- awesome-deep-reinforcement-learning
- General Machine Learning (ML)
- Neural Networks (NN) and Deep Neural Networks (DNN)
- Reinforcement Learning (RL) and Deep Reinforcement Learning (DRL)
- Evolutionary Algorithms (EA)
- Misc Tools
- Similar pages
Curated list for Deep Reinforcement Learning (DRL): software frameworks, models, datasets, gyms, baselines...
To accomplish this, includes general Machine Learning (ML), Neural Networks (NN) and Deep Neural Networks (DNN) with many vision examples, and Reinforcement Learning (RL) with videogames/robotics examples. Some alternative Evolutionary Algorithms (EA) with similar objectives included too.
- scikit-learn (API: Python)
- scikit-image (API: Python)
- microsoft/DirectML (API: C++, Python)
- Jake VanderPlas, "Python Data Science Handbook", 2017. safari
- Overview: presentation (permalink).
- Docker images with several pre-installed software frameworks: 1, 2, 3.
- Projects to port trained models from one software framework to another: 1
Attempling to order software frameworks by popularity (in practice should look at more aspects such as last updates, forks, etc):
- pytorch/pytorch PyTorch (API: Python) (support: Facebook AI Research).
- keras-team/keras Keras (layer over: TensorFlow, theano...) (API: Python) (support: Google). wikipedia
- tensorflow/tensorflow TensorFlow (low-level) (API: Python most stable, JavaScript, C++, Java...) (support: Google).
- Tutorials: 1
- flashlight/flashlight
- https://github.com/janhuenermann/neurojs
- ONNX
- OpenCV has DNN: https://docs.opencv.org/3.3.0/d2/d58/tutorial_table_of_content_dnn.html
- Chainer (GitHub) (API: Python) (support: Preferred Networks)
- Define-by-Run rather than Define-and-Run.
- In addition to chainerrl below, there is also a chainercv: 1
- DALI (NVIDIA/DALI): A GPU-accelerated library containing highly optimized building blocks and an execution engine for data processing to accelerate deep learning training and inference applications.
- Sonnet (GitHub) (layer over: TensorFlow) (API: Python) (support: DeepMind)
- MXNet (API: Python, C++, Clojure, Julia, Perl, R, Scala) (support: Apache)
- Tutorial: 1
- Darknet (API: C)
- ml5 (API: JavaScript) (a tensorflow.js wrapper)
- DL4J (API: Java)
- oneapi-src/oneDNN (API: C++)
- sony/nnabla (API: C++)
- Torch (API: Lua) (support: Facebook AI Research).
- Multi-layer Recurrent Neural Networks (LSTM, GRU, RNN) for character-level language models: 1
- jittor (API: Python)
- PaddlePaddle: PArallel Distributed Deep LEarning
- CoreML (API: Objective-C) (support: Apple)
- Tensorpack (GitHub) (a tensorflow wrapper)
- Ignite (GitHub) (a pytorch wrapper)
- TransmogrifAI (GitHub) (API: Scala)
- tiny-dnn (GitHub) (API: C++ (C++14))
- OpenNN (API: C++)
- PyBrain (API: Python)
- Caffe (very used, but down here because caffe2 merged into pytorch)
- theano (very used, but down here because MILA stopped developing)
- Still many tutorials: https://github.com/lisa-lab/DeepLearningTutorials










- Detectron (2018). Ross Girshick et Al; FAIR. facebookresearch/Detectron and facebookresearch/detectron2
- FCIS (2017). "Fully Convolutional Instance-aware Semantic Segmentation". arxiv. Coded in caffe but released in mxnet, port: chainer.
- U-Net (2015); Olaf Ronneberger et Al; "Convolutional Networks for Biomedical Image Segmentation"; arxiv. caffe.
- YOLO (2015). Joseph Redmond et Al; U Washington, Allen AI, FAIR; "You Only Look Once: Unified, Real-Time Object Detection"; arxiv. Variants: YOLO9000, YOLO v3... Darknet, ports: tensorflow.
