面试问题:
分析原因
1、查看sql是否涉及多表的联表或者子查询,如果有,看是否能进行业务拆分,相关字段冗余或者合并成临时表(业务和算法的优化)
2、涉及链表的查询,是否能进行分表查询,单表查询之后的结果进行字段整合
3、如果以上两种都不能操作,非要链表查询,那么考虑对相对应的查询条件做索引。加快查询速度
4、针对数量大的表进行历史表分离(如交易流水表)
5、数据库主从分离,读写分离,降低读写针对同一表同时的压力,至于主从同步,mysql有自带的binlog实现 主从同步
6、explain分析sql语句,查看执行计划,分析索引是否用上,分析扫描行数等等
7、查看mysql执行日志,看看是否有其他方面的问题
①增加缓冲,记录已读取的内容。
继承HttpServletRequestWrapper 类
public class RepeatedlyReadRequestWrapper extends HttpServletRequestWrapper {
private final byte[] body;
public RepeatedlyReadRequestWrapper(HttpServletRequest request)
throws IOException {
super(request);
body = readBytes(request.getReader(), "utf-8");
}
@Override
public BufferedReader getReader() throws IOException {
return new BufferedReader(new InputStreamReader(getInputStream()));
}
@Override
public ServletInputStream getInputStream() throws IOException {
final ByteArrayInputStream bais = new ByteArrayInputStream(body);
return new ServletInputStream() {
@Override
public boolean isFinished() {
return false;
}
@Override
public boolean isReady() {
return false;
}
@Override
public void setReadListener(ReadListener listener) {
}
@Override
public int read() throws IOException {
return bais.read();
}
};
}
private byte[] readBytes(BufferedReader br,String encoding) throws IOException{
String str = null,retStr="";
while ((str = br.readLine()) != null) {
retStr += str;
}
if (StringUtils.isNotBlank(retStr)) {
return retStr.getBytes(Charset.forName(encoding));
}
return null;
}运行时内存
在JDK8,元空间的前身Perm区已经被淘汰,在JDK7及之前的版本中,只有Hotspot才有Perm区(永久代),它在启动时固定大小,很难进行调优,并且Full GC时会移动类元信息
在某些场景下,如果动态加载类过多,容易产生Perm区的OOM. 比如某个实际Web工程中,因为功能点比较多,在运行过程中,要不断动态加载很多的类,经常出现致命错误:
| 1 | Exception in thread ‘dubbo client x.x connector' java.lang.OutOfMemoryError: PermGenspac |
|---|
为解决该问题,需要设定运行参数
| 1 | -XX:MaxPermSize= l280m |
|---|
JDK8使用元空间替换永久代.区别于永久代,元空间在本地内存中分配. 也就是说,只要本地内存足够,它不会出现像永久代中java.lang.OutOfMemoryError: PermGen space
顺便说一句:序列化机制只保存对象的类型信息,属性的类型信息和属性值。如果说是换一个static变量,这个变量是保存在方法区的,是不会序列化的。
查看原因是因为jvm内存超了,问那种情况会导致超内存,此时程序中无使用多线程或者递归之类的方法。这个地方考虑“堆外内存”这个概念以及会出现的“堆外内存”的情况
ublic void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
StartupStep contextRefresh = this.applicationStartup.start("spring.context.refresh");
// Prepare this context for refreshing.
//为刷新准备上下文。
prepareRefresh();
// Tell the subclass to refresh the internal bean factory.
//告诉子类刷新内部bean工厂。
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
//准备bean工厂在此上下文中使用。
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
//允许在context子类中对bean工厂进行后处理。
postProcessBeanFactory(beanFactory);
StartupStep beanPostProcess = this.applicationStartup.start("spring.context.beans.post-process");
// Invoke factory processors registered as beans in the context.
//调用在上下文中注册为bean的工厂处理器
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
//注册拦截bean创建的bean处理器。
registerBeanPostProcessors(beanFactory);
beanPostProcess.end();
// Initialize message source for this context.
//初始化消息源
initMessageSource();
// Initialize event multicaster for this context.
//初始化该上下文事件的多触发器。
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
//初始化特定上下文子类中的其他特殊bean。
onRefresh();
// Check for listener beans and register them.
//检查监听bean并注册它们
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
//实例化所有剩余的(非lazy-init)单例。
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
//最后一步:发布相应的事件。
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
// Destroy already created singletons to avoid dangling resources.
//销毁已经创建的单例以避免资源悬空。
destroyBeans();
// Reset 'active' flag.
//重置'active'标志。
cancelRefresh(ex);
// Propagate exception to caller.
//向调用者传播异常。
throw ex;
}
finally {
// Reset common introspection caches in Spring's core, since we
// might not ever need metadata for singleton beans anymore...
//在Spring的核心中重置公共内省缓存,因为我们可能再也不需要单例bean的元数据了。
resetCommonCaches();
contextRefresh.end();
}
}
}.interview-lesson/interview-3/%E9%9D%A2%E8%AF%95%E9%97%AE%E9%A2%98.assets/webp.webp)
MQ消息、DB操作一致性方案:
1)发送消息到MQ服务器,此时消息状态为SEND_OK。此消息为consumer不可见。
2)执行DB操作;DB执行成功Commit DB操作,DB执行失败Rollback DB操作。
3)如果DB执行成功,回复MQ服务器,将状态为COMMIT_MESSAGE;如果DB执行失败,回复MQ服务器,将状态改为ROLLBACK_MESSAGE。注意此过程有可能失败。
4)MQ内部提供一个名为“事务状态服务”的服务,此服务会检查事务消息的状态,如果发现消息未COMMIT,则通过Producer启动时注册的TransactionCheckListener来回调业务系统,业务系统在checkLocalTransactionState方法中检查DB事务状态,如果成功,则回复COMMIT_MESSAGE,否则回复ROLLBACK_MESSAGE。
首先是rocketmq集群架构图:

首先是消息文件存储目录结构
-
目录内容解读: 每个broker的所有数据都存储在一个根目录下,自包含 abort文件是一个空文件占位锁,用来判定上次是否正常退出 checkpoint文件是记录刷盘进度和时间,用来重启时恢复数据 config目录存储的是配置元数据,broker配置,消费进度,topic和订阅关系等数据,确保broker可以没有外部依赖独立运行。 commitlog存储完整的消息数据,类似wal (write-ahead logging)机制,只要刷盘就可以确保消息不丢,每个文件1G,以起始offset命名文件,每个消息都对应一个long型的位置信息(physicOffset),方便快速定位消息。 consumequeue保存的是索引数据,每个消息只有20个字节,其中有8个字节指向commitlog的physicOffset,对应一个位置信息(logicOffset)。 总结 : commitlog保证了写入的顺序性和高性能,低延时,consumequeue非常轻量级,所以一个broker可以支持上万个topic和queue。
下图是消息存储模型

commitLog Offset:8 byte
size:4 Byte
Message Tag HashCode: 8 Byte
rocketmq消息索引存储模型
RocketMQ文件存储模型层次结构

结合自己项目说说
-
线程数计算公式为:
Nthreads=NcpuUcpu(1+w/c) =Ncpu*(1+w/c)。
其中 Nthreads:线程数;Ncpu:处理器核心数;Ucpu:处理器的使用百分比;W/C:等待时间与计算时间的比率
一般来说,直接CPU内核树*1.5就行
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}构造方法中的字段含义如下:
-
corePoolSize:核心线程数量,当有新任务在execute()方法提交时,会执行以下判断:
-
- 如果运行的线程少于 corePoolSize,则创建新线程来处理任务,即使线程池中的其他线程是空闲的;
- 如果线程池中的线程数量大于等于 corePoolSize 且小于 maximumPoolSize,则只有当workQueue满时才创建新的线程去处理任务;
- 如果设置的corePoolSize 和 maximumPoolSize相同,则创建的线程池的大小是固定的,这时如果有新任务提交,若workQueue未满,则将请求放入workQueue中,等待有空闲的线程去从workQueue中取任务并处理;
- 如果运行的线程数量大于等于maximumPoolSize,这时如果workQueue已经满了,则通过handler所指定的策略来处理任务;
所以,任务提交时,判断的顺序为 corePoolSize –> workQueue –> maximumPoolSize。
-
maximumPoolSize:最大线程数量;
-
workQueue:等待队列,当任务提交时,如果线程池中的线程数量大于等于corePoolSize的时候,把该任务封装成一个Worker对象放入等待队列;
-
workQueue:保存等待执行的任务的阻塞队列,当提交一个新的任务到线程池以后, 线程池会根据当前线程池中正在运行着的线程的数量来决定对该任务的处理方式,主要有以下几种处理方式:
-
- 直接切换:这种方式常用的队列是SynchronousQueue,但现在还没有研究过该队列,这里暂时还没法介绍;
- 使用无界队列:一般使用基于链表的阻塞队列LinkedBlockingQueue。如果使用这种方式,那么线程池中能够创建的最大线程数就是corePoolSize,而maximumPoolSize就不会起作用了(后面也会说到)。当线程池中所有的核心线程都是RUNNING状态时,这时一个新的任务提交就会放入等待队列中。
- 使用有界队列:一般使用ArrayBlockingQueue。使用该方式可以将线程池的最大线程数量限制为maximumPoolSize,这样能够降低资源的消耗,但同时这种方式也使得线程池对线程的调度变得更困难,因为线程池和队列的容量都是有限的值,所以要想使线程池处理任务的吞吐率达到一个相对合理的范围,又想使线程调度相对简单,并且还要尽可能的降低线程池对资源的消耗,就需要合理的设置这两个数量。
-
-
- 如果要想降低系统资源的消耗(包括CPU的使用率,操作系统资源的消耗,上下文环境切换的开销等), 可以设置较大的队列容量和较小的线程池容量, 但这样也会降低线程处理任务的吞吐量。
- 如果提交的任务经常发生阻塞,那么可以考虑通过调用 setMaximumPoolSize() 方法来重新设定线程池的容量。
- 如果队列的容量设置的较小,通常需要将线程池的容量设置大一点,这样CPU的使用率会相对的高一些。但如果线程池的容量设置的过大,则在提交的任务数量太多的情况下,并发量会增加,那么线程之间的调度就是一个要考虑的问题,因为这样反而有可能降低处理任务的吞吐量。
-
-
keepAliveTime:线程池维护线程所允许的空闲时间。当线程池中的线程数量大于corePoolSize的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了keepAliveTime;
-
threadFactory:它是ThreadFactory类型的变量,用来创建新线程。默认使用Executors.defaultThreadFactory() 来创建线程。使用默认的ThreadFactory来创建线程时,会使新创建的线程具有相同的NORM_PRIORITY优先级并且是非守护线程,同时也设置了线程的名称。
-
handler:它是RejectedExecutionHandler类型的变量,表示线程池的饱和策略。如果阻塞队列满了并且没有空闲的线程,这时如果继续提交任务,就需要采取一种策略处理该任务。线程池提供了4种策略:
-
- AbortPolicy:直接抛出异常,这是默认策略;
- CallerRunsPolicy:用调用者所在的线程来执行任务;
- DiscardOldestPolicy:丢弃阻塞队列中靠最前的任务,并执行当前任务;
- DiscardPolicy:直接丢弃任务;
- 自定义方法,
redis的高并发的原因: 1)绝大部分请求是内存操作,非常快速 2)单线程,避免了不必要的上下文切换 3)IO内部实现采用linux系统调用epoll,利用epoll的多路复用特性,绝不在io上浪费一点时间。 epoll epoll是Linux下多路复用IO接口select/poll的增强版本,它能显著提高程序在大量并发连接中只有少量活跃的情况下的系统CPU利用率。 1)epoll 没有最大并发连接的限制,上限是最大可以打开文件的数目;epoll的连接数,可以通过文件查看 /proc/sys/fs/file-max。早期的系统调用select有大小限制(FD_SETSIZE,通常为1024) 2)效率提升, 事件通知方式为每当fd就绪,系统注册的回调函数就会被调用,将就绪fd放到readyList里面,时间复杂度O(1)。它只管你“活跃”的连接 ,而跟连接总数无关。而select/pool需要遍历或传递全量的fd,时间复杂度为O(n)。 3)内存拷贝, Epoll 使用了“共享内存 ”。
https://blog.csdn.net/weixin_34138192/article/details/113537698
Redis 是一个事件驱动的内存数据库,服务器需要处理两种类型的事件。
-
文件事件
Redis 服务器通过 socket 实现与客户端(或其他redis服务器)的交互,文件事件就是服务器对 socket 操作的抽象
-
时间事件
Reids 有很多操作需要在给定的时间点进行处理,时间事件就是对这类定时任务的抽象
Redis 基于 Reactor 模式开发了自己的事件处理器。如下图

