![]()







![]()




You can also join our Discord server! If you found Harmony helpful, you can leave us a review!
- Psychologists and social scientists often have to match items in different questionnaires, such as "I often feel anxious" and "Feeling nervous, anxious or afraid".
- This is called harmonisation.
- Harmonisation is a time consuming and subjective process.
- Going through long PDFs of questionnaires and putting the questions into Excel is no fun.
- Enter Harmony, a tool that uses natural language processing and generative AI models to help researchers harmonise questionnaire items, even in different languages.
Read our guide to contributing to Harmony here or read CONTRIBUTING.md.
You can run the walkthrough Python notebook in Google Colab with a single click:
You can also download an R markdown notebook to run in R Studio:
You can run the walkthrough R notebook in Google Colab with a single click: View the PDF documentation of the R package on CRAN
Check out our examples repository at https://github.com/harmonydata/harmony_examples
Harmony is a tool using AI which allows you to compare items from questionnaires and identify similar content. You can try Harmony at https://harmonydata.ac.uk/app and you can read our blog at https://harmonydata.ac.uk/blog/.
You can contact Harmony team at https://harmonydata.ac.uk/, or Thomas Wood at https://fastdatascience.com/.
Visit: https://harmonydata.ac.uk/app/
You can also visit our blog at https://harmonydata.ac.uk/
Download and install Java if you don't have it already. Download and install Apache Tika and run it on your computer https://tika.apache.org/download.html
java -jar tika-server-standard-2.3.0.jar
You need a Windows, Linux or Mac system with
- Python 3.8 or above
- the requirements in requirements.txt
- Java (if you want to extract items from PDFs)
- Apache Tika (if you want to extract items from PDFs)
You can install from PyPI.
pip install harmonydata
Harmony uses spaCy to help with text extraction from PDFs. spaCy models can be downloaded with the following command in Python:
import harmony
harmony.download_models()
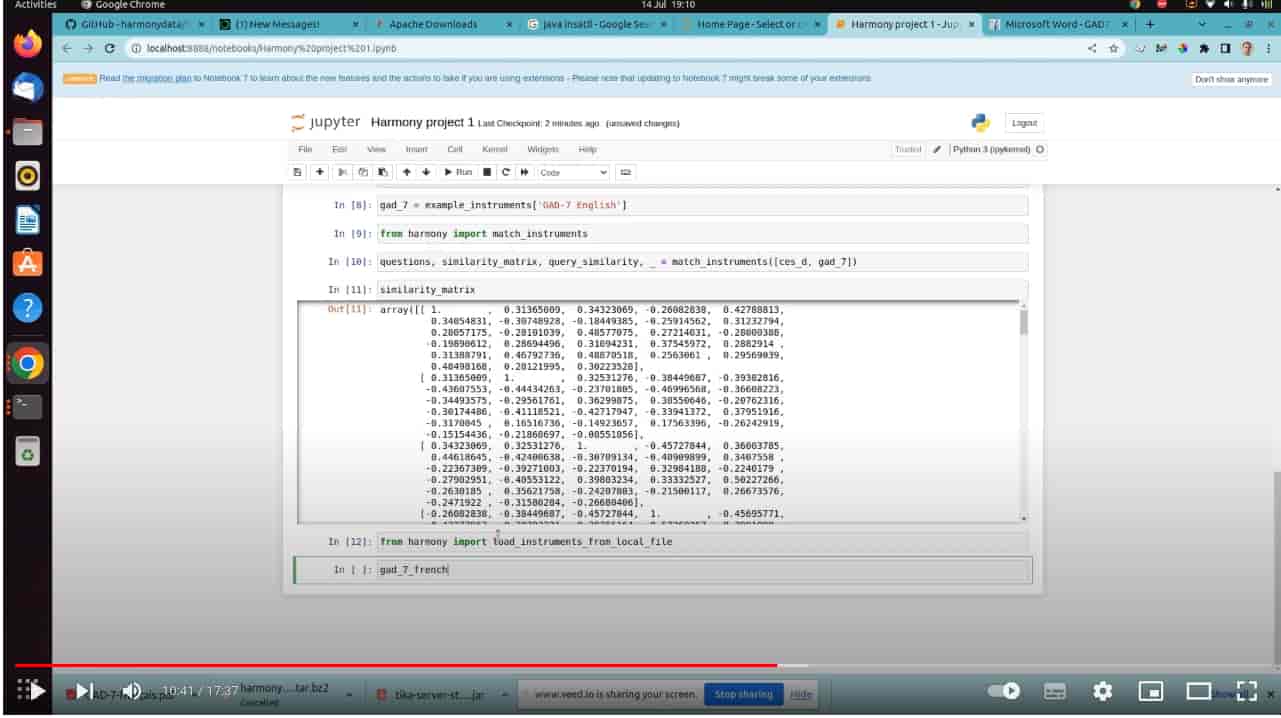
instruments = harmony.example_instruments["CES_D English"], harmony.example_instruments["GAD-7 Portuguese"]
questions, similarity, query_similarity, new_vectors_dict = harmony.match_instruments(instruments)
harmony.load_instruments_from_local_file("gad-7.pdf")
As an alternative to downloading models, you can set environment variables so that Harmony calls spaCy on a remote server. This is only necessary if you are making a server deployment of Harmony.
HARMONY_SPACY_PATH- determines where model files are stored. Defaults toHOME DIRECTORY/harmonyHARMONY_DATA_PATH- determines where data files are stored. Defaults toHOME DIRECTORY/harmonyHARMONY_NO_PARSING- set to 1 to import a lightweight variant of Harmony which doesn't support PDF parsing.HARMONY_NO_MATCHING- set to 1 to import a lightweight variant of Harmony which doesn't support matching.
You can also create instruments quickly from a list of strings
from harmony import create_instrument_from_list, match_instruments
instrument1 = create_instrument_from_list(["I feel anxious", "I feel nervous"])
instrument2 = create_instrument_from_list(["I feel afraid", "I feel worried"])
all_questions, similarity, query_similarity, new_vectors_dict = match_instruments([instrument1, instrument2])
If you have a local file, you can load it into a list of Instrument instances:
from harmony import load_instruments_from_local_file
instruments = load_instruments_from_local_file("gad-7.pdf")
Once you have some instruments, you can match them with each other with a call to match_instruments.
from harmony import match_instruments
all_questions, similarity, query_similarity, new_vectors_dict = match_instruments(instruments)
all_questionsis a list of the questions passed to Harmony, in order.similarityis the similarity matrix returned by Harmony.query_similarityis the degree of similarity of each item to an optional query passed as argument tomatch_instruments.
Harmony defaults to sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 (HuggingFace link). However you can use other sentence transformers from HuggingFace by setting the environment HARMONY_SENTENCE_TRANSFORMER_PATH before importing Harmony:
export HARMONY_SENTENCE_TRANSFORMER_PATH=sentence-transformers/distiluse-base-multilingual-cased-v2
Any word vector representation can be used by Harmony. The below example works for OpenAI's text-embedding-ada-002 model as of July 2023, provided you have create a paid OpenAI account. However, since LLMs are progressing rapidly, we have chosen not to integrate Harmony directly into the OpenAI client libraries, but instead allow you to pass Harmony any vectorisation function of your choice.
import numpy as np
from harmony import match_instruments_with_function, example_instruments
from openai import OpenAI
client = OpenAI()
model_name = "text-embedding-ada-002"
def convert_texts_to_vector(texts):
vectors = client.embeddings.create(input = texts, model=model_name).data
return np.asarray([vectors[i].embedding for i in range(len(vectors))])
instruments = example_instruments["CES_D English"], example_instruments["GAD-7 Portuguese"]
all_questions, similarity, query_similarity, new_vectors_dict = match_instruments_with_function(instruments, None, convert_texts_to_vector)
Download and install Docker:
- https://docs.docker.com/desktop/install/mac-install/
- https://docs.docker.com/desktop/install/windows-install/
- https://docs.docker.com/desktop/install/linux-install/
Open a Terminal and run
docker run -p 8000:8000 -p 3000:3000 harmonydata/harmonylocal
Then go to http://localhost:3000 in your browser.
Visit: https://github.com/harmonydata/harmonyapi
- 📰 The code for training the PDF extraction is here: https://github.com/harmonydata/pdf-questionnaire-extraction
If you are a Docker user, you can run Harmony from a pre-built Docker image.
- https://hub.docker.com/repository/docker/harmonydata/harmonyapi - just the Harmony API
- https://hub.docker.com/repository/docker/harmonydata/harmonylocal - Harmony API and React front end
If you'd like to contribute to this project, you can contact us at https://harmonydata.ac.uk/ or make a pull request on our Github repository. You can also raise an issue.
Test code is in tests/ folder using unittest.
The testing tool tox is used in the automation with GitHub Actions CI/CD. Since the PDF extraction also needs Java and Tika installed, you cannot run the unit tests without first installing Java and Tika. See above for instructions.
Install tox and run it:
pip install tox
tox
In our configuration, tox runs a check of source distribution using check-manifest (which requires your repo to be git-initialized (git init) and added (git add .) at least), setuptools's check, and unit tests using pytest. You don't need to install check-manifest and pytest though, tox will install them in a separate environment.
The automated tests are run against several Python versions, but on your machine, you might be using only one version of Python, if that is Python 3.9, then run:
tox -e py39
Thanks to GitHub Actions' automated process, you don't need to generate distribution files locally.
This package is based on the template https://pypi.org/project/example-pypi-package/
This package
- uses GitHub Actions for both testing and publishing
- is tested when pushing
masterormainbranch, and is published when create a release - includes test files in the source distribution
- uses setup.cfg for version single-sourcing (setuptools 46.4.0+)
The code to re-release Harmony on PyPI is as follows:
source activate py311
pip install twine
rm -rf dist
python setup.py sdist
twine upload dist/*
Harmony is a collaboration project between Ulster University, University College London, the Universidade Federal de Santa Maria, and Fast Data Science. Harmony is funded by Wellcome as part of the Wellcome Data Prize in Mental Health.
The core team at Harmony is made up of:
- Dr Bettina Moltrecht, PhD (UCL)
- Dr Eoin McElroy (University of Ulster)
- Dr George Ploubidis (UCL)
- Dr Mauricio Scopel Hoffmann (Universidade Federal de Santa Maria, Brazil)
- Thomas Wood (Fast Data Science)
MIT License. Copyright (c) 2023 Ulster University (https://www.ulster.ac.uk)
You can cite our validation paper:
McElroy, Wood, Bond, Mulvenna, Shevlin, Ploubidis, Scopel Hoffmann, Moltrecht, Using natural language processing to facilitate the harmonisation of mental health questionnaires: a validation study using real-world data. BMC Psychiatry 24, 530 (2024), https://doi.org/10.1186/s12888-024-05954-2
A BibTeX entry for LaTeX users is
@article{mcelroy2024using,
title={Using natural language processing to facilitate the harmonisation of mental health questionnaires: a validation study using real-world data},
author={McElroy, Eoin and Wood, Thomas and Bond, Raymond and Mulvenna, Maurice and Shevlin, Mark and Ploubidis, George B and Hoffmann, Mauricio Scopel and Moltrecht, Bettina},
journal={BMC psychiatry},
volume={24},
number={1},
pages={530},
year={2024},
publisher={Springer}
}