- SSD (2015). Wei Liu et Al; UNC, Zoox, Google, et Al; "SSD: Single Shot MultiBox Detector"; arxiv. caffe
- OverFeat (2015). Pierre Sermanet, David Eigen, Xiang Zhang, Michael Mathieu, Rob Fergus, and Yann LeCun; NYU; "OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks"; arxiv.
- R-CNN (2013). Ross Girshick et Al; Berkeley; "Rich feature hierarchies for accurate object detection and semantic segmentation"; arxiv. Variants (summary): Fast R-CNN, Faster R-CNN, Mask R-CNN.
- EfficientNets (2019). Mingxing Tan and Quoc V. Le; Google; "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks"; arxiv.
- MobileNets (2017). Andrew Howard et Al; Google; "MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications"; arxiv.
- DenseNets (2017). Gao Huang et Al; "Densely Connected Convolutional Networks"; arxiv. torch includes links to ports.
- ResNet (2015). Kaiming He et Al; Microsoft Research; "Deep Residual Learning for Image Recognition"; arxiv. Introduces "Residual Blocks" via "Skip Connections" (some cite similarities with GRUs), and additionally uses heavy batch normalization. Variants: ResNet50, ResNet101, ResNet152 (correspond to number of layers). 25.5 million parameters.
- VGGNet (Sept 2014). Karen Simonyan, Andrew Zisserman; Visual Geometry Group (Oxford); "Very Deep Convolutional Networks for Large-Scale Image Recognition"; arxiv. Input: 224x224x3. Conv/pool and fully connected. Variants: VGG11, VGG13, VGG16, VGG19 (correspond to number of layers); with batch normalization. 138 million parameters; trained on 4 Titan Black GPUs for 2-3 weeks.
- GoogLeNet/InceptionV1 (Sept 2014). Christian Szegedy et Al; Google, UNC; "Going Deeper with Convolutions"; arxiv. 22 layer deep CNN. Only 4-7 million parameters, via smaller convs. A more aggressive cropping approach than that of Krizhevsky. Batch normalization, image distortions, RMSprop. Uses 9 novel "Inception modules" (at each layer of a traditional ConvNet, you have to make a choice of whether to have a pooling operation or a conv operation as well as the choice of filter size; an Inception module performa all these operations in parallel), and no fully connected. Trained on CPU (estimated as weeks via GPU) implemented in DistBelief (closed-source predecessor of TensorFlow). Variants (summary): v1, v2, v4, resnet v1, resnet v2; v9 (slides). Also see Xception (2017) paper.
- NIN (2013). Min Lin et Al; NUSingapore; "Network In Network"; arxiv. Provides inspiration for GoogLeNet.
- ZFNet (2013). Matthew D Zeiler and Rob Fergus; NYU; "Visualizing and Understanding Convolutional Networks"; doi, arxiv. Similar to AlexNet, with well-justified finer tuning and visualization (namely Deconvolutional Network).
- AlexNet (2012). Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton; SuperVision (UToronto); "ImageNet Classification with Deep Convolutional Neural Networks"; doi. In 224x224 (227x227?) color patches (and their horizontal reflections) from 256x256 color images; 5 conv, maxpool, 3 full; ReLU; SVD with momentum; dropout and data augmentation. 60-61 million parameters, split into 2 pipelines to enable 5-6 day GTX 580 GPU training (while CPU data augmentation).
- LeNet-5 (1998). Yann LeCun et Al; ATT now at Facebook AI Research; "Gradient-based learning applied to document recognition"; doi. In 32x32 grayscale; 7 layer (conv, pool, full...). 60 thousand parameters.
