CPR refers to "C"ontext Partition, "P"ointer Network, and "R"eranker Partition.
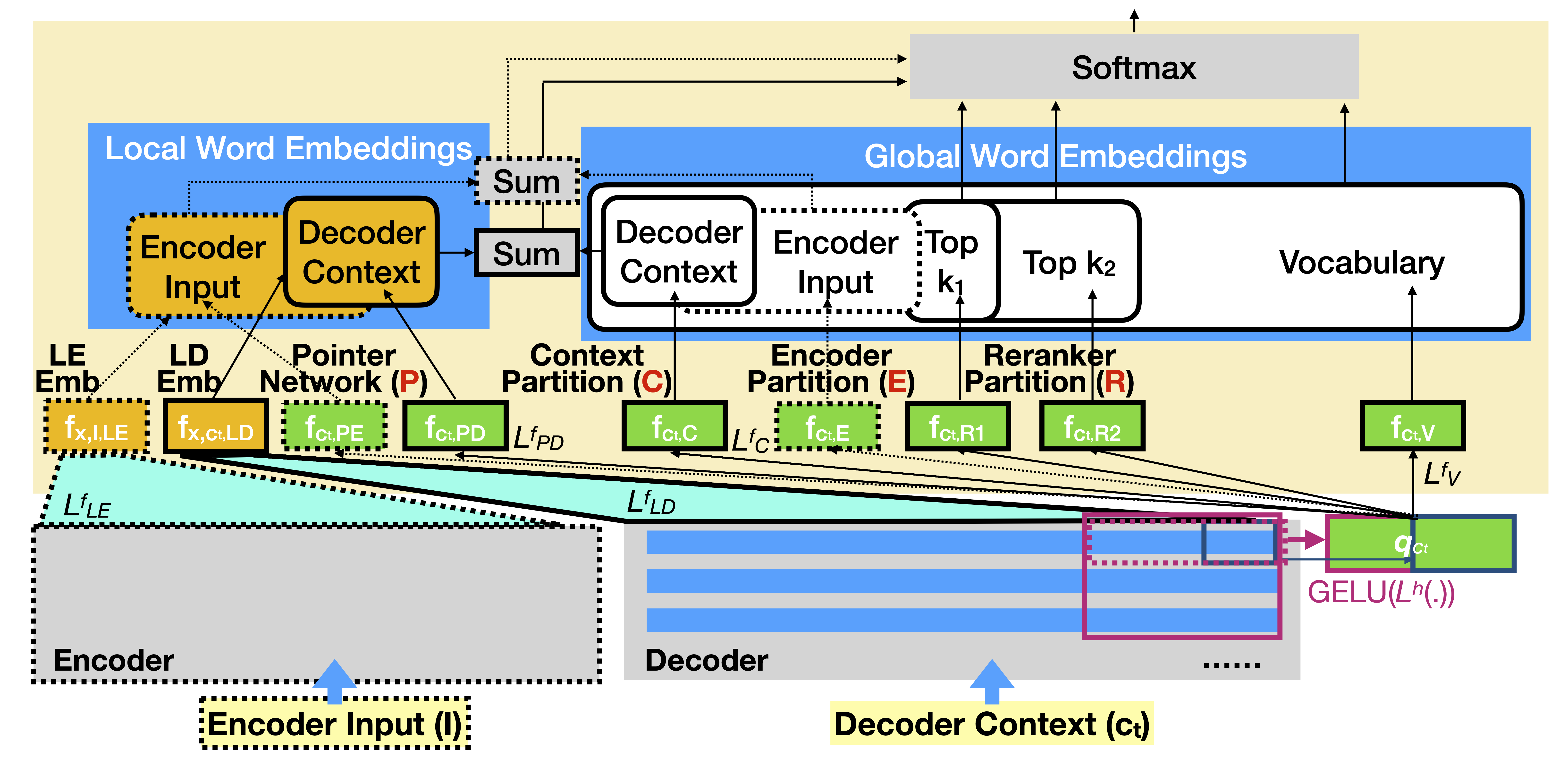
The softmax bottleneck (Chang and McCallum (2022)) sometimes prevents the language models from predicting the desired distribution and the pointer networks can be used to break the bottleneck efficiently. Based on the finding, we propose the context/encoder partition by simplifying the pointer networks and the reranker partition to accelerate the word-by-word rerankers. By combining these softmax alternatives, softmax-CPR is significantly better and more efficient than mixture of softmax (MoS) in GPT-2, a state-of-the-art softmax alternative. In summarization experiments, without significantly decreasing its training/testing speed, softmax-CEPR based on T5-Small improves factCC score by 2 points in CNN/DM and XSUM dataset, and improves MAUVE scores by around 30% in BookSum paragraph-level dataset. Please see our paper for more details: https://arxiv.org/abs/2305.12289.

- Put your text data into ./data (see an small example in ./data/openwebtext_2017_18_small).
- Run the python code src/LM/preprocessing/prepare_gpt2_id_corpus_from_raw.py (change the file paths if necessary) to preprocess your text data
- Run the script ./bin/LM/main.sh (change the python path, data paths, or different configurations if necessary) to train the model
- Compare the validation differences from the log files
- Run the script ./bin/summarization/main.sh (change the python path, data paths, or different configurations if necessary) to train the model
- Compare the validation differences from the log files
If using conda, you can get this to work as follows:
conda create -n rerankLM python=3.8
conda activate rerankLM
conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch (change this 10.2 according to official website https://pytorch.org/)
conda install -c conda-forge matplotlib
conda install -c conda-forge spacy
python -m spacy download en_core_web_sm
conda install pandas
conda install nltk
git clone https://github.com/huggingface/transformers.git
cd transformers
pip install -e .
pip install datasets
@inproceedings{chang2023revisiting,
title={Revisiting the Architectures like Pointer Networks to Efficiently Improve the Next Word Distribution, Summarization Factuality, and Beyond},
abbr={ACL Findings},
author={Haw-Shiuan Chang* and Zonghai Yao* and Alolika Gon and Hong Yu and Andrew McCallum},
booktitle={Findings of the Association for Computational Linguistics: ACL 2023 (Findings of ACL)},
year={2023},
}