Workflow is essentially Galaxy+CodaLab, where you can create complex computation pipelines by editing a flowchart and submit the generated commands to a CodaLab instance.
- A demo page.
- A working Workflow instance which uses CodaLab instance at worksheets.codalab.org.
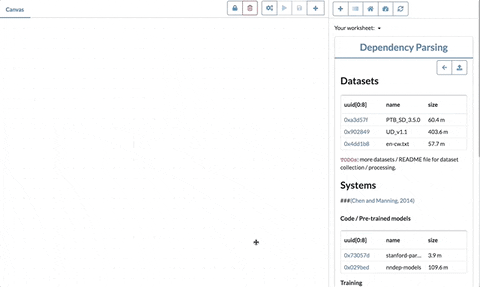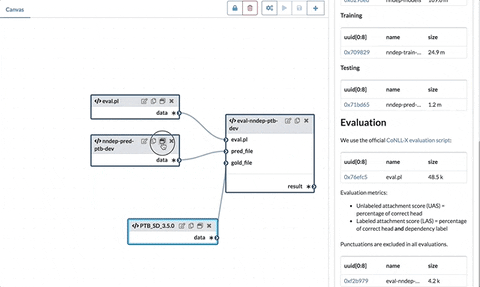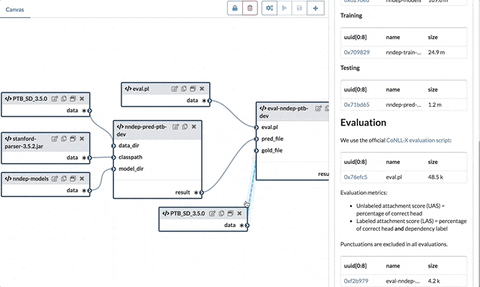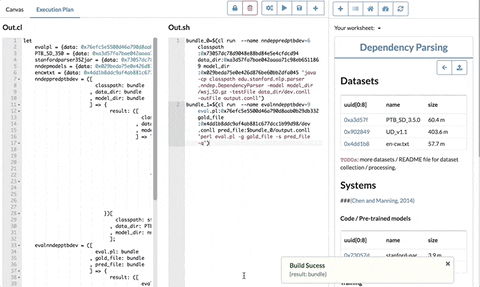
Interested? Try it yourself in the demo page
- Screenshots
- Tutorial
- Why using Workflow
- How it works
- Backend Setup
- Start your own instance
- Build from source
Visit the demo page for a work through of the application.
Galaxy is a well-known workflow manager platform in the bioinformatics community. The flowchart interface of Workflow is inspired by the Galaxy one. The main advantages of Workflow over Galaxy is that Workflow is built on top of CodaLab. Because of using CodaLab, computation results in Workflow can be easily shared and reproduced. In Workflow, users can define their own tools with arbitrary shell commands. While in galaxy, users normally can only access predefined tools managed by administrators.
As will be mentioned later, Workflow is based on a typed programming language CodaLang. The flowchart in Workflow is actually a CodaLang expression. This means tools in Workflow can be composed and reused in a principled way. For example, in Workflow you can turn a complex flowchart in a function and use it as a single node when creating new pipelines. This is not possible in Galaxy.
Workflow is built on top of CodaLab. In a way it can be viewed as providing an alternative graphical programming interface for CodaLab. In Workflow, you can view, edit your pipeline and submit jobs in a more intuitive way. You can even visualize the dependencies of an existing run bundle and make changes in the Workflow interface.
The core functionality of Workflow is powered by CodaLang, a DSL
that targets CodaLab cl command. Each node in the flowchart has an underlining CodaLang expression, which is called node expression. A flowchart in Workflow is essentially a representation of a large CodaLang expression composed from the node expressions in each individual node.
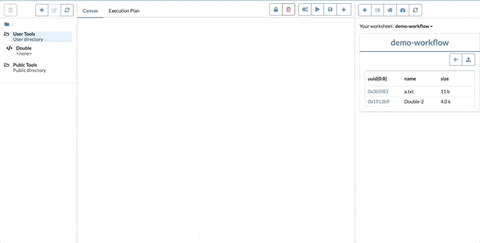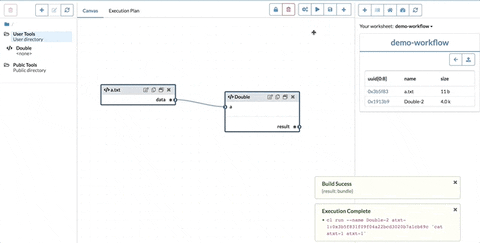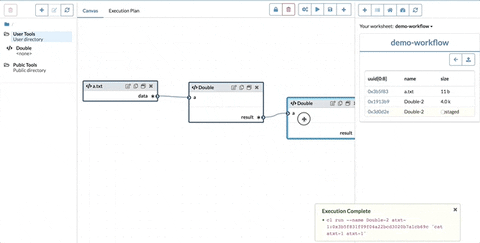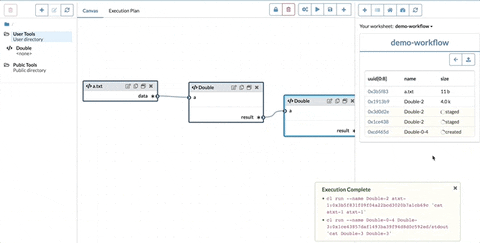
For example, suppose we have the following flowchart on the canvas:

It is a simple pipeline to replicate the content of the data file three times. As mentioned before, each node contains a node expression.
The data node is a value node, meaning its node expression is not a function and it doesn't have input ports.
The Double and Append are function nodes as their node expressions are functions. Their input ports correspond to the function arguments and the inward connections indicate where the argument values come from. In this example, the Double node only takes one argument from data and the two arguments of the Append node come from output of Double and data.
Finally, the whole graph will be built into a large CodaLang expression itself. The basic strategy is to generate a let expression where we assign each node expression to its node name.
As we have seen before, the node expression can be either a function or a regular value. In this step, we will eliminate the function expressions by applying them to the values that are determined from the inward connections.
In the above example, the Double node is a function node, it receive connection from data in the port a. We will therefore transform its node expression to ([a: bundle] => @cat $a $a@/stdout)[a: data]. Basically apply data to the function. Similarly, the node expression in Append will become ([a: bundle, b: bundle] => @cat $a $b@/stdout)[a:Double, b: data], i.e. use variables Double and data as arguments.
Since there is no function left, the last step is simply assigning the node expressions to their node names in a let expression in topological order. The above example will generate:
let
data = 0x970966d1df534291862ba86bbfd5717f;
Double = ([a: bundle] => @cat ${a} ${a}@/stdout)[a: data]; # apply data to the function
Append = ([a: bundle, b: bundle] => @cat $a $b@/stdout)[a: Double, b: data]; # apply Double and data
in
AppendThe process above is a bit simplified. In the real implementation, in order to deal with multiple outputs, the actual node expression is either a record or a function that returns a record. It slightly complicate the whole process but the basic idea is the same.
If there are unfilled input ports in the graph, Workflow will try to build the graph to a CodaLang function by treating those unfilled ports as arguments. You can also explicitly create argument nodes in the flowchart.
Workflow is based on CodaLab, it needs to constantly communicate with the CodaLab instance for operations like fetching bundles/worksheets information and submitting jobs. It also requires its own backend server to persistently save user-defined graphs and tools, compile CodaLang code, serve static contents and so on. It can get complicate with authentication and CORS restriction when there are two separate servers inthe backend. The current configuration is:

The CodaLab and Workflow backend are brought together behind a same url by reverse proxy, so the frontend can directly communicate with both servers.
Authentication is a tricky process. As we have seen before, there are two separate servers: CodaLab and Workflow backend. In order to authenticate with the two servers at the same time, the current process looks like this:

In this setting, users can just use their CodaLab accounts for authentication. The frontend will first post the credential information to the Workflow Backend (Step 1 and Step 2). The Workflow Backend will then try to authenticate with CodaLab with this information (Step 3). If success, CodaLab server will return a cookie token called "codalab_session" (Step 4). If the Workflow Backend receives this cookie, it will generate its own JWT cookie encoding relevant information. Finally, it will reply both cookies to the frontend (Step 5 and 6).
If the above process succeed, the frontend will get two cookies and can use them to directly communicate with both servers.
You can easily set up everything with a simple docker-compose command. Go to the Workflow Docker repository for more details.
yarn install
npx webpack
mkdir -p build
cp -r dist build
cp index.production.html build/index.html
Please refer to the backend repository.