- thunlp/GNNPapers
- Geometric deep learning
- chihming/awesome-network-embedding
- DLG: dmlc/dgl
- "Signed Graph Convolutional Network" (ICDM 2018); pytorch
- tensorflow/gnn
Tutorial: pytorch
- Auto-Regressive Generative Models: PixelRNN, PixelCNN++... ref
- Deep Dream. caffe
- Style Transfer:
- Tutorial: tensorflow
- Fujun Luan et Al (2018), "Deep Painterly Harmonization"; arxiv. torch+matlab
- Deep Photo Style Transfer (2017). Fujun Luan et Al, "Deep Photo Style Transfer"; arxiv. torch+matlab
- Neuralart (2015). Leon A. Gatys et Al; "A Neural Algorithm of Artistic Style"; arxiv. Uses base+style+target as inputs and optimizes for target via BFGS. tensorflow, torch, keras 1 2 3 4
- GANs:
- hindupuravinash/the-gan-zoo
- BigGAN (2018); "Large Scale GAN Training for High Fidelity Natural Image Synthesis"; arxiv. pytorch
- Terro Karas et Al (2018); NVIDIA; "Progressive Growing of GANs for Improved Quality, Stability, and Variation"; arxiv. tensorflow
- CANs (2017). Ahmed Elgammal et Al; Berkeley; "CAN: Creative Adversarial Networks, Generating "Art" by Learning About Styles and Deviating from Style Norms"; arxiv. tensorflow
- CycleGAN (2017). Jun-Yan Zhu et Al; Berkeley; "Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks". torch and migrated to pytorch.
- DCGAN (2015). Alec Radford, Luke Metz, Soumith Chintala; Indico Research, Facebook AI Research; "Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks"; arxiv.
- GAN (2014). Ian J. Goodfellow et Al; Université de Montréal; "Generative Adversarial Nets"; arxiv.
- Audio synthesis
Can be trained via Back Propagation Through Time (BPTT). Also see Connectionist Temporal Classification (CTC). Cells include: SimpleRNN (commonly has TanH activation as second derivative decays slowly to 0), Gated Recurrent Units (GRU), Long short-term memory (LSTM), ConvLSTM2D, LSTM with peephole connection; keras.
- Recurrent Neural Networks (RNN).
- Bidirectional RNN.
- Stateful RNN.
- BERT
- ELMo
- GloVe (2014). Jeffrey Pennington et Al; Stanford; "GloVe: Global Vectors for Word Representation".
- word2vec (2013). Tomas Mikolov et Al; Google; "Distributed Representations of Words and Phrases and their Compositionality".
- Regression Networks (essentialy same, remove last activation and use some loss such as MSE rather than binary/categorical cross-entropy).
- Autoencoders (AE), Variational Autoencoders (VAE), Denoising Autoencoders.
- Memory Networks. Use "Memory Units".
- Capsule Networks. Use "Capsules". wikipedia
- Echo-state networks.
- Restricted Boltzmann Machine (RBM).
- AutoML.
Lists of lists before citing the classics:
- awesomedata/awesome-public-datasets
- Wikipedia: https://en.wikipedia.org/wiki/List_of_datasets_for_machine_learning_research
- Google: https://ai.google/tools/datasets
- Kaggle: https://www.kaggle.com/datasets
- MIT: MIT Places, MIT Moments...
- UCI: https://archive.ics.uci.edu/ml/datasets.html
- Zillow: https://www.zillow.com/research/data
- Open Graph Benchmark: https://ogb.stanford.edu
- https://data.world
- https://mbejda.github.io/
- MNIST: Handwritten digits, set of 70000 28x28 images, is a subset of a larger set available from NIST (and centered from its 32x32). Also see 2018's Kuzushiji-MNIST.
- ImageNet: Project organized according to the WordNet hierarchy (22000 categories). Includes SIFT features, bounding boxes, attributes. Currently over 14 million images, 21841 cognitive synonyms (synsets) indexed, goal of +1000 images per synset.
- ImageNet Large Visual Recognition Challenge (ILSVRC): Goal of 1000 categories using +100000 test images. E.g. LS-LOC
- PASCAL VOC (Visual Object Classes)
- CIFAR-10: 60000 32x32 colour images (selected from MIT TinyImages) in 10 classes, with 6000 images per class
- CIFAR-100: 60000 32x32 colour images (selected from MIT TinyImages) in 100 classes containing 600 images per class, grouped into 20 superclasses
- MIT MM Stimuli: Massive Memory (MM) Stimuli contains Unique Objects, State Pairs, State x Color Pairs...