注:reactor是什么:
reactor式是一种事件处理模式,用于处理由一个或多个输入并发交付给服务处理程序的服务请求。 然后,服务处理程序将传入的请求解复用,并将它们同步地分派给相关的请求处理程序。
- 事件驱动(event handling)
- 可以处理一个或多个输入源(one or more inputs)
- 通过Service Handler同步的将输入事件(Event)采用多路复用分发给相应的Request Handler(多个)处理
https://www.pdai.tech/md/db/nosql-redis/db-redis-x-copy.html
注意:在2.8版本之前只有全量复制,而2.8版本后有全量和增量复制:
全量(同步)复制:比如第一次同步时增量(同步)复制:只会把主从库网络断连期间主库收到的命令,同步给从库
确立主从关系
例如,现在有实例 1(ip:172.16.19.3)和实例 2(ip:172.16.19.5),我们在实例 2 上执行以下这个命令后,实例 2 就变成了实例 1 的从库,并从实例 1 上复制数据:
replicaof 172.16.19.3 6379- 全量复制的三个阶段

第一阶段是主从库间建立连接、协商同步的过程,主要是为全量复制做准备。在这一步,从库和主库建立起连接,并告诉主库即将进行同步,主库确认回复后,主从库间就可以开始同步了。
具体来说,从库给主库发送 psync 命令,表示要进行数据同步,主库根据这个命令的参数来启动复制。psync 命令包含了主库的 runID 和复制进度 offset 两个参数。runID,是每个 Redis 实例启动时都会自动生成的一个随机 ID,用来唯一标记这个实例。当从库和主库第一次复制时,因为不知道主库的 runID,所以将 runID 设为“?”。offset,此时设为 -1,表示第一次复制。主库收到 psync 命令后,会用 FULLRESYNC 响应命令带上两个参数:主库 runID 和主库目前的复制进度 offset,返回给从库。从库收到响应后,会记录下这两个参数。这里有个地方需要注意,FULLRESYNC 响应表示第一次复制采用的全量复制,也就是说,主库会把当前所有的数据都复制给从库。
第二阶段,主库将所有数据同步给从库。从库收到数据后,在本地完成数据加载。这个过程依赖于内存快照生成的 RDB 文件。
具体来说,主库执行 bgsave 命令,生成 RDB 文件,接着将文件发给从库。从库接收到 RDB 文件后,会先清空当前数据库,然后加载 RDB 文件。这是因为从库在通过 replicaof 命令开始和主库同步前,可能保存了其他数据。为了避免之前数据的影响,从库需要先把当前数据库清空。在主库将数据同步给从库的过程中,主库不会被阻塞,仍然可以正常接收请求。否则,Redis 的服务就被中断了。但是,这些请求中的写操作并没有记录到刚刚生成的 RDB 文件中。为了保证主从库的数据一致性,主库会在内存中用专门的 replication buffer,记录 RDB 文件生成后收到的所有写操作。
第三个阶段,主库会把第二阶段执行过程中新收到的写命令,再发送给从库。具体的操作是,当主库完成 RDB 文件发送后,就会把此时 replication buffer 中的修改操作发给从库,从库再重新执行这些操作。这样一来,主从库就实现同步了。
增量复制
在 Redis 2.8 版本引入了增量复制。
- 为什么会设计增量复制?
如果主从库在命令传播时出现了网络闪断,那么,从库就会和主库重新进行一次全量复制,开销非常大。从 Redis 2.8 开始,网络断了之后,主从库会采用增量复制的方式继续同步。
- 增量复制的流程
如图

先看两个概念: replication buffer 和 repl_backlog_buffer
repl_backlog_buffer:它是为了从库断开之后,如何找到主从差异数据而设计的环形缓冲区,从而避免全量复制带来的性能开销。如果从库断开时间太久,repl_backlog_buffer环形缓冲区被主库的写命令覆盖了,那么从库连上主库后只能乖乖地进行一次全量复制,所以repl_backlog_buffer配置尽量大一些,可以降低主从断开后全量复制的概率。而在repl_backlog_buffer中找主从差异的数据后,如何发给从库呢?这就用到了replication buffer。
replication buffer:Redis和客户端通信也好,和从库通信也好,Redis都需要给分配一个 内存buffer进行数据交互,客户端是一个client,从库也是一个client,我们每个client连上Redis后,Redis都会分配一个client buffer,所有数据交互都是通过这个buffer进行的:Redis先把数据写到这个buffer中,然后再把buffer中的数据发到client socket中再通过网络发送出去,这样就完成了数据交互。所以主从在增量同步时,从库作为一个client,也会分配一个buffer,只不过这个buffer专门用来传播用户的写命令到从库,保证主从数据一致,我们通常把它叫做replication buffer。
- 如果在网络断开期间,repl_backlog_size环形缓冲区写满之后,从库是会丢失掉那部分被覆盖掉的数据,还是直接进行全量复制呢?
对于这个问题来说,有两个关键点:
- 一个从库如果和主库断连时间过长,造成它在主库repl_backlog_buffer的slave_repl_offset位置上的数据已经被覆盖掉了,此时从库和主库间将进行全量复制。
- 每个从库会记录自己的slave_repl_offset,每个从库的复制进度也不一定相同。在和主库重连进行恢复时,从库会通过psync命令把自己记录的slave_repl_offset发给主库,主库会根据从库各自的复制进度,来决定这个从库可以进行增量复制,还是全量复制。
更深入理解
我们通过几个问题来深入理解主从复制。
¶ 当主服务器不进行持久化时复制的安全性
在进行主从复制设置时,强烈建议在主服务器上开启持久化,当不能这么做时,比如考虑到延迟的问题,应该将实例配置为避免自动重启。
为什么不持久化的主服务器自动重启非常危险呢?为了更好的理解这个问题,看下面这个失败的例子,其中主服务器和从服务器中数据库都被删除了。
- 我们设置节点A为主服务器,关闭持久化,节点B和C从节点A复制数据。
- 这时出现了一个崩溃,但Redis具有自动重启系统,重启了进程,因为关闭了持久化,节点重启后只有一个空的数据集。
- 节点B和C从节点A进行复制,现在节点A是空的,所以节点B和C上的复制数据也会被删除。
- 当在高可用系统中使用Redis Sentinel,关闭了主服务器的持久化,并且允许自动重启,这种情况是很危险的。比如主服务器可能在很短的时间就完成了重启,以至于Sentinel都无法检测到这次失败,那么上面说的这种失败的情况就发生了。
如果数据比较重要,并且在使用主从复制时关闭了主服务器持久化功能的场景中,都应该禁止实例自动重启。
¶ 为什么主从全量复制使用RDB而不使用AOF?
1、RDB文件内容是经过压缩的二进制数据(不同数据类型数据做了针对性优化),文件很小。而AOF文件记录的是每一次写操作的命令,写操作越多文件会变得很大,其中还包括很多对同一个key的多次冗余操作。在主从全量数据同步时,传输RDB文件可以尽量降低对主库机器网络带宽的消耗,从库在加载RDB文件时,一是文件小,读取整个文件的速度会很快,二是因为RDB文件存储的都是二进制数据,从库直接按照RDB协议解析还原数据即可,速度会非常快,而AOF需要依次重放每个写命令,这个过程会经历冗长的处理逻辑,恢复速度相比RDB会慢得多,所以使用RDB进行主从全量复制的成本最低。
2、假设要使用AOF做全量复制,意味着必须打开AOF功能,打开AOF就要选择文件刷盘的策略,选择不当会严重影响Redis性能。而RDB只有在需要定时备份和主从全量复制数据时才会触发生成一次快照。而在很多丢失数据不敏感的业务场景,其实是不需要开启AOF的。
¶ 为什么还有无磁盘复制模式?
Redis 默认是磁盘复制,但是如果使用比较低速的磁盘,这种操作会给主服务器带来较大的压力。Redis从2.8.18版本开始尝试支持无磁盘的复制。使用这种设置时,子进程直接将RDB通过网络发送给从服务器,不使用磁盘作为中间存储。
无磁盘复制模式:master创建一个新进程直接dump RDB到slave的socket,不经过主进程,不经过硬盘。适用于disk较慢,并且网络较快的时候。
使用repl-diskless-sync配置参数来启动无磁盘复制。
使用repl-diskless-sync-delay 参数来配置传输开始的延迟时间;master等待一个repl-diskless-sync-delay的秒数,如果没slave来的话,就直接传,后来的得排队等了; 否则就可以一起传。
¶ 为什么还会有从库的从库的设计?
通过分析主从库间第一次数据同步的过程,你可以看到,一次全量复制中,对于主库来说,需要完成两个耗时的操作:生成 RDB 文件和传输 RDB 文件。
如果从库数量很多,而且都要和主库进行全量复制的话,就会导致主库忙于 fork 子进程生成 RDB 文件,进行数据全量复制。fork 这个操作会阻塞主线程处理正常请求,从而导致主库响应应用程序的请求速度变慢。此外,传输 RDB 文件也会占用主库的网络带宽,同样会给主库的资源使用带来压力。那么,有没有好的解决方法可以分担主库压力呢?
其实是有的,这就是“主 - 从 - 从”模式。
在刚才介绍的主从库模式中,所有的从库都是和主库连接,所有的全量复制也都是和主库进行的。现在,我们可以通过“主 - 从 - 从”模式将主库生成 RDB 和传输 RDB 的压力,以级联的方式分散到从库上。
简单来说,我们在部署主从集群的时候,可以手动选择一个从库(比如选择内存资源配置较高的从库),用于级联其他的从库。然后,我们可以再选择一些从库(例如三分之一的从库),在这些从库上执行如下命令,让它们和刚才所选的从库,建立起主从关系。
replicaof 所选从库的IP 6379这样一来,这些从库就会知道,在进行同步时,不用再和主库进行交互了,只要和级联的从库进行写操作同步就行了,这就可以减轻主库上的压力,如下图所示:

级联的“主-从-从”模式好了,到这里,我们了解了主从库间通过全量复制实现数据同步的过程,以及通过“主 - 从 - 从”模式分担主库压力的方式。那么,一旦主从库完成了全量复制,它们之间就会一直维护一个网络连接,主库会通过这个连接将后续陆续收到的命令操作再同步给从库,这个过程也称为基于长连接的命令传播,可以避免频繁建立连接的开销。
¶ 读写分离及其中的问题
在主从复制基础上实现的读写分离,可以实现Redis的读负载均衡:由主节点提供写服务,由一个或多个从节点提供读服务(多个从节点既可以提高数据冗余程度,也可以最大化读负载能力);在读负载较大的应用场景下,可以大大提高Redis服务器的并发量。下面介绍在使用Redis读写分离时,需要注意的问题。
- 延迟与不一致问题
前面已经讲到,由于主从复制的命令传播是异步的,延迟与数据的不一致不可避免。如果应用对数据不一致的接受程度程度较低,可能的优化措施包括:优化主从节点之间的网络环境(如在同机房部署);监控主从节点延迟(通过offset)判断,如果从节点延迟过大,通知应用不再通过该从节点读取数据;使用集群同时扩展写负载和读负载等。
在命令传播阶段以外的其他情况下,从节点的数据不一致可能更加严重,例如连接在数据同步阶段,或从节点失去与主节点的连接时等。从节点的slave-serve-stale-data参数便与此有关:它控制这种情况下从节点的表现;如果为yes(默认值),则从节点仍能够响应客户端的命令,如果为no,则从节点只能响应info、slaveof等少数命令。该参数的设置与应用对数据一致性的要求有关;如果对数据一致性要求很高,则应设置为no。
- 数据过期问题
在单机版Redis中,存在两种删除策略:
惰性删除:服务器不会主动删除数据,只有当客户端查询某个数据时,服务器判断该数据是否过期,如果过期则删除。定期删除:服务器执行定时任务删除过期数据,但是考虑到内存和CPU的折中(删除会释放内存,但是频繁的删除操作对CPU不友好),该删除的频率和执行时间都受到了限制。
在主从复制场景下,为了主从节点的数据一致性,从节点不会主动删除数据,而是由主节点控制从节点中过期数据的删除。由于主节点的惰性删除和定期删除策略,都不能保证主节点及时对过期数据执行删除操作,因此,当客户端通过Redis从节点读取数据时,很容易读取到已经过期的数据。
Redis 3.2中,从节点在读取数据时,增加了对数据是否过期的判断:如果该数据已过期,则不返回给客户端;将Redis升级到3.2可以解决数据过期问题。
- 故障切换问题
在没有使用哨兵的读写分离场景下,应用针对读和写分别连接不同的Redis节点;当主节点或从节点出现问题而发生更改时,需要及时修改应用程序读写Redis数据的连接;连接的切换可以手动进行,或者自己写监控程序进行切换,但前者响应慢、容易出错,后者实现复杂,成本都不算低。
- 总结
在使用读写分离之前,可以考虑其他方法增加Redis的读负载能力:如尽量优化主节点(减少慢查询、减少持久化等其他情况带来的阻塞等)提高负载能力;使用Redis集群同时提高读负载能力和写负载能力等。如果使用读写分离,可以使用哨兵,使主从节点的故障切换尽可能自动化,并减少对应用程序的侵入。
也就是一堆方案吧,也就网上的那一堆案例,生产上除非是参与到了搭建,否则我也不知道是怎么搭建的。
gossip协议
Gossip 过程是由种子节点发起,当一个种子节点有状态需要更新到网络中的其他节点时,它会随机的选择周围几个节点散播消息,收到消息的节点也会重复该过程,直至最终网络中所有的节点都收到了消息。这个过程可能需要一定的时间,由于不能保证某个时刻所有节点都收到消息,但是理论上最终所有节点都会收到消息,因此它是一个最终一致性协议
说自己项目中redis使用的是什么模式,有集群模式,有哨兵模式,还有最新的codis模式
https://developer.aliyun.com/article/603324 三种架构的对比
Redis 中采用了以下两种方式实现高可用:
- 主从复制;
- 采用Sentinel机制监控节点的运行情况,一旦主节点出现问题将由从节点顶上继续提供服务,也就是哨兵模式
官方推荐的最大节点数量为 1000 个左右,这是因为当集群规模过大时,Gossip 协议的效率会显著下降,通信成本剧增。
Redis 集群实现的基础是分片
槽点有16384 个。原因如下:
Redis 集群有 16384 个哈希槽,每个 key 通过 CRC16 算法计算的结果,对 16384 取模后放到对应的编号在 0-16383 之间的哈希槽,集群的每个节点负责一部分哈希槽
Redis的槽是用来干嘛的 之前一直以为是存数据的,不是。 简单来说就是用来索引的(有点像数据库的索引),计算出的槽位号,比如,get 一个key,计算出key的槽位号为500,如果这个槽位(500)刚好是由A节点管理的,那这个key所对应的value就在A节点上存着。
哨兵是作为一个监视者的角色,自己不参与选举。
Sentinel 使用的算法核心是 Raft 算法
通过发送命令, 让Redis服务器返回相关信息,从而监控其运行状态, 包括主服务器和从服务器。
当哨兵监测到master宕机,会自动将slave切换成master , 然后通过发布订阅模式通知其他的从服务器,修改配置文件, 让它们切换主机。
首先是配置,sentinel中会配置每个master和slaver的信息

在Server1 掉线后:

升级Server2 为新的主服务器:

Sentinel 的实现原理,主要分为以下三个步骤。
1.检测问题,主要讲的是三个定时任务,这三个内部的执行任务可以保证出现问题马上让 Sentinel 知道。
2.发现问题,主要讲的是主观下线和客观下线。当有一台 Sentinel 机器发现问题时,它就会主观对它主观下线,但是当多个 Sentinel 都发现有问题的时候,才会出现客观下线。
3.找到解决问题的人,主要讲的是领导者选举,如何在 Sentinel 内部多台节点做领导者选举,选出一个领导者。
4.解决问题,主要讲的是故障转移,即如何进行故障转移。
①首先要讲的是内部 Sentinel 会执行以下三个定时任务。
- 每10秒每个 Sentinel 对 Master 和 Slave 执行一次 Info Replication。指的是 Redis Sentinel 可以对 Redis 节点做失败判断和故障转移,来 Info Replication 发现 Slave 节点,这个命令可以确定主从关系。
- 每2秒每个 Sentinel 通过 Master 节点的 channel 交换信息(pub/sub)。类似于发布订阅,Sentinel 会对主从关系进行判定,通过
_sentinel_:hello频道交互 - 每1秒每个 Sentinel 对其他 Sentinel 和 Redis 执行 ping。指的是对每个节点和其它 Sentinel 进行心跳检测,它是失败判定的依据。
②那么什么是主观下线呢?
每个 Sentinel 节点对 Redis 节点失败的“偏见”。之所以是偏见,只是因为某一台机器30秒内没有得到回复。
那么如何做到客观下线呢?
这个时候需要所有 Sentinel 节点都发现它30秒内无回复,才会达到共识
③领导者选举 Redis使用Raft算法实现领导者选举
Sentinel 集群会采用领导者选举的方式,完成 Sentinel 节点的故障转移。通过 sentinel is-master-down-by-addr 命令都希望成为领导者。
领导者选举的三个步骤,请见下。
步骤1,每个做主观下线的 Sentinel 节点向其它节点发送命令,要求将它设置为领导者。
步骤2,收到命令的 Sentinel 节点,如果没有同意过其他Sentinel节点的sentinel is-master-down-by-addr命令,那么将同意该要求,否则就会拒绝。
步骤3,如果 Sentinel 节点发现自己的票数已经超过 Sentinel 半数同时也超过 Sentinel monitor mymaster 127.0.0.1 6379 3 中的3个的时候,那么它将成为领导者。
步骤4, 如果该Sentinel节点发现自己的票数已经大于等于max(quorum, num(sentinels)/2+1),那么它将成为领导者。如果有多个 Sentinel 节点成为领导者,那么将等待一段时间后重新选举。
这里需要解释一下为什么要重新选举。因为如果有多个领导者,那么哪个节点能覆盖更多的节点,才会成为真正的领导者,盲目成为领导者,只会让 Sentinel 效率低下,只有不断确认保证最优的选举,才是高效的,当然这个过程是需要时间消耗的。
④故障转移
故障转移主要包括以下四个步骤。如图
步骤1,从 Slave 节点中选出一个“合适的”节点作为新节点。
步骤2,对上面的节点执行 slaveof no one 命令让其成为 Master节点。
步骤3,向剩余的 Salve 节点发送命令,让他们成为新的 Master 节点的 Slave节点,复制规则和同步参数。
步骤4,将原来 Master 节点更新配置为 Slave 节点,并保持其“关注”。当其恢复后命令它去复制新的 Master 节点。
通过以上四步,就能获得 Master断掉 -> 选出新的 Master -> 同步 -> 旧 Master 恢复后成为 Slave,同时同步新的 Master数据这样一整套的流程。

