{kind=link}
{kind=link}
{kind=link}
please check LaNAS/LA-MCTS repository for our latest results
AlphaX is a new Neural Architecture Search (NAS) agent that uses MCTS for efficient model architecture search with Meta-DNN as a predictive model to estimate the accuracy of a sampled architecture. Compared with Random Search, AlphaX builds an online model which guides the future search, compared to greedy methods, e.g. Q-learning, Regularized Evolution or Top-K methods, AlphaX dynamically trades off exploration and exploitation and can escape from local optimum with fewer number of search trials. For details of AlphaX, please refer to Neural Architecture Search using Deep Neural Networks and Monte Carlo Tree Search.
This repository hosts the implementation of AlphaX for searching on a design domain defined by NASBench-101. NASBench-101 is a NAS dataset that contains 420k+ networks with their actual training, validation accuracies. For details of NASBench-101, please check here.
The comparisions of sample efficiency, MCTS v.s. various baselines in NASBench-101, is shown below:
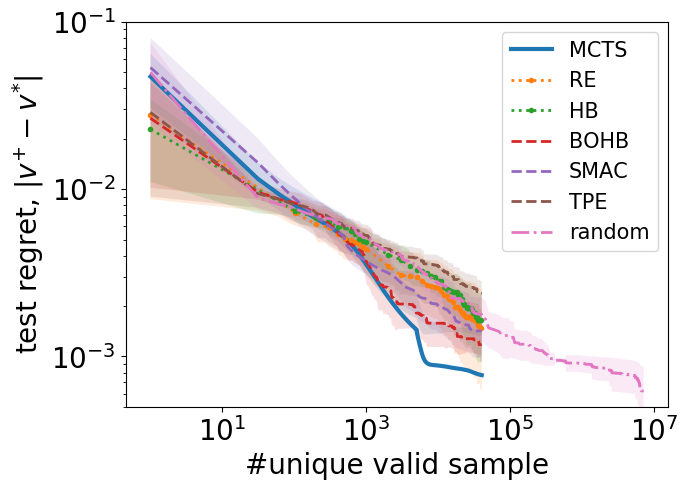
Our encoding mechanism is same as NASBench, formulating a search space of 500000000 architectures. While NASBench only contains 420000 architecture-accuracy pairs, and we return 0 for those not in the dataset but in the search space. The predictive models such as using a simple MLP can perform well (<= 6000 to find the global optimum on the dataset, see this repo https://github.com/linnanwang/MLP-NASBench-101) if only train and predict using 420000 architectures in NASBench, but this result is unfair and invalid as in the real scenarios, it will be impossible to enumerate and predict every architecture in the search space, e.g. NASNet 10^20. In fact, using a pure predictive model to guide the search is proven to be less efficient than SMBO alternatives such as Bayesian Optimizations for lacking a mechanism to explore.
Therefore, please pay attention to these minor details! A good result does not necessarily mean a good algorithm!
This is how AlphaX progressively probes the search domain. Each node represents an MCTS state; the node color reflects its value, i.e. accuracy, indicating how promising a search branch.
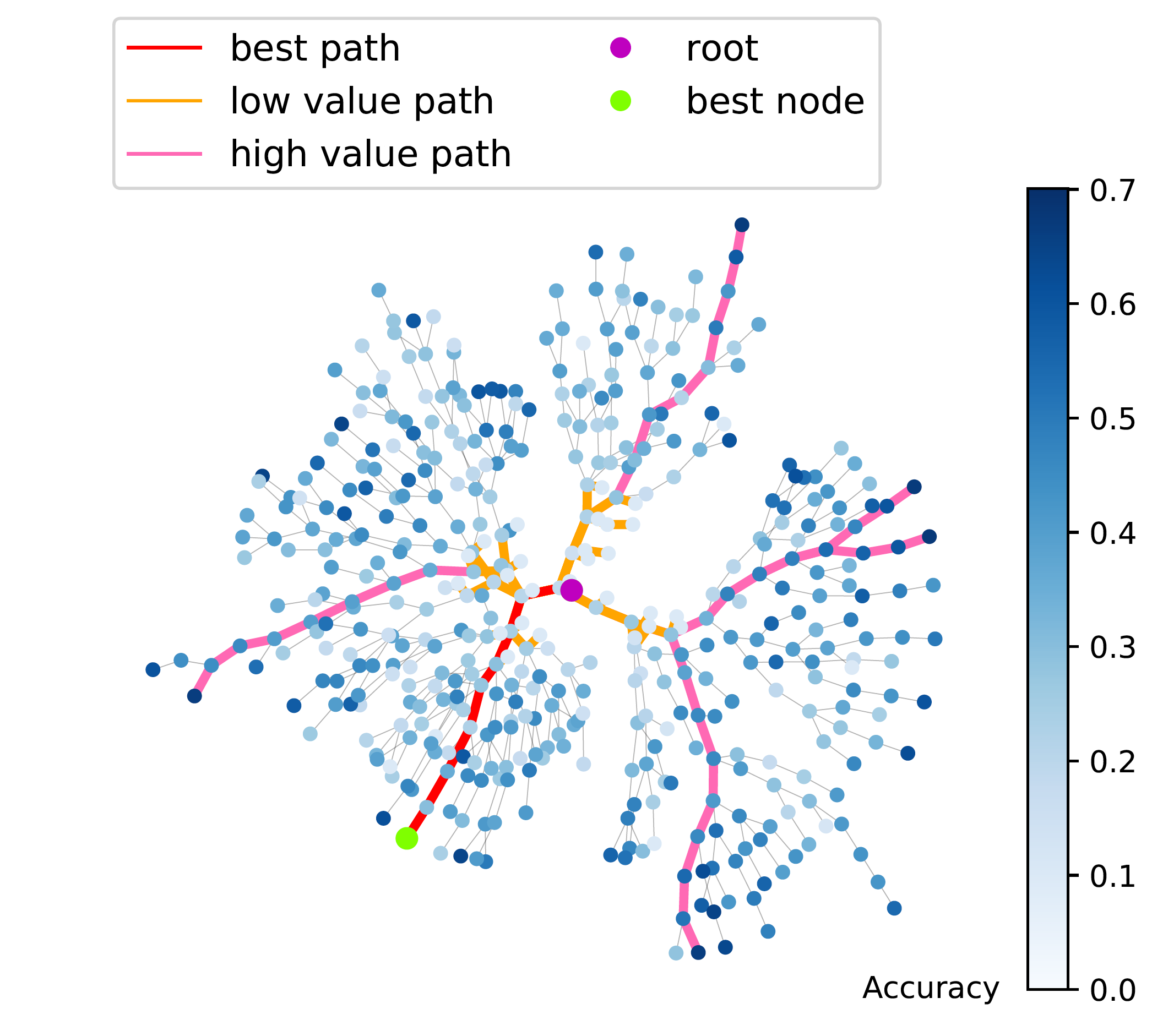
However, this work still needs explicitly defines actions, which is not optimized toward a performance metric. Our recent work has successfully solved this issue and has shown orders of improvement in sample efficiency (LaNAS), https://linnanwang.github.io/latent-actions.pdf. We will release LaNAS under the repositories of Facebook AI Research soon.