- SVHN (Street View House Numbers)
- HICO (Humans Interacting with Common Objects)
- Visual Genome: Includes structured image concepts to language
- COCO (Common Objects in Context): 2014, 2015, 2017. Includes classes and annotations.
- KIT Motion-Language: https://motion-annotation.humanoids.kit.edu/dataset
- Sketches: Quick Draw (Google)
- Driving: https://robotcar-dataset.robots.ox.ac.uk/datasets/
- Robotics: iCubWorld; where iCWT: 200 domestic objects in 20 categories (11 categories also in ILSVRC, rest in ImageNet). Also muratkrty/iCub-camera-dataset.
- Kinetics (DeepMind)
- HowTo100M
- text8: text8.zip. more at word2vec.
- Sentiment Classification: UMICH SI650
- Treebanks (text with part-of-speech (POS) tags): wikipedia, Penn Treebank
- Facebook bAbI tasks: https://research.fb.com/downloads/babi
- How-We-Swipe Shape-writing Dataset: https://osf.io/sj67f/, DOI: 10.1145/3447526.3472059
- https://benchmarks.ai
- http://rodrigob.github.io/are_we_there_yet/build/classification_datasets_results.html
- https://martin-thoma.com/sota/#computer-vision
- https://robust.vision/benchmark
- brain-research/realistic-ssl-evaluation
- Several pre-trained models: keras web, keras 1, keras 2, pytorch, caffe, ONNX (pytorch/caffe2).
- CIFAR-10 and CIFAR-100:
- CNN trained on CIFAR-100 tutorial: keras
- VGG16 trained on CIFAR-10 and CIFAR-100: keras / keras CIFAR-10 weights / keras CIFAR-100 weights
- ImageNet and ILSVRC:
- VGG16, VGG19, ResNet50, InceptionV3, InceptionResNetV2, Xception trained on ImageNet: keras by keras (permalink) / keras by kaggle / pytorch by kaggle
- VGG16 trained on ImageNet (tutorial): keras
- VGGNet, ResNet, Inception, and Xception trained on ImageNet (tutorial): keras
- VGG16 trained on ILSVRC: caffe by original VGG author / ported (tutorials): tensorflow / keras / keras ImageNet weights
- word2vec: gensim
- glove: http://nlp.stanford.edu/data/glove.6B.zip
- Layers: Dense (aka Fully Connected), Convolutional (1D/2D/3D... keras, advanced: upsampling (e.g. in GANs), dilated causal (aka atrous)(e.g. in WaveNet)), Pooling (aka SubSampling)(1D/2D/3D)(Max, Average, Global Max, Global Average, Average with learnable weights per feature map... keras), Normalisation. Note: Keras implements activation functions, dropout, etc as layers.
- Weight initialization: pretrained (see above section), zeros, ones, constant, normal random, uniform random, truncated normal, variance scaling, orthogonal, identity, normal/uniform as done by Yann LeCun, normal/uniform as done by Xavier Glorot, normal/uniform as done by Kaiming He. keras, StackExchange
- Activation functions: Linear, Sigmoid, Hard Sigmoid, Logit, Hyperbolic tangent (TanH), SoftSign, Rectified Linear Unit (ReLU), Leaky ReLU (LeakyReLU or LReLU), Parametrized or Parametric ReLU (PReLU), Thresholded ReLU (Thresholded ReLU), Exponential Linear Unit (ELU), Scaled ELU (SELU), SoftPlus, SoftMax, Swish. wikipedia, keras, keras (advanced), ref.
- Regularization techniques (reduce overfitting and/or control the complexity of model; may be applied to kernel (weight matrix), to bias vector, or to activity (activation of the layer output)): L1(lasso)/L2(ridge)/ElasticNet(L1/L2)/Maxnorm regularization (keras), dropout, batch and weight normalization, Local Response Normalisation (LRN), data augmentation (image distortions, scale jittering...), early stopping, gradient checking.
- Optimizers: keras, ref
- Gradient descent variants: Batch gradient descent, Stochastic gradient descent (SGD), Mini-batch gradient descent.