基于Reactor(反应器)模式构建,redis是个单线程的reactor模型
实际上的Reactor模式,是基于Java NIO的,在他的基础上,抽象出来两个组件——Reactor和Handler两个组件:
(1)Reactor:负责响应IO事件,当检测到一个新的事件,将其发送给相应的Handler去处理;新的事件包含连接建立就绪、读就绪、写就绪等。
(2)Handler:将自身(handler)与事件绑定,负责事件的处理,完成channel的读入,完成处理业务逻辑后,负责将结果写出channel。
利用 linux 提供的 epoll 实现I/O 多路复用
这是linux中的epoll方法,一共三个
/**
* 创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大
*/
int epoll_create(int size);
/**
* 可以理解为,增删改 fd 需要监听的事件
* epfd 是 epoll_create() 创建的句柄。
* op 表示 增删改
* epoll_event 表示需要监听的事件,Redis 只用到了可读,可写,错误,挂断 四个状态
*/
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
/**
* 可以理解为查询符合条件的事件
* pfd 是 epoll_create() 创建的句柄。
* epoll_event 用来存放从内核得到事件的集合
* maxevents 获取的最大事件数
* timeout 等待超时时间
*/
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);再看 Redis 对文件事件,封装epoll向上提供的接口:
/* * 事件状态 */
typedef struct aeApiState {
// epoll_event 实例描述符
int epfd;
// 事件槽
struct epoll_event *events;
}aeApiState
/* * 创建一个新的 epoll */
static int aeApiCreate(aeEventLoop *eventLoop)
/* * 调整事件槽的大小 */
static int aeApiResize(aeEventLoop *eventLoop, int setsize)
/* * 释放 epoll 实例和事件槽 */
static void aeApiFree(aeEventLoop *eventLoop)
/* * 关联给定事件到 fd */
static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask)
/* * 从 fd 中删除给定事件 */
static void aeApiDelEvent(aeEventLoop *eventLoop, int fd, int mask)
/* * 获取可执行事件 */
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp)根据操作系统的不同,redis使用的系统内核的命令也不同,例如有select、epoll、evport和kqueue等。每个IO多路复用函数库在 Redis 源码中都对应一个单独的文件,比如ae_select.c,ae_epoll.c, ae_kqueue.c等。Redis 会根据不同的操作系统,按照不同的优先级选择多路复用技术。事件响应框架一般都采用该架构,比如 netty 和 libevent。
注:Gossip 协议的最大的好处是,即使集群节点的数量增加,每个节点的负载也不会增加很多,几乎是恒定的
Gossip 协议,就像流言蜚语一样,利用一种随机、带有传染性的方式,将信息传播到整个网络中,并在一定时间内,使得系统内的所有节点数据一致。
当A传播给B时,B有可能还会传播给A。
没啥注意事项
1、B+树的层级更少:相较于B树B+每个非叶子节点存储的关键字数更多,树的层级更少所以查询数据更快;(单一节点存储更多的元素,使得查询的IO次数更少。)
2、B+树查询速度更稳定:B+所有关键字数据地址都存在叶子节点上,所以每次查找的次数都相同所以查询速度要比B树更稳定;[O(logn)]
3、B+树天然具备排序功能:B+树所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高。
4、B+树全节点遍历更快:B+树遍历整棵树只需要遍历所有的叶子节点即可,,而不需要像B树一样需要对每一层进行遍历,这有利于数据库做全表扫描。
B树相对于B+树的优点是,如果经常访问的数据离根节点很近,而B树的非叶子节点本身存有关键字其数据的地址,所以这种数据检索的时候会要比B+树快。
主键是一种约束,唯一索引是一种索引,两者在本质上是不同的
主键创建后一定包含一个唯一性索引,唯一性索引并不一定就是主键。
唯一性索引列允许空值,而主键列不允许为空值
主要讲corePoolSize,maxPoolSize,队列这一块,线程的创建过程,详见第11个问题
① 底层实现上来说,synchronized 是JVM层面的锁,是Java关键字,通过monitor对象来完成(monitorenter与monitorexit),对象只有在同步块或同步方法中才能调用wait/notify方法,ReentrantLock 是从jdk1.5以来(java.util.concurrent.locks.Lock)提供的API层面的锁。
synchronized 的实现涉及到锁的升级,具体为无锁、偏向锁、自旋锁、向OS申请重量级锁,ReentrantLock实现则是通过利用CAS(CompareAndSwap)自旋机制保证线程操作的原子性和volatile(数据可见性及禁止指令重排)保证数据可见性以实现锁的功能
② 是否可手动释放:
synchronized 不需要用户去手动释放锁,synchronized 代码执行完后系统会自动让线程释放对锁的占用;
ReentrantLock则需要用户去手动释放锁,如果没有手动释放锁,就可能导致死锁现象。
③ 是否可中断
synchronized是不可中断类型的锁,除非加锁的代码中出现异常或正常执行完成;
ReentrantLock则可以中断,可通过trylock(long timeout,TimeUnit unit)设置超时方法或者将lockInterruptibly()放到代码块中,调用interrupt方法进行中断
④ 是否公平锁
synchronized为非公平锁
ReentrantLock则即可以选公平锁也可以选非公平锁,通过构造方法new ReentrantLock时传入boolean值进行选择,为空默认false非公平锁,true为公平锁。
⑤ 锁是否可绑定条件Condition
synchronized不能绑定;
ReentrantLock通过绑定Condition结合await()/singal()方法实现线程的精确唤醒,而不是像synchronized通过Object类的wait()/notify()/notifyAll()方法要么随机唤醒一个线程要么唤醒全部线程
锁主要存在四中状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态
①偏向锁
引入偏向锁的目的和引入轻量级锁的目的很像,他们都是为了没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗。
但是不同是:轻量级锁在无竞争的情况下使用 CAS 操作去代替使用互斥量。而偏向锁在无竞争的情况下会把整个同步都消除掉。
偏向锁的“偏”就是偏心的偏,它的意思是会偏向于第一个获得它的线程,如果在接下来的执行中,该锁没有被其他线程获取,那么持有偏向锁的线程就不需要进行同步!
② 轻量级锁
轻量级锁实现方式是各个线程在自己的线程栈生成LockRecord ,用CAS操作将markword设置为指向自己这个线程的LockRecord的指针,设置成功者得到锁,没有成功的将继续使用CAS一直循环直到成功,所以轻量级锁也叫自旋锁
倘若偏向锁失败,虚拟机并不会立即升级为重量级锁,它还会尝试使用一种称为轻量级锁的优化手段(1.6之后加入的)。轻量级锁不是为了代替重量级锁,它的本意是在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗,因为使用轻量级锁时,不需要申请互斥量。另外,轻量级锁的加锁和解锁都用到了CAS操作。
③ 自旋锁和自适应自旋
轻量级锁失败后,虚拟机为了避免线程真实地在操作系统层面挂起,还会进行一项称为自旋锁的优化手段。
互斥同步对性能最大的影响就是阻塞的实现,因为挂起线程/恢复线程的操作都需要转入内核态中完成(用户态转换到内核态会耗费时间)。
④ 锁消除
锁消除理解起来很简单,它指的就是虚拟机即使编译器在运行时,如果检测到那些共享数据不可能存在竞争,那么就执行锁消除。锁消除可以节省毫无意义的请求锁的时间。
在MQ的模型中,顺序需要由3个阶段去保障:
- 消息被发送时保持顺序
- 消息被存储时保持和发送的顺序一致
- 消息被消费时保持和存储的顺序一致
发送时保持顺序意味着对于有顺序要求的消息,用户应该在同一个线程中采用同步的方式发送。存储保持和发送的顺序一致则要求在同一线程中被发送出来的消息A和B,存储时在空间上A一定在B之前。而消费保持和存储一致则要求消息A、B到达Consumer之后必须按照先A后B的顺序被处理。如下图

将A和B发往同一个消费者即可,且发送A后,需要消费端响应成功后才能发送B。
| IO | NIO | AIO | BIO |
|---|---|---|---|
| 面向Stream | 面向Buffer | 面相buffer | 面相流 |
| 阻塞IO | 同步非阻塞IO(支持阻塞和非阻塞) | 异步非阻塞 | 同步阻塞式IO |
| Selectors |
一。IO请求的两个阶段: 1.等待资源阶段:IO请求一般需要请求特殊的资源(如磁盘、RAM、文件),当资源被上一个使用者使用没有被释放时,IO请求就会被阻塞,直到能够使用这个资源。 2.使用资源阶段:真正进行数据接收和发生。
二。在等待数据阶段,IO分为阻塞IO和非阻塞IO。 1.阻塞IO: 资源不可用时,IO请求一直阻塞,直到反馈结果(有数据或超时)。 2.非阻塞IO:资源不可用时,IO请求离开返回,返回数据标识资源不可用
三。在使用资源阶段,IO分为同步IO和异步IO。 1.同步IO:应用阻塞在发送或接收数据的状态,直到数据成功传输或返回失败。 2.异步IO:应用发送或接收数据后立刻返回,数据写入OS缓存,由OS完成数据发送或接收,并返回成功或失败的信息给应用。
四。IOPS,即每秒钟处理的IO请求数量。IOPS是随机访问类型业务(OLTP类)很重要的一个参考指标。

Common类加载器:负责加载Tomcat和Web应用都复用的类
Catalina类加载器:负责加载Tomcat专用的类,而这些被加载的类在Web应用中将不可见
Shared类加载器:负责加载Tomcat下所有的Web应用程序都复用的类,而这些被加载的类在Tomcat中将不可见
WebApp类加载器:负责加载具体的某个Web应用程序所使用到的类,而这些被加载的类在Tomcat和其他的Web应用程序都将不可见
Jsp类加载器:每个jsp页面一个类加载器,不同的jsp页面有不同的类加载器,方便实现jsp页面的热插拔
- 实例化 Instantiation
- 属性赋值 Populate
- 初始化 Initialization
- 销毁 Destruction


