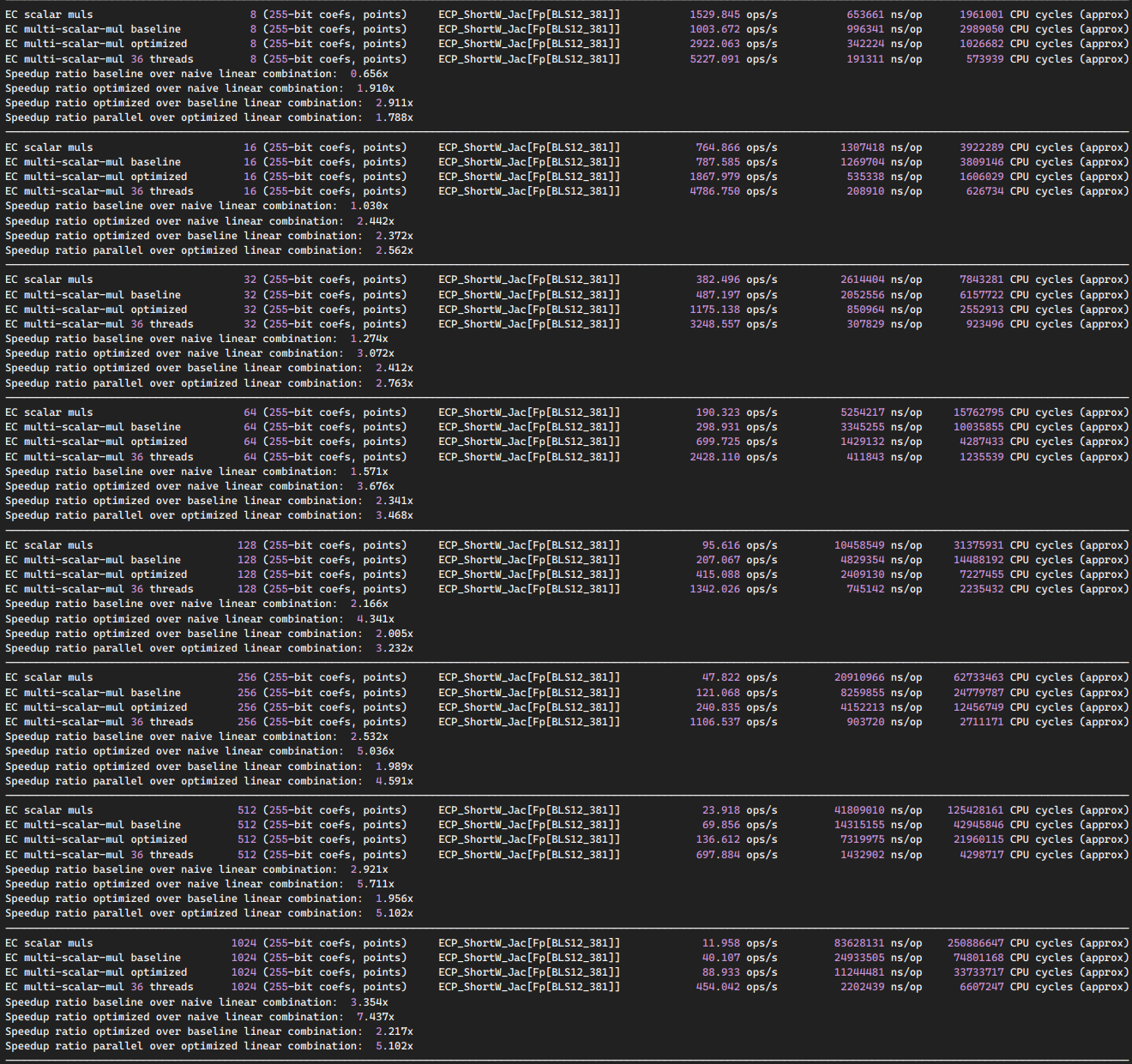
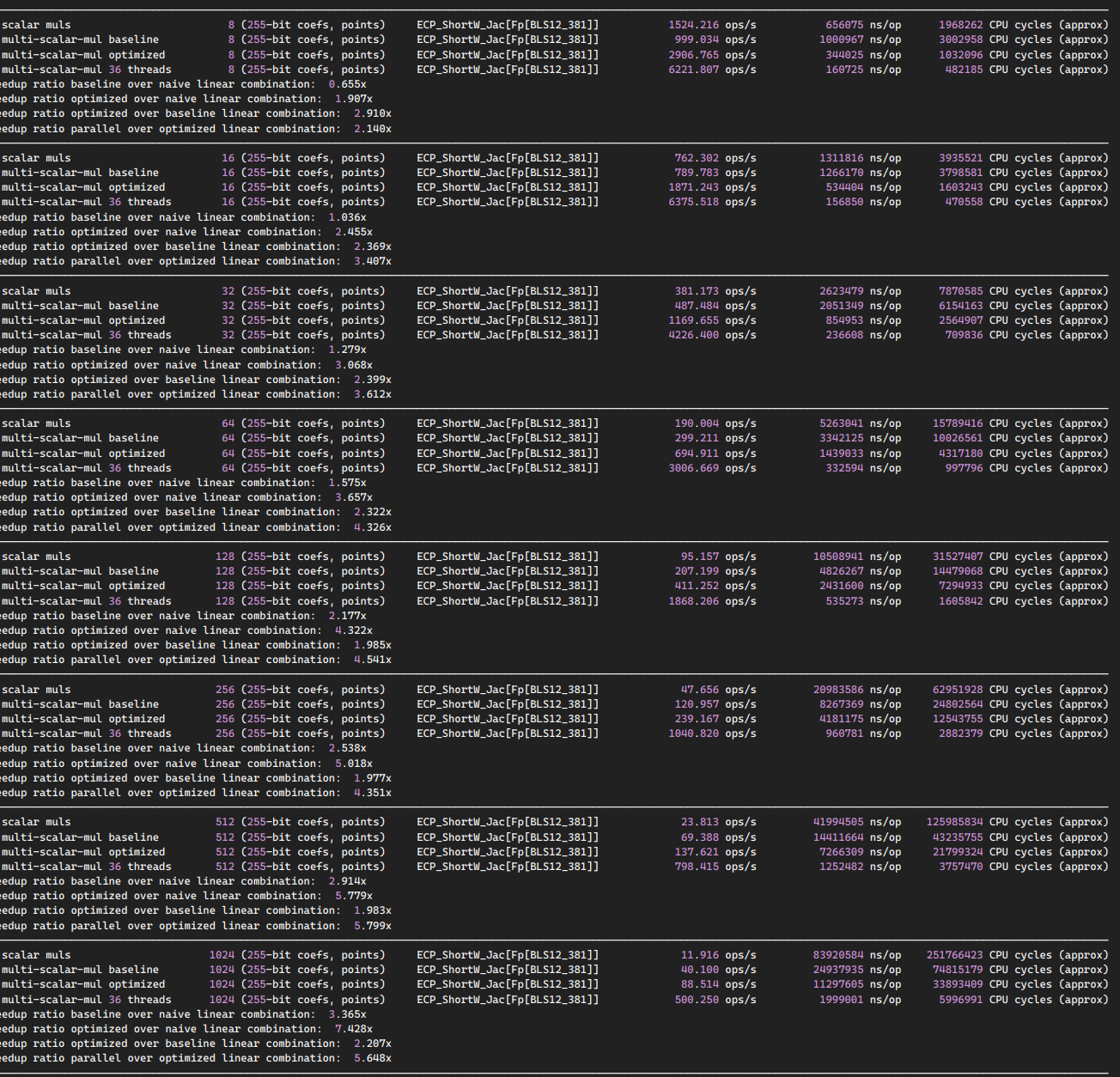
Starting from 512 and up, we have a 50% to 150% perf improvement to core utilization (yes 2.5x). Note that somehow on 8 cores, the previous 512 strategy was displaying over 7x speedup while the new strategy only provides 5.5x. We make the choice of privileging scaling on high core count.
At the top range of our bench 262144 inputs (2^18) the multithreading speedup is over 15x instead of just 11x as previously.
We might reach the limit of Amdahl's Law and might need algorithm refactoring if we want to go further as the serial reductions might be a bottleneck for further parallelism.