- Gradient descent optimization algorithms: Momentum, Nesterov accelerated gradient, Adagrad, Adadelta, RMSprop, Adam, AdaMax, Nadam, AMSGrad, Eve.
- Parallelizing and distributing SGD: Hogwild!, Downpour SGD, Delay-tolerant Algorithms for SGD, TensorFlow, Elastic Averaging SGD.
- Additional strategies for optimizing SGD: Shuffling and Curriculum Learning, Batch normalization, Early Stopping, Gradient noise.
- Broyden-Fletcher-Goldfarb-Shanno (BFGS)
- Gradient-free: facebookresearch/nevergrad
- Error/loss functions: keras
- Accuracy used for classification problems: binary accuracy (mean accuracy rate across all predictions for binary classification problems), categorical accuracy (mean accuracy rate across all predictions for multiclass classification problems), sparse categorical accuracy (useful for sparse targets), top k categorical accuracy (success when the target class is within the top k predictions provided).
- Error loss (measures the difference between the values predicted and the values actually observed, can be used for regression): mean square error (MSE), root square error (RMSE), mean absolute error (MAE), mean absolute percentage error (MAPE), mean squared logarithmic error (MSLE).
- Hinge: hinge loss, squared hinge loss, categorical hinge.
- Class loss, used to calculate the cross-entropy for classification problems: binary cross-entropy (binary classification), categorical cross-entropy (multi-class classification), sparse categorical cross-entropy. wikipedia
- Logarithm of the hyperbolic cosine of the prediction error (logcosh), kullback leibler divergence, poisson, cosine proximity.
- Metric functions: usually same type as error/loss functions, but used for evaluationg rather than training. keras
- Cross-validation: hold-out, stratified k-fold. wikipedia.
- Transfer learning. tensorflow, keras
- tensorboard
- tensorboardX: tensorboard for pytorch, chainer, mxnet, numpy...
- Keras: keras, 1, 2, 3, 4
- Tensorflow: tensorflow online demo
- Pytorch: loss-landscape, gandissect
- Caffe: netscope / cnnvisualizer
- SHAP (SHapley Additive exPlanations): slundberg/shap
- XAI (An eXplainability toolbox for machine learning): EthicalML/xai
Classification of RL algorithms adapted from Reinforcement Learning Specialization (Martha & Adam White, from University of Alberta and Alberta Machine Intelligence Institute, on Coursera, 2019-20). Note that another major separation is off/on policy RL algorithms. DRL methods would fit into function approximators.
+-- Tablular Methods
| +-- Average Reward (e.g. for Continuing Tasks a.k.a. Infinite Horizon Case)
| | +-- Continuous Action Space
| | | +-- Gaussian Actor-Critic
| | +-- Discrete Action Space
| | +-- Softmax Actor-Critic
| | +-- Differential Semi-Gradient SARSA
| +-- Not using Average Reward (e.g. for Episodic Tasks a.k.a. Finite Horizon Case)
| +-- Learn at each time step
| | +-- Control Problem
| | | +-- Expected SARSA
| | | +-- Q-Learning
| | | +-- SARSA
| | +-- Not a Control Problem
| | +-- Semi-Gradient TD
| +-- Not learn at each time step
| +-- Gradient Monte Carlo
+-- Function Approximator Methods
+-- Access to a model (model-based, part 1/2)
| +-- Control Problem
| | +-- Value Iteration
| | +-- Policy Iteration
| +-- Not a Control Problem
| | +-- Iterative Policy Evaluation
+-- No access to a model
+-- Will learn a model (model-based, part 2/2)
| +-- Q-Planning
| +-- Dyna-Q+
| +-- Dyna-Q
+-- Model-free
+-- Learn at each time step
| +-- Control Problem
| | +-- Q-Learning
| | +-- Expected SARSA
| | +-- SARSA
| +-- Not a Control Problem
| +-- TD
+-- Not learn at each time step
+-- Control Problem
| +-- eplsilon-soft Monte Carlo
| +-- Exploring starts Monte Carlo
+-- Not a Control Problem
+-- Off-Policy Monte Carlo
+-- Monte Carlo Prediction
DRL algorithm classification adapted from Deep Reinforcement Learning CS 285 at UC Berkeley, Sergey Levine, Fall 2020, Lecture 4.