- Spring启动,查找并加载需要被Spring管理的bean,进行Bean的实例化
- Bean实例化后对将Bean的引入和值注入到Bean的属性中
- 如果Bean实现了BeanNameAware接口的话,Spring将Bean的Id传递给setBeanName()方法
- 如果Bean实现了BeanFactoryAware接口的话,Spring将调用setBeanFactory()方法,将BeanFactory容器实例传入
- 如果Bean实现了ApplicationContextAware接口的话,Spring将调用Bean的setApplicationContext()方法,将bean所在应用上下文引用传入进来。
- 如果Bean实现了BeanPostProcessor接口,Spring就将调用他们的postProcessBeforeInitialization()方法。
- 如果Bean 实现了InitializingBean接口,Spring将调用他们的afterPropertiesSet()方法。类似的,如果bean使用init-method声明了初始化方法,该方法也会被调用
- 如果Bean 实现了BeanPostProcessor接口,Spring就将调用他们的postProcessAfterInitialization()方法。
- 此时,Bean已经准备就绪,可以被应用程序使用了。他们将一直驻留在应用上下文中,直到应用上下文被销毁。
- 如果bean实现了DisposableBean接口,Spring将调用它的destory()接口方法,同样,如果bean使用了destory-method 声明销毁方法,该方法也会被调用。
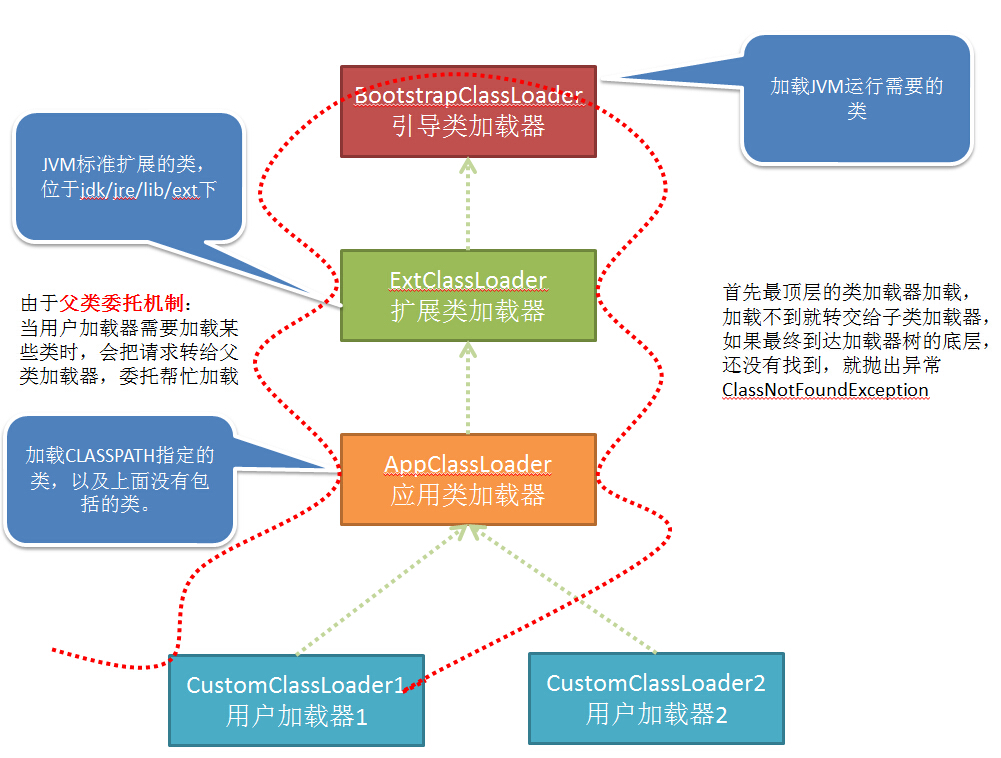
JVM中提供了三层的ClassLoader:(请求交由父类处理,它是一种任务委派模式)
Bootstrap classLoader:主要负责加载核心的类库(java.lang.*等),构造ExtClassLoader和APPClassLoader。
ExtClassLoader:主要负责加载jre/lib/ext目录下的一些扩展的jar。
AppClassLoader:主要负责加载应用程序的主函数类
工作原理:
(1)如果一个类加载器收到了类加载请求,它并不会自己先加载,而是把这个请求委托给父类的加载器去执行
(2)如果父类加载器还存在其父类加载器,则进一步向上委托,依次递归,请求最终将到达顶层的引导类加载器;
(3)如果父类加载器可以完成类加载任务,就成功返回,倘若父类加载器无法完成加载任务,子加载器才会尝试自己去加载,这就是双亲委派机制
(4)父类加载器一层一层往下分配任务,如果子类加载器能加载,则加载此类,如果将加载任务分配至系统类加载器也无法加载此类,则抛出异常
作用:
①**防止加载同一个.class。**通过委托去询问上级是否已经加载过该.class,如果加载过了,则不需要重新加载。保证了数据安全。
②**保证核心.class不被篡改。**通过委托的方式,保证核心.class不被篡改,即使被篡改也不会被加载,即使被加载也不会是同一个class对象,因为不同的加载器加载同一个.class也不是同一个Class对象。这样则保证了Class的执行安全。
临时方案:
为尽快回复业务,删除上有步骤中查询到的大KEY,执行操作如下:(非字符串的bigkey,不要使用 del 删除,使用 hscan、sscan、zscan 方式渐进式删除)
长期方案:
通过对大KEY进行拆分,将一个大的KEY拆分为多个小的KEY, 变成value1,value2… valueN,打散分不到不同的分片中,避免因为数据倾斜导致的数据分布不均。
另外查询大key的几个方法:①DEBUG OBJECT [要查的key名字]
②bigkey命令:redis-cli -h 127.0.0.1 -p 6379 --bigkeys
③memory usage [要查的key名字]
④ rdb_bigkeys工具
java 8默认垃圾收集器 UseParallelGC
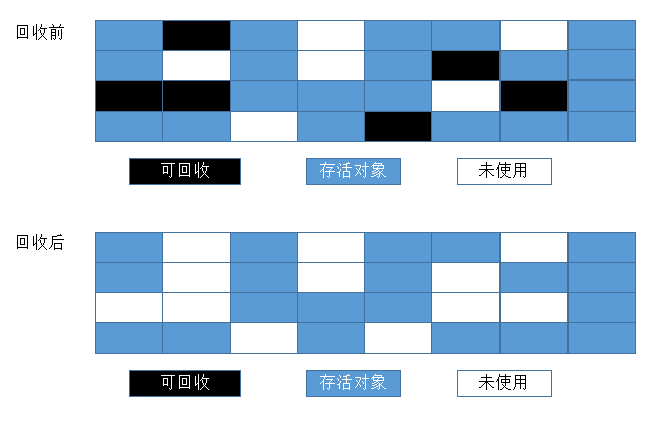
标记-清除(Mark-Sweep)算法
这是最基础的算法,标记-清除算法就如同它的名字样,分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,标记完成后统一回收所有被标记的对象。这种算法的不足主要体现在效率和空间,从效率的角度讲,标记和清除两个过程的效率都不高;从空间的角度讲,标记清除后会产生大量不连续的内存碎片, 内存碎片太多可能会导致以后程序运行过程中在需要分配较大对象时,无法找到足够的连续内存而不得不提前触发一次垃圾收集动作
复制算法是为了解决效率问题而出现的,它将可用的内存分为两块,每次只用其中一块,当这一块内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已经使用过的内存空间一次性清理掉。这样每次只需要对整个半区进行内存回收,内存分配时也不需要考虑内存碎片等复杂情况,只需要移动指针,按照顺序分配即可
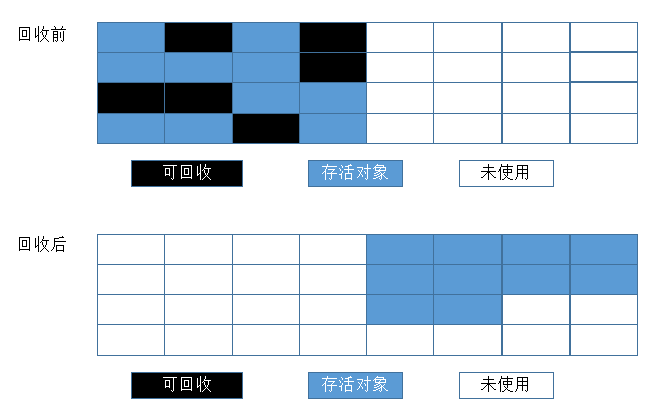
复制算法在对象存活率较高的场景下要进行大量的复制操作,效率很低。万一对象100%存活,那么需要有额外的空间进行分配担保。老年代都是不易被回收的对象,对象存活率高,因此一般不能直接选用复制算法。根据老年代的特点,有人提出了另外一种标记-整理算法,过程与标记-清除算法一样,不过不是直接对可回收对象进行清理,而是让所有存活对象都向一端移动,然后直接清理掉边界以外的内存。标记-整理算法的工作过程如图:
垃圾收集器
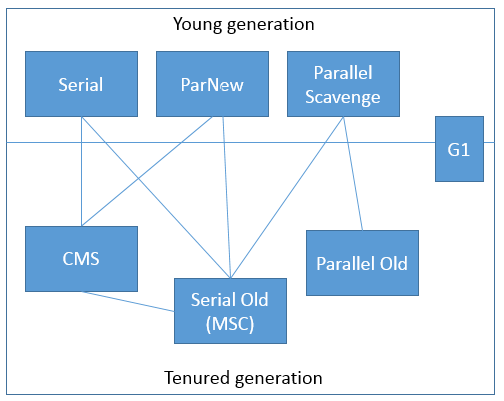
最基本、发展历史最久的收集器,这个收集器是一个采用UseParallelGC的单线程的收集器,单线程一方面意味着它只会使用一个CPU或一条线程去完成垃圾收集工作,另一方面也意味着它进行垃圾收集时必须暂停其他线程的所有工作,直到它收集结束为止。后者意味着,在用户不可见的情况下要把用户正常工作的线程全部停掉,这对很多应用是难以接受的。不过实际上到目前为止,Serial收集器依然是虚拟机运行在Client模式下的默认新生代收集器,因为它简单而高效。用户桌面应用场景中,分配给虚拟机管理的内存一般来说不会很大,收集几十兆甚至一两百兆的新生代停顿时间在几十毫秒最多一百毫秒,只要不是频繁发生,这点停顿是完全可以接受的。Serial收集器运行过程如下图所示:
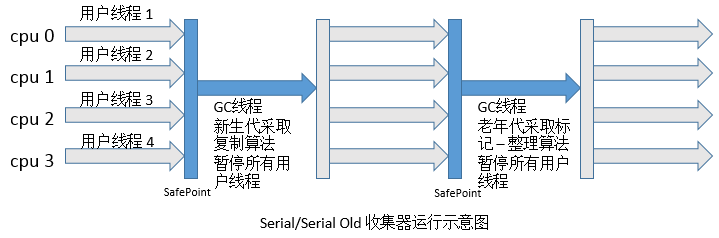
说明:1. 需要STW(Stop The World),停顿时间长。2. 简单高效,对于单个CPU环境而言,Serial收集器由于没有线程交互开销,可以获取最高的单线程收集效率。
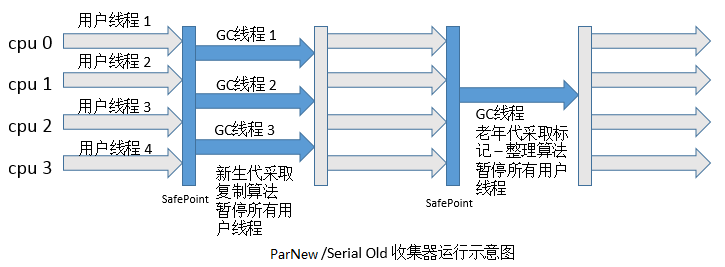
ParNew收集器其实就是Serial收集器的多线程版本,除了使用多条线程进行垃圾收集外,其余行为和Serial收集器完全一样,包括使用的也是复制算法。ParNew收集器除了多线程以外和Serial收集器并没有太多创新的地方,但是它却是Server模式下的虚拟机首选的新生代收集器,其中有一个很重要的和性能无关的原因是,除了Serial收集器外,目前只有它能与CMS收集器配合工作(看图)。CMS收集器是一款几乎可以认为有划时代意义的垃圾收集器,因为它第一次实现了让垃圾收集线程与用户线程基本上同时工作。ParNew收集器在单CPU的环境中绝对不会有比Serial收集器更好的效果,甚至由于线程交互的开销,该收集器在两个CPU的环境中都不能百分之百保证可以超越Serial收集器。当然,随着可用CPU数量的增加,它对于GC时系统资源的有效利用还是很有好处的。它默认开启的收集线程数与CPU数量相同,在CPU数量非常多的情况下,可以使用-XX:ParallelGCThreads参数来限制垃圾收集的线程数。ParNew收集器运行过程如下图所示:
Parallel Scavenge收集器也是一个新生代收集器,也是用复制算法的收集器,也是并行的多线程收集器,但是它的特点是它的关注点和其他收集器不同。介绍这个收集器主要还是介绍吞吐量的概念。CMS等收集器的关注点是尽可能缩短垃圾收集时用户线程的停顿时间,而Parallel Scavenge收集器的目标则是打到一个可控制的吞吐量。所谓吞吐量的意思就是CPU用于运行用户代码时间与CPU总消耗时间的比值,即吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间),虚拟机总运行100分钟,垃圾收集1分钟,那吞吐量就是99%。另外,Parallel Scavenge收集器是虚拟机运行在Server模式下的默认垃圾收集器。
停顿时间短适合需要与用户交互的程序,良好的响应速度能提升用户体验;高吞吐量则可以高效率利用CPU时间,尽快完成运算任务,主要适合在后台运算而不需要太多交互的任务。
