Fix ORTTrainer failure on gpt2 fp16 training #18017
Conversation
|
The documentation is not available anymore as the PR was closed or merged. |
 michaelbenayoun
left a comment
michaelbenayoun
left a comment
There was a problem hiding this comment.
LGTM (once all the tests pass)
|
Hello @JingyaHuang By looking this 2 lines
|
|
Hi @ydshieh, yes this issue only occurs with ONNX. When exporting the ONNX IR [EDIT] Here I made a mistake, according to the training graph, actually |

|
And if we run the model with PyTorch backend, there is no problem of the tricky tracing or op definition, it should work fine. |
|
@JingyaHuang Thank you! |
|
Hi @ydshieh, I've just double-checked the debug exported training onnx graph. Actually the The IR corresponding to this line The IR before fix: So this is exactly what we want for fp16 training. |
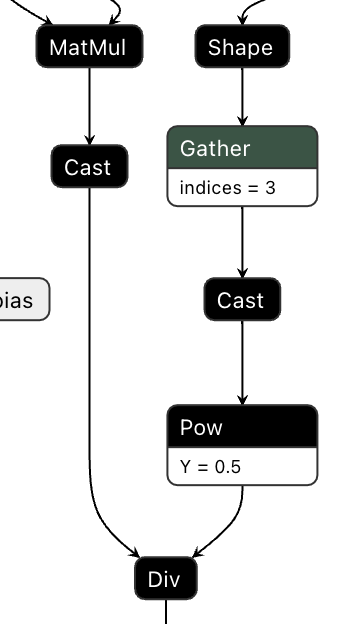
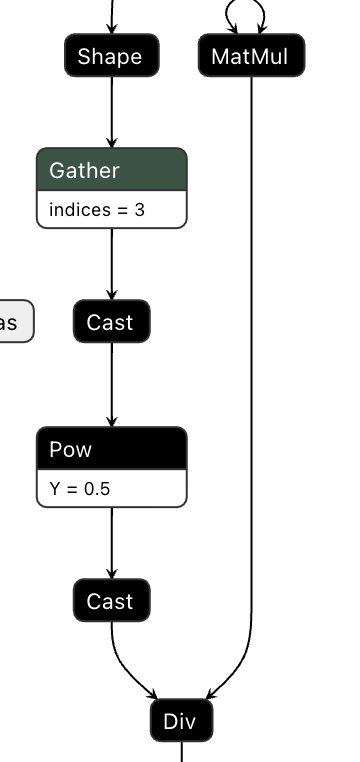
|
Gently pinging @patrickvonplaten and @LysandreJik for a review. |
src/transformers/models/decision_transformer/modeling_decision_transformer.py
Outdated
Show resolved
Hide resolved
Co-authored-by: Lysandre Debut <[email protected]>
|
I got the same error. But I use the torch.fx and amp to train the GPT2 model. I fix this error with the method is add |
|
Hi @TXacs , which version you tried? Could you try to install the latest version on pip install git+https://github.com/huggingface/accelerateand see if you still have the issue (without your fix). Thanks! |
What does this PR do?
Fixes #11279 of onnxruntime
Context
Optimum users reported that the mixed-precision training on gpt2 with
optimum.onnxruntime.ORTTraineris broken since transformers>4.16.0. After investigation, the break comes from the removal offloat()in gpt2 modeling from PR #14321.Reproduction
Run optimum onnxruntime training example run_glue.py with:
python run_glue.py \ --model_name_or_path gpt2 \ --task_name sst2 \ --do_train \ --do_eval \ --fp16 \ --output_dir /tmp/ort-gpt2-sst2/Error Message
As mentioned in the error message, the forward with onnxruntime InferenceSession will fail on a node Where in the graph, which corresponds to the Where op in gpt2 modeling.
And the problem comes from the fact that after removing
float(), during fp16 training, the inputs of Where have different dtype (one in fp32 and one in fp16), which violates the definition in ONNX and leads to the failure.Who can review?
@michaelbenayoun @patrickvonplaten, @LysandreJik
Fix
Ensure
attn_weightsandvaluehas the same type in exported ONNX IR.