- Policy Gradients
- Value-based
- Actor-critic
- Model-based RL
- Part 2: Kinds of RL Algorithms <- Rendered from https://github.com/openai/spinningup/blob/038665d62d569055401d91856abb287263096178/docs/spinningup/rl_intro2.rst
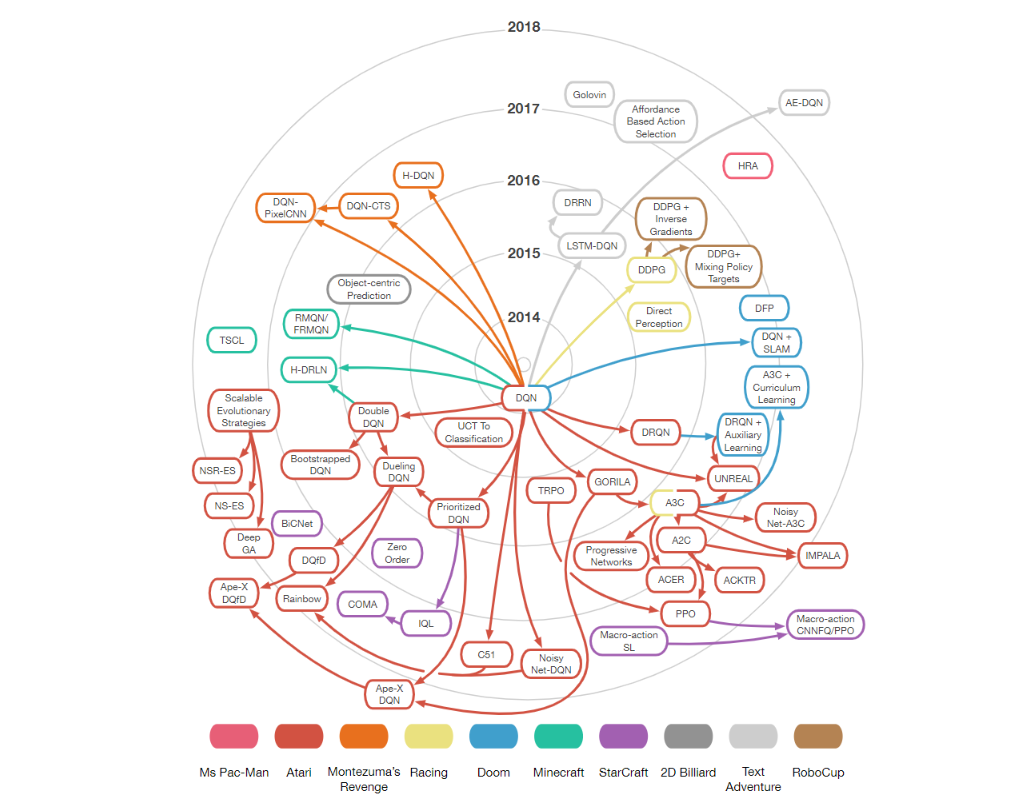
REINFORCE (on-policy policy gradient; Williams, 1992), Deep Q-Network (DQN), Expected-SARSA, True Online Temporal-Difference (TD), Double DQN, Truncated Natural Policy Gradient (TNPG), Trust Region Policy Optimization (TRPO), Reward-Weighted Regression, Relative Entropy Policy Search (REPS), Cross Entropy Method (CEM), Advantage-Actor-Critic (A2C), Asynchronous Advantage Actor-Critic (A3C), Actor-critic with Experience Replay (ACER), Actor Critic using Kronecker-Factored Trust Region (ACKTR), Generative Adversarial Imitation Learning (GAIL), Hindsight Experience Replay (HER), Proximal Policy Optimization (PPO, PPO1, PPO2), Ape-X Distributed Prioritized Experience Replay, Continuous DQN (CDQN or NAF), Dueling network DQN (Dueling DQN), Deep SARSA, Multi-Agent Deep Deterministic Policy Gradient (MADDPG), Deep Deterministic Policy Gradient (DDPG), Truncated Quantile Critics (TQC), Quantile Regression DQN (QR-DQN).
