Bump gassist-text to 0.0.10#85782
Conversation
There was a problem hiding this comment.
This bump shows the use of web scraping, which is not allowed to be used with Core integrations.

For more information, see: https://github.com/home-assistant/architecture/blob/master/adr/0004-webscraping.md
The existing code does this as well and thus must be adjusted.
../Frenck
|
This integration is calling Google Assistant Service via gRPC. The gRPC returns simple text in supplemental_display_text field and HTML in the AssistResponse.ScreenOut.data field. I could stop parsing the HTML field but a very small fraction of queries (under 5%) have the text field populated when all have the HTML field populated. The main functionality of the integration is to send commands and broadcast messages to Google Assistant. In fact in the current version the text response is only logged in debug logs so it would be fine to stop parsing HTML alltogether. But the upcoming release adds conversation agent which would have a very broken experience without parsing the HTML response. The webscrapping definition per the linked architecture is: "Webscraping is when we use code to mimic a user and log in to a website and get data in Home Assistant. This is usually needed because certain data sources/integrations do not offer an API." This doesn't quite fall in that definition. The integration is using an API that returns a proto and one of its fields holds HTML. Could there be an exception? The HTML parsing is very simple. It just finds the assistant-card-content div and returns its text. If no exception can be made I will have to revert the conversation agent. |
|
The ADR is in place to ban parsing of HTML output (which is used for display) as data. IMHO, this is a violation of it. Let me explain why:
From the codebase you've linked:
It is HTML meant for display, in an HTML-capable/browser-like interface, not for parsing data. Just because the HTML data is provided by an API, doesn't justify the means. Otherwise, I would build very simple API wrappers for fetching parts of websites and restoring all previously removed integrations as well.
I disagree with making an exception. We have removed many more integrations for even simpler parsing. It wouldn't be fair toward others that we have declined and actively removed under this ADR. ../Frenck |