The work has been published in AAAI-20; please cite our work, if it helps your research ;)
@article{wang2019alphax,
title={Alphax: exploring neural architectures with deep neural networks and monte carlo tree search},
author={Wang, Linnan and Zhao, Yiyang and Jinnai, Yuu and Tian, Yuandong and Fonseca, Rodrigo},
journal={arXiv preprint arXiv:1903.11059},
year={2019}
}
the best architecture in the search, AlphaX-1, 97.2 test accuracy on CIFAR-10 (the latest is 98, will update later)
Go to folder alphax-1-net,
python model_test.py
Final top_1 test accuracy is 97.22 Final top_5 test accuracy is 99.95
Python >= 3.5.5, numpy >= 1.9.1, keras >= 2.1.6, jsonpickle
- Clone this repo.
git clone [email protected]:linnanwang/AlphaX-NASBench101.git
cd AlphaX-NASBench101
After 78 batches, you will get: Final top_1 test accuracy is 97.22 Final top_5 test accuracy is 99.95
- (optional) Create a virtualenv for this library.
virtualenv --system-site-packages -p python3 ./venv
source venv/bin/activate
- Install the project along with dependencies.
pip install numpy
pip install keras
pip install jsonpickle
The full NASBench dataset in our format is at here. Please place the dataset into the same directory of AlphaX-NASBench101.
After preparing all dependencies, execute the following commands to start the search:
MCTS without meta_DNN (Fast on CPU)
python MCTS.py
MCTS with meta_DNN assisted (Slow, and please run on GPU.)
python MCTS_metaDNN.py
Note: meta_DNN requires training to predict the accuracy of an unseen architecture. Running it toward GPU is highly recommended.
By default, we constrain the nodes <= 6, that consists of 60000+ valid networks. The following steps illustrate how to expand or shrink the search domain.
- In arch_generator.py, changing the MAX_NODES to any in [3, 4, 5, 6, 7] (line 20). NASBench-101 provides all the networks up to 7 nodes.
class arch_generator:
MAX_NODES = 6 #inclusive
MAX_EDGES = 9 #inclusive- Also lines from 74-80 in net_training.py defines the search target. The search stops once it hits the target. The target consists of two parts, the adjacent matrix, and the node list. Please change it to a different target after you changing the maximal nodes.
# 6 nodes
t_adj_mat =
[[0, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 1, 0],
[0, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 0]]
t_node_list = ['input', 'conv3x3-bn-relu', 'conv3x3-bn-relu', 'conv3x3-bn-relu', 'conv3x3-bn-relu', 'output']Linnan Wang, Brown University, Yiyang Zhao, WPI,
We're also sincerely grateful for the valuable suggestions from Yuu Jinnai (Brown), Yuandong Tian(Facebook AI Research), and Rodrigo Fonseca (my awesome advisor at Brown).