虚拟机提供了-XX:MaxGCPauseMillis和-XX:GCTimeRatio两个参数来精确控制最大垃圾收集停顿时间和吞吐量大小。不过不要以为前者越小越好,GC停顿时间的缩短是以牺牲吞吐量和新生代空间换取的。由于与吞吐量关系密切,Parallel Scavenge收集器也被称为“吞吐量优先收集器”。Parallel Scavenge收集器有一个-XX:+UseAdaptiveSizePolicy参数,这是一个开关参数,这个参数打开之后,就不需要手动指定新生代大小、Eden区和Survivor参数等细节参数了,虚拟机会根据当前系统的运行情况以及性能监控信息,动态调整这些参数以提供最合适的停顿时间或者最大的吞吐量。如果对于垃圾收集器运作原理不太了解,以至于在优化比较困难的时候,使用Parallel Scavenge收集器配合自适应调节策略,把内存管理的调优任务交给虚拟机去完成将是一个不错的选择。
Serial收集器的老年代版本,同样是一个单线程收集器,使用“标记-整理算法”,这个收集器的主要意义也是在于给Client模式下的虚拟机使用。
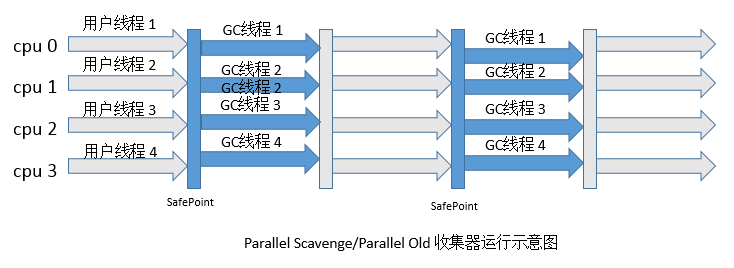
Parallel Scavenge收集器的老年代版本,使用多线程和“UseParallelGC”算法。这个收集器在JDK 1.6之后的出现,“吞吐量优先收集器”终于有了比较名副其实的应用组合,在注重吞吐量以及CPU资源敏感的场合,都可以优先考虑Parallel Scavenge收集器+Parallel Old收集器的组合。运行过程如下图所示:
CMS(Conrrurent Mark Sweep)收集器是以获取最短回收停顿时间为目标的收集器。使用标记 - 清除算法,收集过程分为如下四步:
- 初始标记,标记GCRoots能直接关联到的对象,时间很短。
- 并发标记,进行GCRoots Tracing(可达性分析)过程,时间很长。
- 重新标记,修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,时间较长。
- 并发清除,回收内存空间,时间很长。
其中,并发标记与并发清除两个阶段耗时最长,但是可以与用户线程并发执行。运行过程如下图所示:
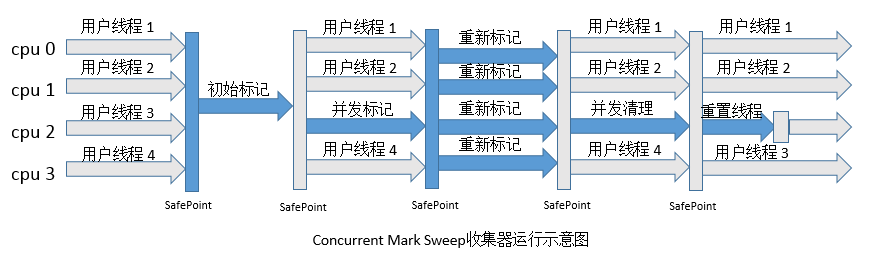
说明:
- 对CPU资源非常敏感,可能会导致应用程序变慢,吞吐率下降。
- 无法处理浮动垃圾,因为在并发清理阶段用户线程还在运行,自然就会产生新的垃圾,而在此次收集中无法收集他们,只能留到下次收集,这部分垃圾为浮动垃圾,同时,由于用户线程并发执行,所以需要预留一部分老年代空间提供并发收集时程序运行使用。
- 由于采用的标记 - 清除算法,会产生大量的内存碎片,不利于大对象的分配,可能会提前触发一次Full GC。虚拟机提供了-XX:+UseCMSCompactAtFullCollection参数来进行碎片的合并整理过程,这样会使得停顿时间变长,虚拟机还提供了一个参数配置,-XX:+CMSFullGCsBeforeCompaction,用于设置执行多少次不压缩的Full GC后,接着来一次带压缩的GC。
G1算法将堆划分为若干个区域(Region),它仍然属于分代收集器。不过,这些区域的一部分包含新生代,新生代的垃圾收集依然采用暂停所有应用线程的方式,将存活对象拷贝到老年代或者Survivor空间。老年代也分成很多区域,G1收集器通过将对象从一个区域复制到另外一个区域,完成了清理工作。这就意味着,在正常的处理过程中,G1完成了堆的压缩(至少是部分堆的压缩),这样也就不会有cms内存碎片问题的存在了。
在G1中,还有一种特殊的区域,叫Humongous区域。 如果一个对象占用的空间超过了分区容量50%以上,G1收集器就认为这是一个巨型对象。这些巨型对象,默认直接会被分配在年老代,但是如果它是一个短期存在的巨型对象,就会对垃圾收集器造成负面影响。为了解决这个问题,G1划分了一个Humongous区,它用来专门存放巨型对象。如果一个H区装不下一个巨型对象,那么G1会寻找连续的H分区来存储。为了能找到连续的H区,有时候不得不启动Full GC。
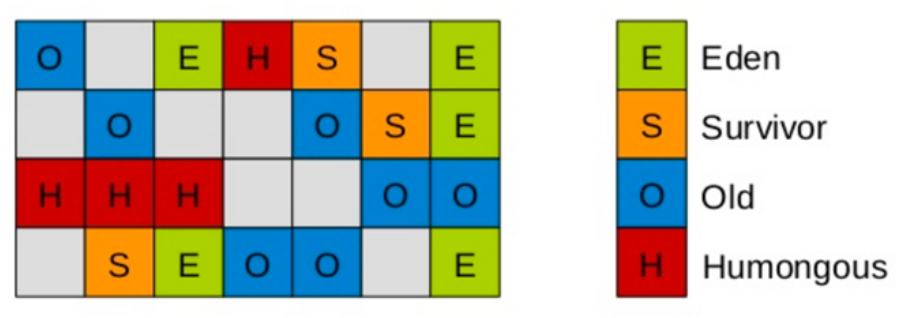
G1主要有以下特点:
- 并行和并发。使用多个CPU来缩短Stop The World停顿时间,与用户线程并发执行。
- 分代收集。独立管理整个堆,但是能够采用不同的方式去处理新创建对象和已经存活了一段时间、熬过多次GC的旧对象,以获取更好的收集效果。
- 空间整合。基于标记 - 整理算法,无内存碎片产生。
- 可预测的停顿。能简历可预测的停顿时间模型,能让使用者明确指定在一个长度为M毫秒的时间片段内,消耗在垃圾收集上的时间不得超过N毫秒。
在G1之前的垃圾收集器,收集的范围都是整个新生代或者老年代,而G1不再是这样。使用G1收集器时,Java堆的内存布局与其他收集器有很大差别,它将整个Java堆划分为多个大小相等的独立区域(Region),虽然还保留有新生代和老年代的概念,但新生代和老年代不再是物理隔离的了,它们都是一部分(可以不连续)Region的集合。
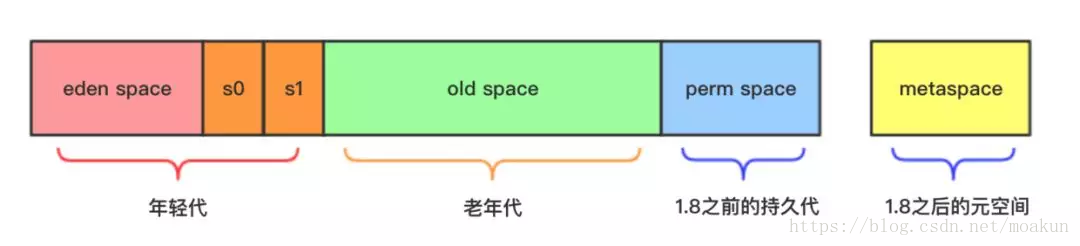
- 新生代:eden space + 2个survivor
- 老年代:old space
- 持久代:1.8之前的perm space
- 元空间:1.8之后的metaspace
注意:这些space必须是地址连续的空间
-
对象分配
-
优先在Eden区分配
在JVM内存模型一文中, 我们大致了解了VM年轻代堆内存可以划分为一块Eden区和两块Survivor区. 在大多数情况下, 对象在新生代Eden区中分配, 当Eden区没有足够空间分配时, VM发起一次Minor GC, 将Eden区和其中一块Survivor区内尚存活的对象放入另一块Survivor区域, 如果在Minor GC期间发现新生代存活对象无法放入空闲的Survivor区, 则会通过空间分配担保机制使对象提前进入老年代(空间分配担保见下).
-
大对象直接进入老年代
Serial和ParNew两款收集器提供了-XX:PretenureSizeThreshold的参数, 令大于该值的大对象直接在老年代分配, 这样做的目的是避免在Eden区和Survivor区之间产生大量的内存复制(大对象一般指 需要大量连续内存的Java对象, 如很长的字符串和数组), 因此大对象容易导致还有不少空闲内存就提前触发GC以获取足够的连续空间.
然而取历次晋升的对象的平均大小也是有一定风险的, 如果某次Minor GC存活后的对象突增,远远高于平均值的话,依然可能导致担保失败(Handle Promotion Failure, 老年代也无法存放这些对象了), 此时就只好在失败后重新发起一次Full GC(让老年代腾出更多空间).
-
空间分配担保
在执行Minor GC前, VM会首先检查老年代是否有足够的空间存放新生代尚存活对象, 由于新生代使用复制收集算法, 为了提升内存利用率, 只使用了其中一个Survivor作为轮换备份, 因此当出现大量对象在Minor GC后仍然存活的情况时, 就需要老年代进行分配担保, 让Survivor无法容纳的对象直接进入老年代, 但前提是老年代需要有足够的空间容纳这些存活对象. 但存活对象的大小在实际完成GC前是无法明确知道的, 因此Minor GC前, VM会先首先检查老年代连续空间是否大于新生代对象总大小或历次晋升的平均大小, 如果条件成立, 则进行Minor GC, 否则进行Full GC(让老年代腾出更多空间).
-
-
对象晋升
-
年龄阈值
VM为每个对象定义了一个对象年龄(Age)计数器, 对象在Eden出生如果经第一次Minor GC后仍然存活, 且能被Survivor容纳的话, 将被移动到Survivor空间中, 并将年龄设为1. 以后对象在Survivor区中每熬过一次Minor GC年龄就+1. 当增加到一定程度(-XX:MaxTenuringThreshold, 默认15), 将会晋升到老年代.
-
提前晋升: 动态年龄判定
然而VM并不总是要求对象的年龄必须达到MaxTenuringThreshold才能晋升老年代: 如果在Survivor空间中相同年龄所有对象大小的总和大于Survivor空间的一半, 年龄大于或等于该年龄的对象就可以直接进入老年代, 而无须等到晋升年龄.
-
-
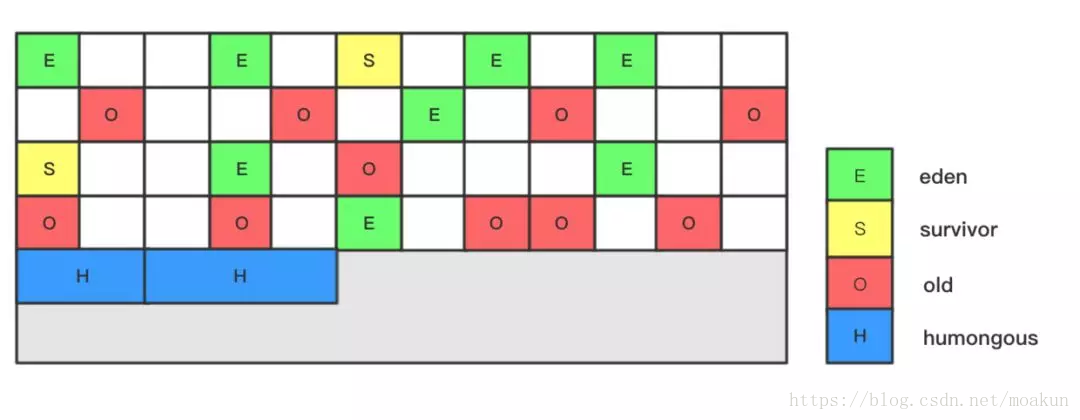
Young GC
发生在年轻代的GC算法,一般对象(除了巨型对象)都是在eden region中分配内存,当所有eden region被耗尽无法申请内存时,就会触发一次young gc,这种触发机制和之前的young gc差不多,执行完一次young gc,活跃对象会被拷贝到survivor region或者晋升到old region中,空闲的region会被放入空闲列表中,等待下次被使用。
-
Mixed GC
当越来越多的对象晋升到老年代old region时,为了避免堆内存被耗尽,虚拟机会触发一个混合的垃圾收集器,即mixed gc,该算法并不是一个old gc,除了回收整个young region,还会回收一部分的old region,这里需要注意:是一部分老年代,而不是全部老年代,可以选择哪些old region进行收集,从而可以对垃圾回收的耗时时间进行控制。
-
Full GC
如果对象内存分配速度过快,mixed gc来不及回收,导致老年代被填满,就会触发一次full gc,G1的full gc算法就是单线程执行的serial old gc,会导致异常长时间的暂停时间,需要进行不断的调优,尽可能的避免full gc.
-
首先查看你使用的垃圾回收器是什么?
java -XX:+PrintCommandLineFlags -version -
根据自身系统需求选择最合适的垃圾回收器(没有最好的,只有最是适合的)

①首先是子查询,查询出主键id,根据主键id去limit
SELECT * FROM product WHERE ID > =(select id from product limit 866613, 1) limit 20
②循环查询时,假如说每次查1000条,得到了最后一天id=1000,然后下一条从id=1001开始查
SELECT * FROM product WHERE ID > =(select id from product limit 866613, 1) limit 20
③ 基于索引使用prepare预处理
比如:PREPARE stmt_name FROM SELECT * FROM 表名称 WHERE id_pk > (?* ?) ORDER BY id_pk ASC LIMIT 10
第一个?表示pageNum页数,第二个?表示每页数据量
④加索引,例如复合索引
1.redis单线程减库存
https://www.freesion.com/article 文中有很多关于超卖的文章
2.数据库锁机制
update goods set num = num - 1 WHERE id = 1001 and num > 0 这种就是利用了排它锁机制
②版本号机制,也就是CAS的原理
select version from goods WHERE id= 1001
update goods set num = num - 1, version = version + 1 WHERE id= 1001 AND num > 0 AND version = @version(上面查到的version);3.利用Semaphore类作为信号量(https://zhuanlan.zhihu.com/p/439030472 内容不错)
原理:拿到一个令牌,去减一个库存,剩下的要不阻塞,要不想办法拒绝,如果支付订单超时,则再加一个令牌
答案:拿不到令牌的线程阻塞,不会继续往下运行。
答案:线程阻塞,不会继续往下运行。可能你会考虑类似于锁的重入的问题,很好,但是,令牌没有重入的概念。你只要调用一次acquire方法,就需要有一个令牌才能继续运行。
答案:能,原因是release方法会添加令牌,并不会以初始化的大小为准
举例代码:
/**
* 线程数量,30个人
*/
private static final int THREAD_COUNT = 30;
/**
* 线程池
*/
private static ExecutorService executor = Executors.newFixedThreadPool(THREAD_COUNT);
//只有10个库存 这里还需要有个监听程序,监听库存为0时,结束秒杀活动,同时释放semaphore,
private static Semaphore semaphore = new Semaphore(10);
private boolean timeout = true;
public static void main(String[] args) {
for (int i = 0; i < THREAD_COUNT; i++) {
executor.execute(new Runnable() {
public void run() {
try {
// 获取一个"许可证"
if(!semaphore.tryAcquire()){
// 模拟数据保存,生成订单
TimeUnit.SECONDS.sleep(2);
}else{
//没有获取到直接返回
return;
}
System.out.println("save date..."+Thread.currentThread().getName());
System.out.println("订单支付..."+Thread.currentThread().getName());
//TODO xxxx 订单支付超时
if(timeout = true){
//归还"许可证"
semaphore.release();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
executor.shutdown();
}4.synchronize加锁或者ReentrantLock加锁
5.队列串行化
首先查看实时GC情况
jstat -gcutil 17093 1000
然后再使用命令得到dump文件
jmap -dump:format=b,file=temp.dump 17093
再然后使用mat工具或者jvisualvm工具分析dump文件
逐行读取,然后追加到文件
SOFARPC 从下到上分为两层:
- 核心层:包含了我们的 RPC 的核心组件(例如我们的各种接口、API、公共包)以及一些通用的实现(例如随机等负载均衡算法)。
- 功能实现层:所有的功能实现层的用户都是平等的,都是基于扩展机制实现的。
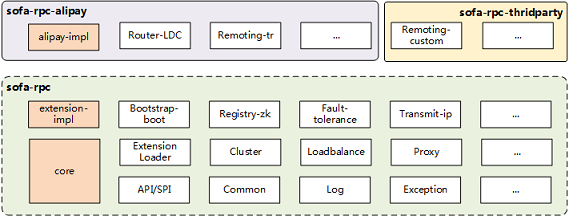
sofa RPC模块划分图
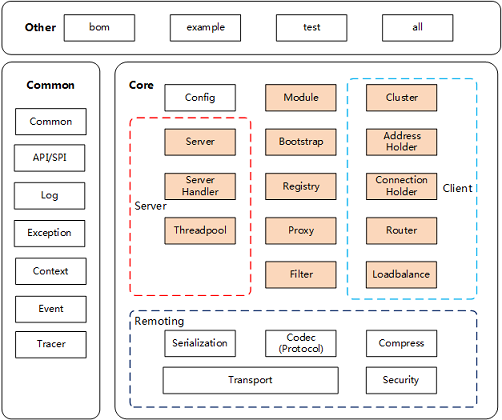
| 模块名 | 子模块名 | 中文名 | 说明 | 依赖 |
|---|---|---|---|---|
| all | 发布打包模块 | 需要打包的全部模块 | ||
| bom | 依赖管控模块 | 依赖版本管控 | 无 | |
| example | 示例模块 | all | ||
| test | 测试模块 | 包含集成测试 | all | |
| core | api | API模块 | 各种基本流程接口、消息、上下文、扩展接口等 | common |
| core | common | 公共模块 | utils、数据结构 | exception |
| core | exception | 异常模块 | 各种异常接口等 | common |
| bootstrap | 启动实现模块 | 启动类,发布或者引用服务逻辑、以及registry的操作 | core | |
| proxy | 代理实现模块 | 接口实现代理生成 | core | |
| client | 客户端实现模块 | 发送请求、接收响应、连接维护、路由、负载均衡、同步异步等 | core | |
| server | 服务端实现模块 | 启动监听、接收请求,发送响应、业务线程分发等 | core | |
| filter | 拦截器实现模块 | 服务端和客户端的各种拦截器实现 | core | |
| codec | 编解码实现模块 | 例如压缩,序列化等 | core | |
| protocol | 协议实现模块 | 协议的包装处理、协商 | core | |
| transport | 网络传输实现模块 | TCP连接的建立,数据分包粘包处理,请求响应对象分发等 | core | |
| registry | 注册中心实现模块 | 实现注册中心,例如zk等 | core |
https://blog.csdn.net/qq_36752224/article/details/112913735
/**
* 多线程读写文件
*/
public class Copy {
public static long len,segmentLen;
//创建8个IO接口一起读文件
public static RandomAccessFile[] rafSource = new RandomAccessFile[8];
//创建8个IO接口一起写文件
public static RandomAccessFile[] rafTarget = new RandomAccessFile[8];
//已处理字节数
public static long processedCnt = 0;
//记录每个线程的处理进度
public static boolean[] flag = new boolean[8];
public static void main(String[] args) throws IOException {
for(int i=0;i<8;i++){
rafSource[i] = new RandomAccessFile("C:\\Users\\98738\\Desktop\\test\\2019-04-13_用30个类高仿真提炼纯手写Spring框架V2.0.flv","rwd");
rafTarget[i] = new RandomAccessFile("C:\\Users\\98738\\Desktop\\test\\复制版本.flv","rwd");
}
//获取文件的长度
len = rafSource[0].length();
//创建一个新的等大空白文件,方便多线程操作
rafTarget[0].setLength(len);
//获取每一段的长度
segmentLen = len/8;
for(int i=0;i<8;i++){
//8条线程,同时处理
new ProData(i).start();
}
//开启计数线程
new SpeedGetter().start();
}
}public class ProData extends Thread{
//线程id
private int tid;
public ProData(int tid) {
this.tid = tid;
}
@Override
public void run() {
//开始位置
long begin = tid * Copy.segmentLen;
//计算末尾位置
long end = (tid == 7) ? Copy.len : begin + Copy.segmentLen;
byte[] buffer = new byte[1024*1024];
int validLen;
//一次处理1M的数据
for(long i = begin;i<end;i += 1024*1024){
try {
//设置读位置
Copy.rafSource[tid].seek(i);
//开始读
validLen = Copy.rafSource[tid].read(buffer);
//设置写位置
Copy.rafTarget[tid].seek(i);
//开始写
Copy.rafTarget[tid].write(buffer,0,validLen);
//更新已处理的字节数
Copy.processedCnt += 1024*1024;
} catch (IOException e) {
e.printStackTrace();
}
}
try {
Copy.rafSource[tid].close();
Copy.rafTarget[tid].close();
} catch (IOException e) {
e.printStackTrace();
}
//标记线程处理完毕
Copy.flag[tid] = true;
}
}public class SpeedGetter extends Thread {
//已经经过的秒数
private int sec = 0;
//检查是否处理完毕
private boolean check;
@Override
public void run() {
while (true){
sec++;
check = false;
System.out.println(((double) Copy.processedCnt/1024/1024/sec)+"MB/S");
System.out.println(((double) Copy.len/100)+"%");
for(int i=0;i<8;i++){
if(!Copy.flag[i]){
check = true;
}
}
if(!check){
System.out.println("已经处理完成!");
System.exit(0);
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
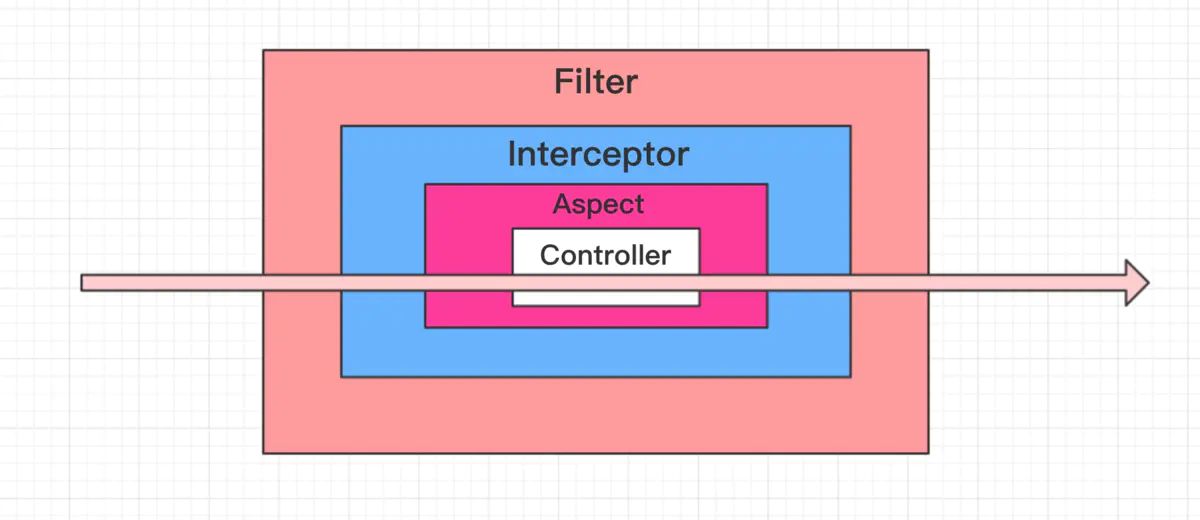
}1,filter即过滤器,基于servlet容器,处于最外层,
所以它会最先起作用,最后才停止
说明:filter对所有访问到servlet容器的url都有效,包括静态资源
2,interceptor即拦截器,基于web框架,它会在filter之后起作用
说明:spring boot 1.x中,静态资源已被interceptor排除,
spring boot 2.x中,需要自己手动排除到静态资源的访问
filter和interceptor都是作用于请求
3,aop即切面,基于Spring的IOC容器,对spring管理的bean有效,
它会在interceptor之后才生效
aop可以作用于类和方法
Propagation类中的7个属性,说实话,我懒得记
public enum Propagation {
支持当前事务,如果当前事务不存在,创建一个新的事务
REQUIRED(TransactionDefinition.PROPAGATION_REQUIRED),
支持当前事务,如果当前事务不存在,则以非事务方式执行。
SUPPORTS(TransactionDefinition.PROPAGATION_SUPPORTS),
支持当前事务,如果当前事务不存在,抛出异常。
MANDATORY(TransactionDefinition.PROPAGATION_MANDATORY),
创建一个新的事务,如果当前事务存在,则挂起当前事务。
REQUIRES_NEW(TransactionDefinition.PROPAGATION_REQUIRES_NEW),
非事务执行,如果当前事务存在,挂起当前事务。
NOT_SUPPORTED(TransactionDefinition.PROPAGATION_NOT_SUPPORTED),
以非事务方式执行,如果存在事务则抛出异常。
NEVER(TransactionDefinition.PROPAGATION_NEVER),
如果当前事务存在,则在嵌套事务中执行
NESTED(TransactionDefinition.PROPAGATION_NESTED);- 访问权限问题 比如private
- 方法用final修饰
- 未被Spring管理
- 错误的传播特性
- 自己吞了异常
- 手动抛了别的异常
- 自定义了回滚异常
- 方法内部调用
1.如果条件中有or,即使其中有条件带索引也不会使用
2.对于多列索引,不是使用的第一部分(第一个),则不会使用索引(最左匹配原则)
3.like查询是以%开头(引申一下,为什么会失效?因为索引相当字典的目录,知道开头就能快速的查找,你不知道开头,就无法去查找)
4.如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
5.如果mysql估计使用全表扫描要比使用索引快,则不使用索引
6.没有查询条件,或者查询条件上没有索引列

select_type
*示查询中每个select子句的类型*
(1) SIMPLE(简单SELECT,不使用UNION或子查询等)
(2) PRIMARY(子查询中最外层查询,查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY)
(3) UNION(UNION中的第二个或后面的SELECT语句)
(4) DEPENDENT UNION(UNION中的第二个或后面的SELECT语句,取决于外面的查询)
(5) UNION RESULT(UNION的结果,union语句中第二个select开始后面所有select)
(6) SUBQUERY(子查询中的第一个SELECT,结果不依赖于外部查询)
(7) DEPENDENT SUBQUERY(子查询中的第一个SELECT,依赖于外部查询)
(8) DERIVED(派生表的SELECT, FROM子句的子查询)
(9) UNCACHEABLE SUBQUERY(一个子查询的结果不能被缓存,必须重新评估外链接的第一行)
type
对表访问方式,表示MySQL在表中找到所需行的方式,又称“访问类型”。
常用的类型有: **ALL、index、range、 ref、eq_ref、const、system、**NULL(从左到右,性能从差到好)
ALL:Full Table Scan, MySQL将遍历全表以找到匹配的行
index: Full Index Scan,index与ALL区别为index类型只遍历索引树
range:只检索给定范围的行,使用一个索引来选择行
ref: 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
eq_ref: 类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件
const、system: 当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量,system是const类型的特例,当查询的表只有一行的情况下,使用system
NULL: MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。
possible_keys
指出MySQL能使用哪个索引在表中找到记录,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用(该查询可以利用的索引,如果没有任何索引显示 null)
该列完全独立于EXPLAIN输出所示的表的次序。这意味着在possible_keys中的某些键实际上不能按生成的表次序使用。 如果该列是NULL,则没有相关的索引。在这种情况下,可以通过检查WHERE子句看是否它引用某些列或适合索引的列来提高你的查询性能。如果是这样,创造一个适当的索引并且再次用EXPLAIN检查查询
Key
key列显示MySQL实际决定使用的键(索引),必然包含在possible_keys中
key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度(key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的)
ref
列与索引的比较,表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
rows
估算出结果集行数,表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数
Extra
该列包含MySQL解决查询的详细信息,有以下几种情况:
Using where:不用读取表中所有信息,仅通过索引就可以获取所需数据,这发生在对表的全部的请求列都是同一个索引的部分的时候,表示mysql服务器将在存储引擎检索行后再进行过滤
Using temporary:表示MySQL需要使用临时表来存储结果集,常见于排序和分组查询,常见 group by ; order by
Using filesort:当Query中包含 order by 操作,而且无法利用索引完成的排序操作称为“文件排序”
-- 测试Extra的filesort
explain select * from emp order by name;Using join buffer:改值强调了在获取连接条件时没有使用索引,并且需要连接缓冲区来存储中间结果。如果出现了这个值,那应该注意,根据查询的具体情况可能需要添加索引来改进能。
Impossible where:这个值强调了where语句会导致没有符合条件的行(通过收集统计信息不可能存在结果)。
Select tables optimized away:这个值意味着仅通过使用索引,优化器可能仅从聚合函数结果中返回一行
No tables used:Query语句中使用from dual 或不含任何from子句
-- explain select now() from dual;