Attempting to order by popularity (in practice should look at more aspects such as last updates, forks, etc):
- RLlib (part of Ray): ray-project/ray (readthedocs (rllib))
(Ray total) (also covers multiagent)
- Unity-Technologies/ml-agents (Environments, Algorithms) (includes design of environments)
- google/dopamine (uses jax, tensorflow, keras)
- keras-rl/keras-rl (uses keras)
- thu-ml/tianshou (https://tianshou.readthedocs.io)
- DLR-RM/stable-baselines3 (advanced from hill-a/stable-baselines fork of openai/baselines)
- https://github.com/janhuenermann/neurojs
- deepmind/open_spiel (uses some tensorflow)
- reinforceio/tensorforce (uses tensorflow)
- deepmind/trfl (uses tensorflow)
- catalyst-team/catalyst
- deepmind/acme
- rll/rllab (readthedocs) (officialy uses theano; in practice has some keras, tensorflow, torch, chainer...)
- TF-Agents: tensorflow/agents (uses tensorflow)
- astooke/rlpyt (uses pytorch)
- rail-berkeley/rlkit
- vwxyzjn/cleanrl
- oxwhirl/pymarl (support: http://whirl.cs.ox.ac.uk): deep multi-agent reinforcement learning
- deepmind/bsuite (Environments, Algorithm Implementations, Benchmarking)
- chainer/chainerrl (API: Python)
- facebookresearch/rl (uses pytorch)
- MushroomRL/mushroom-rl
- SurrealAI/surreal (API: Python) (support: Stanford Vision and Learning Lab).
- medipixel/rl_algorithms
- ikostrikov/jaxrl2
- ikostrikov/jaxrl (uses JAX)
- ikostrikov/jaxrl (uses JAX)
- tinkoff-ai/CORL "High-quality single-file implementations of SOTA Offline RL algorithms: AWAC, BC, CQL, DT, EDAC, IQL, SAC-N, TD3+BC"
- learnables/cherry (API: Python) (layer over pytorch)
- trackmania-rl/tmrl
- ethanluoyc/magi (uses JAX)
- RL-Glue (Google Code Archive) (API: C/C++, Java, Matlab, Python, Lisp) (support: Alberta)
- http://burlap.cs.brown.edu/ (API: Java)


























































Lower level:
- tensorflow/tensorflow
- pytorch/pytorch https://pytorch.org
- keras-team/keras https://keras.io/
- google/jax: Composable transformations of Python+NumPy programs: differentiate, vectorize, JIT to GPU/TPU, and more.


Specific to Model-based:
- facebookresearch/mbrl-lib: Library for Model Based RL.


For specific algorithms (e.g. original paper implementations):
- haarnoja/sac
- Asap7772/PTR Pre-Training for Robots: Leveraging Diverse Multitask Data via Offline Reinforcement Learning
- ikostrikov/pytorch-a2c-ppo-acktr
Tutorials/education (typically from lower level):
- openai/spinningup (https://spinningup.openai.com, educational, uses pytorch updated from tensorflow)
- qfettes/DeepRL-Tutorials (uses pytorch)
- https://becominghuman.ai/lets-build-an-atari-ai-part-0-intro-to-rl-9b2c5336e0ec (uses keras)
- https://medium.com/@jonathan_hui/rl-reinforcement-learning-algorithms-quick-overview-6bf69736694d




Comparison:
-
Farama-Foundation/Gymnasium (https://gymnasium.farama.org)
.
DEPRECATED: openai/gym, https://gym.openai.com, https://gym.openai.com/docs/- https://github.com/Farama-Foundation/Gymnasium/network/dependents
- Farama-Foundation/Gymnasium-Robotics
- Farama-Foundation/Minigrid
- Farama-Foundation/MiniWorld
- Farama-Foundation/ViZDoom (was mwydmuch/ViZDoom)
- https://gymnasium.farama.org/environments/third_party_environments
DEPRECATED: openai/roboschool- Unity-Technologies/ml-agents (Environments, Algorithms) (includes design of environments)
- Unity-Technologies/obstacle-tower-env
- LucasAlegre/sumo-rl
- qgallouedec/panda-gym
- NVIDIA-Omniverse/IsaacGymEnvs
- leggedrobotics/legged_gym
- osudrl/cassie-mujoco-sim
- utiasDSL/safe-control-gym
- deepmind/bsuite (Environments, Algorithms, Benchmarking)
- openai/gym-soccer
- erlerobot/gym-gazebo
- robotology/gym-ignition
- dartsim/gym-dart
- Roboy/gym-roboy
- kngwyu/mujoco-maze
- Improbable-AI/walk-these-ways
- ucuapps/modelicagym
- openai/safety-gym
- openai/retro
- deepmind/pysc2 (by DeepMind) (Blizzard StarCraft II Learning Environment (SC2LE) component)
- benelot/pybullet-gym
- Healthcare-Robotics/assistive-gym
- Microsoft/malmo
- nadavbh12/Retro-Learning-Environment
- twitter/torch-twrl
- duckietown/gym-duckietown
- arex18/rocket-lander
- ppaquette/gym-doom
- eleurent/highway-env
- thedimlebowski/Trading-Gym
- denisyarats/dmc2gym
- minerllabs/minerl
- eugenevinitsky/sequential_social_dilemma_games
- facebookresearch/minihack
- OpenSim
- Electric Engineering
- koulanurag/ma-gym (multiagent)
- Multi-armed Bandits:
- Another awesome list: Phylliade/awesome-openai-gym-environments
-
Unity ML-Agents


Multi-agent:
- Farama-Foundation/PettingZoo (https://pettingzoo.farama.org)
- Farama-Foundation/MAgent2
- Unity-Technologies/ml-agents (Environments, Algorithms) (includes design of environments)
- LucasAlegre/sumo-rl


With datasets for offline reinforcement learning:
- Farama-Foundation/D4RL (was rail-berkeley/d4rl)
- google-research/rlds
- Farama-Foundation/Minari (was Farama-Foundation/Kabuki)






With low-cost robots:


Reproducible:
- rlworkgroup/garage "A toolkit for reproducible reinforcement learning research."


Metrics/benchmarks:
- stepjam/RLBench (https://sites.google.com/view/rlbench) "A large-scale benchmark and learning environment."
- google-research/rliable (https://agarwl.github.io/rliable) "reliable evaluation on RL and ML benchmarks, even with only a handful of seeds"
- google-research/rl-reliability-metrics "provides a set of metrics for measuring the reliability of reinforcement learning (RL) algorithm"
- HYDesmondLiu/B2RL "Building Batch Reinforcement Learning Dataset"
- https://martin-thoma.com/sota/#reinforcment-learning








Other:
- deepmind/bsuite "collection of carefully-designed experiments that investigate core capabilities of a reinforcement learning (RL) agent"
RL
- Reinforcement Learning: An Introduction: http://incompleteideas.net/book/RLbook2020.pdf (Richard S. Sutton is father of RL)
- Andrew Ng thesis: <www.cs.ubc.ca/~nando/550-2006/handouts/andrew-ng.pdf>
- https://www.oreilly.com/learning/introduction-to-reinforcement-learning-and-openai-gym
Only accounting those with same objective as RL.
- https://blog.openai.com/evolution-strategies
- https://eng.uber.com/deep-neuroevolution
- Covariance Matrix Adaptation Evolution Strategy (CMA-ES)
- DLPaper2Code: Auto-generation of Code from Deep Learning Research Papers: https://arxiv.org/abs/1711.03543
- Tip: you can download the raw source of any arxiv paper. Click on the "Other formats" link, then click "Download source"
- http://www.arxiv-sanity.com