7902fe7 to
b2b405f
Compare
|
Done. I removed HTML parsing from the library. |
b2b405f to
53877e2
Compare
|
Considering the documentation change you've linked to this PR about bubble being empty and considering this part of the code:
Isn't an option to just strip HTML instead of parsing it? ../Frenck |

|
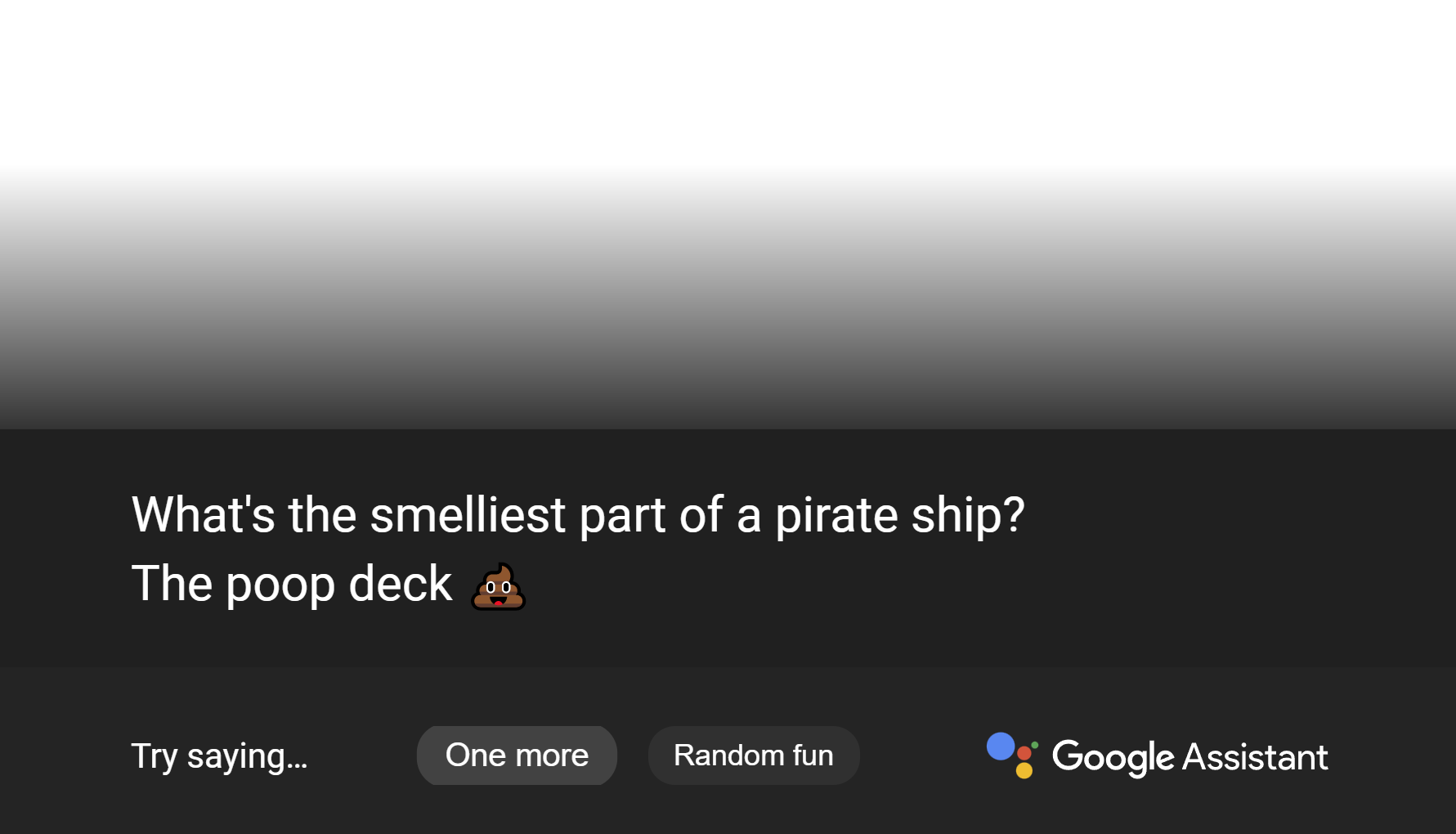
The HTML for some queries includes a "Try saying..." section at the bottom, e.g. Do you want to approve and merge this as is (I need the version bump for #85989 ) and in a follow up PR, depending on what you prefer, either strip the whole HTML or just the relevant div? What's your preferred method for HTML stripping? html.parser.HTMLParser, BeautifulSoup, re, or something else? |
|
I'm not sure. The empty responses/bubbles are just as bad and trying to get rid of that "try saying..." bar will bring use back to interpreting HTML again. IMHO, we should revert the conversation stuff in this case and not ship that feature. Will mark the PR for a second opinion and consult some fellow core maintainers. ../Frenck |
|
Sounds good. FYI, the two options are:
soup = BeautifulSoup(html_response, "html.parser")
text_response = soup.get_text(separator="\n", strip=True)or
soup = BeautifulSoup(html_response, "html.parser")
card_content = soup.find("div", id="assistant-card-content")
text_response = card_content.get_text(separator="\n", strip=True)For the above screenshot, first returns: second returns |
|
Both involve parsing HTML, which isn't allowed. |
|
I thought earlier you suggested HTML stripping which is option 1. There are alternatives to BeautifulSoup but you can't really do stripping without some form of parsing. |
Proposed change
tronikos/gassist_text@0.0.8...0.0.10
Type of change
Additional information
Checklist
black --fast homeassistant tests)If user exposed functionality or configuration variables are added/changed:
If the code communicates with devices, web services, or third-party tools:
Updated and included derived files by running:
python3 -m script.hassfest.requirements_all.txt.Updated by running
python3 -m script.gen_requirements_all..coveragerc.To help with the load of incoming pull requests: