前端开发体系建设日记 #2
Description
前端开发体系建设日记
上周写了一篇 文章 介绍前端集成解决方案的基本理论,很多同学看过之后大呼不过瘾。
干货
fuck things在哪里!
本打算继续完善理论链,形成前端工程的知识结构。但鉴于如今的快餐文化,po主决定还是先写一篇实战介绍,让大家看到前端工程体系能为团队带来哪些好处,调起大家的胃口再说。
ps: 写完才发现这篇文章真的非常非常长,涵盖了前端开发中的很多方面,希望大家能有耐心看完,相信一定会有所斩获。。。
2014年02月12日 - 晴
新到松鼠团队的第二天,小伙伴 @nino 找到我说
nino: 视频项目打算重新梳理一下,希望能引入新的技术体系,解决现有的一些问题。
po主不禁暗喜,好机会,这是我专业啊,蓝翔技校-前端集成解决方案学院-自动化系-打包学专业的文凭不是白给的,于是自信满满的对nino说,有什么需求尽管提!
nino: 我的需求并不多,就这么几条~~
- 模块化开发。最好能像写nodejs一样写js,很舒服。css最好也能来个模块化管理!
- 性能要好。模块那么多,得有按需加载,请求不能太多。
- 组件化开发。一个组件的js、css、模板最好都在一个目录维护,维护起来方便。
- 用 handlebars 作为前端模板引擎。这个模板引擎不错,logic-less(轻逻辑)。
- 用 stylus 写css挺方便,给我整一个。
- 图片base64嵌入。有些小图可能要以base64的形式嵌入到页面、js或者css中使用。嵌入之前记得压缩图片以减小体积。
- js/css/图片压缩应该都没问题吧。
- 要能与公司的ci平台集。工具里最好别依赖什么系统库,ci的机器未必支持。
- 开发体验要好。文件监听,浏览器自动刷新(livereload)一个都不能少。
- 我们用nodejs作为服务器,本地要能预览,最好再能抓取线上数据,方便调试。
我倒吸一口凉气,但表面故作镇定的说:恩,确实不多,让我们先来看看第一个需求。。。
还没等我说完,nino打断我说
nino: 桥豆麻袋(稍等),还有一个最重要的需求!
松鼠公司的松鼠浏览器你知道吧,恩,它有很多个版本的样子。
我希望代码发布后能按照版本部署,不要彼此覆盖。
举个例子,代码部署结构可能是这样的:
release/
- public/
- 项目名
- 1.0.0/
- 1.0.1/
- 1.0.2/
- 1.0.2-alpha/
- 1.0.2-beta/
让历史浏览器浏览历史版本,没事还能做个灰度发布,ABTest啥的,多好!
此外,我们将来会有多个项目使用这套开发模式,希望能共用一些组件或者模
块,产品也会公布一些api模块给第三方使用,所以共享模块功能也要加上。
总的来说,还要追加两个部署需求:
- 按版本部署,采用非覆盖式发布
- 允许第三方引用项目公共模块
nino: 怎么样,不算复杂吧,这个项目很赶,
3天搞定怎么样?
我凝望着会议室白板上的这些需求,正打算争辩什么,一扭头发现nino已经不见了。。。正在沮丧之际,小伙伴 @hinc 过来找我,跟他大概讲了一下nino的需求,正想跟他抱怨工期问题时,hinc却说
hinc: 恩,这正是我们需要的开发体系,不过我这里还有一个需求。。。
- 我们之前积累了一些业务可以共用的模块,放在了公司内的gitlab上,采用 component 作为发布规范,能不能再加上这个组件仓库的支持?
3天时间,13项前端技术元素,靠谱么。。。
2014年02月13日 - 多云
一觉醒来,轻松了许多,但还有任务在身,不敢有半点怠慢。整理一下昨天的需求,我们来做一个简单的划分。
- 规范
- 开发规范
- 模块化开发,js模块化,css模块化,像nodejs一样编码
- 组件化开发,js、css、handlebars维护在一起
- 部署规范
- 采用nodejs后端,基本部署规范应该参考 express 项目部署
- 按版本号做非覆盖式发布
- 公共模块可发布给第三方共享
- 开发规范
- 框架
- js模块化框架,支持请求合并,按需加载等性能优化点
- 工具
- 可以编译stylus为css
- 支持js、css、图片压缩
- 允许图片压缩后以base64编码形式嵌入到css、js或html中
- 与ci平台集成
- 文件监听、浏览器自动刷新
- 本地预览、数据模拟
- 仓库
- 支持component模块安装和使用
这样一套规范、框架、工具和仓库的开发体系,服从我之前介绍的 前端集成解决方案 的描述。前端界每天都团队在设计和实现这类系统,它们其实是有规律可循的。百度出品的 fis 就是一个能帮助快速搭建前端集成解决方案的工具。使用fis我应该可以在3天之内完成这些任务。
ps: 这不是一篇关于fis的软文,如果这样的一套系统基于grunt实现相信会有非常大量的开发工作,3天完成几乎是不可能的任务。
不幸的是,现在fis官网所介绍的 并不是 fis,而是一个叫 fis-plus 的项目,该项目并不像字面理解的那样是fis的加强版,而是在fis的基础上定制的一套面向百度前端团队的解决方案,以php为后端语言,跟smarty有较强的绑定关系,有着 19项 技术要素,密切配合百度现行技术选型。绝大多数非百度前端团队都很难完整接受这19项技术选型,尤其是其中的部署、框架规范,跟百度前端团队相关开发规范、部署规范、以及php、smarty等有着较深的绑定关系。
因此如果你的团队用的不是 php后端 && smarty模板 && modjs模块化框架 && bingo框架 的话,请查看 fis的文档,或许不会有那么多困惑。
ps: fis是一个构建系统内核,很好的抽象了前端集成解决方案所需的通用工具需求,本身不与任何后端语言绑定。而基于fis实现的具体解决方案就会有具体的规范和技术选型了。
言归正传,让我们基于 fis 开始实践这套开发体系吧!
0. 开发概念定义
前端开发体系设计第一步要定义开发概念。开发概念是指针对开发资源的分类概念。开发概念的确立,直接影响到规范的定制。比如,传统的开发概念一般是按照文件类型划分的,所以传统前端项目会有这样的目录结构:
- js:放js文件
- css:放css文件
- images:放图片文件
- html:放html文件
这样确实很直接,任何智力健全的人都知道每个文件该放在哪里。但是这样的开发概念划分将给项目带来较高的维护成本,并为项目臃肿埋下了工程隐患,理由是:
- 如果项目中的一个功能有了问题,维护的时候要在js目录下找到对应的逻辑修改,再到css目录下找到对应的样式文件修改一下,如果图片不对,还要再跑到images目录下找对应的开发资源。
- images下的文件不知道哪些图片在用,哪些已经废弃了,谁也不敢删除,文件越来越多。
ps: 除非你的团队只有1-2个人,你的项目只有很少的代码量,而且不用关心性能和未来的维护问题,否则,以文件为依据设计的开发概念是应该被抛弃的。
以我个人的经验,更倾向于具有一定语义的开发概念。综合前面的需求,我为这个开发体系确定了3个开发资源概念:
- 模块化资源:js模块、css模块或组件
- 页面资源:网站html或后端模板页面,引用模块化框架,加载模块
- 非模块化资源:并不是所有的开发资源都是模块化的,比如提供模块化框架的js本身就不能是一个模块化的js文件。严格上讲,页面也属于一种非模块化的静态资源。
ps: 开发概念越简单越好,前面提到的fis-plus也有类似的开发概念,有组件或模块(widget),页面(page),测试数据(test),非模块化静态资源(static)。有的团队在模块之中又划分出api模块和ui模块(组件)两种概念。
1. 开发目录设计
基于开发概念的确立,接下来就要确定目录规范了。我通常会给每种开发资源的目录取一个有语义的名字,三种资源我们可以按照概念直接定义目录结构为:
project
- modules 存放模块化资源
- pages 存放页面资源
- static 存放非模块化资源
这样划分目录确实直观,但结合前面hinc说过的,希望能使用component仓库资源,因此我决定将模块化资源目录命名为components,得到:
project
- components 存放模块化资源
- pages 存放页面资源
- static 存放非模块化资源
而nino又提到过模块资源分为项目模块和公共模块,以及hinc提到过希望能从component安装一些公共组件到项目中,因此,一个components目录还不够,想到nodejs用node_modules作为模块安装目录,因此我在规范中又追加了一个 component_modules 目录,得到:
project
- component_modules 存放外部模块资源
- components 存放项目模块资源
- pages 存放页面资源
- static 存放非模块化资源
nino说过今后大多数项目采用nodejs作为后端,express是比较常用的nodejs的server框架,express项目通常会把后端模板放到 views 目录下,把静态资源放到 public 下。为了迎合这样的需求,我将page、static两个目录调整为 views 和 public,规范又修改为:
project
- component_modules 存放外部模块资源
- components 存放项目模块资源
- views 存放页面资源
- public 存放非模块化资源
考虑到页面也是一种静态资源,而public这个名字不具有语义性,与其他目录都有概念冲突,不如将其与views目录合并,views目录负责存放页面和非模块化资源比较合适,因此最终得到的开发目录结构为:
project
- component_modules 存放外部模块资源
- components 存放项目模块资源
- views 存放页面以及非模块化资源
2. 部署目录设计
托nino的福,咱们的部署策略将会非常复杂,根据要求,一个完整的部署结果应该是这样的目录结构:
release
- public
- 项目名
- 1.0.0 1.0.0版本的静态资源都构建到这里
- 1.0.1 1.0.1版本的静态资源都构建到这里
- 1.0.2 1.0.2版本的静态资源都构建到这里
...
- views
- 项目名
- 1.0.0 1.0.0版本的后端模板都构建到这里
- 1.0.1 1.0.1版本的后端模板都构建到这里
- 1.0.2 1.0.2版本的后端模板都构建到这里
...
由于还要部署一些可以被第三方使用的模块,public下只有项目名的部署还不够,应改把模块化文件单独发布出来,得到这样的部署结构:
release
- public
- component_modules 模块化资源都部署到这个目录下
- module_a
- 1.0.0
- module_a.js
- module_a.css
- module_a.png
- 1.0.1
- 1.0.2
...
- 项目名
- 1.0.0 1.0.0版本的静态资源都构建到这里
- 1.0.1 1.0.1版本的静态资源都构建到这里
- 1.0.2 1.0.2版本的静态资源都构建到这里
...
- views
- 项目名
- 1.0.0 1.0.0版本的后端模板都构建到这里
- 1.0.1 1.0.1版本的后端模板都构建到这里
- 1.0.2 1.0.2版本的后端模板都构建到这里
...
由于 component_modules 这个名字太长了,如果部署到这样的路径下,url会很长,这也是一个优化点,因此最终决定部署结构为:
release
- public
- c 模块化资源都部署到这个目录下
- 公共模块
- 版本号
- 项目名
- 版本号
- 项目名
- 版本号 非模块化资源都部署到这个目录下
- views
- 项目名
- 版本号 后端模板都构建到这个目录下
插一句,并不是所有团队都会有这么复杂的部署要求,这和松鼠团队的业务需求有关,但我相信这个例子也不会是最复杂的。每个团队都会有自己的运维需求,前端资源部署经常牵连到公司技术架构,因此很多前端项目的开发目录结构会和部署要求保持一致。这也为项目间模块的复用带来了成本,因为代码中写的url通常是部署后的路径,迁移之后就可能失效了。
解耦开发规范和部署规范是前端开发体系的设计重点。
好了,去吃个午饭,下午继续。。。
3. 配置fis连接开发规范和部署规范
我准备了一个样例项目:
project
- views
- logo.png
- index.html
- fis-conf.js
- README.md
fis-conf.js是fis工具的配置文件,接下来我们就要在这里进行构建配置了。虽然开发规范和部署规范十分复杂,但好在fis有一个非常强大的 roadmap.path 功能,专门用于分类文件、调整发布结构、指定文件的各种属性等功能实现。
所谓构建,其核心任务就是将文件按照某种规则进行分类(以文件后缀分类,以模块化/非模块化分类,以前端/后端代码分类),然后针对不同的文件做不同的构建处理。
闲话少说,我们先来看一下基本的配置,在 fis-conf.js 中添加代码:
fis.config.set('roadmap.path', [
{
reg : '**.md', //所有md后缀的文件
release : false //不发布
}
]);以上配置,使得项目中的所有md后缀文件都不会发布出来。release是定义file对象发布路径的属性,如果file对象的release属性为false,那么在项目发布阶段就不会被输出出来。
在fis中,roadmap.pah是一个数组数据,数组每个元素是一个对象,必须定义 reg 属性,用以匹配项目文件路径从而进行分类划分,reg属性的取值可以是路径通配字符串或者正则表达式。fis有一个内部的文件系统,会给每个源码文件创建一个 fis.File 对象,创建File对象时,按照roadmap.path的配置逐个匹配文件路径,匹配成功则把除reg之外的其他属性赋给File对象,fis中各种处理环节及插件都会读取所需的文件对象的属性值,而不会自己定义规范。有关roadmap.path的工作原理可以看这里 以及 这里。
ok,让md文件不发布很简单,那么views目录下的按版本发布要求怎么实现呢?其实也是非常简单的配置:
fis.config.set('roadmap.path', [
{
reg : '**.md', //所有md后缀的文件
release : false //不发布
},
{
//正则匹配【/views/**】文件,并将views后面的路径捕获为分组1
reg : /^\/views\/(.*)$/i,
//发布到 public/proj/1.0.0/分组1 路径下
release : '/public/proj/1.0.0/$1'
}
]);roadmap.path数组的第二元素据采用正则作为匹配规则,正则可以帮我们捕获到分组信息,在release属性值中引用分组是非常方便的。正则匹配 + 捕获分组,成为目录规范配置的强有力工具:

在上面的配置中,版本号被写到了匹配规则里,这样非常不方便工程师在迭代的过程中升级项目版本。我们应该将版本号、项目名称等配置独立出来管理。好在roadmap.path还有读取其他配置的能力,修改上面的配置,我们得到:
//开发部署规范配置
fis.config.set('roadmap.path', [
{
reg : '**.md', //所有md后缀的文件
release : false //不发布
},
{
reg : /^\/views\/(.*)$/i,
//使用${xxx}引用fis.config的其他配置项
release : '/public/${name}/${version}/$1'
}
]);
//项目配置,将name、version独立配置,统管全局
fis.config.set('name', 'proj');
fis.config.set('version', '1.0.0');fis的配置系统非常灵活,除了 文档 中提到的配置节点,其他配置用户可以随便定义使用。比如配置的roadmap是系统保留的,而name、version都是用户自己随便指定的。fis系统保留的配置节点只有6个,包括:
完成第一份配置之后,我们来看一下效果。
cd project
fis release --dest ../release进入到项目目录,然后使用fis release命令,对项目进行构建,用 --dest <path> 参数指定编译结果的产出路径,可以看到部署后的结果:

ps: fis release会将处理后的结果发布到源码目录之外的其他目录里,以保持源码目录的干净。
fis系统的强大之处在于当你调整了部署规范之后,fis会识别所有资源定位标记,将他们修改为对应的部署路径。
fis的文件系统设计决定了配置开发规范的成本非常低。fis构建核心有三个超级正则,用于识别资源定位标记,把用户的开发规范和部署规范通过配置完整连接起来,具体实现可以看这里。
不止html,fis为前端三种领域语言都准备了资源定位识别标记,更多文档可以看这里:在html中定位资源,在js中定位资源,在css中定位资源
接下来,我们修改一下项目版本配置,再发布一下看看效果:
fis.config.set('version', '1.0.1');再次执行:
cd project
fis release --dest ../release得到:

至此,我们已经基本解决了开发和部署直接的目录规范问题,这里我需要加快一些步伐,把其他目录的部署规范也配置好,得到一个相对比较完整的结果:
fis.config.set('roadmap.path', [
{
//md后缀的文件不发布
reg : '**.md',
release : false
},
{
//component_modules目录下的代码,由于component规范,已经有了版本号
//我将它们直接发送到public/c目录下就好了
reg : /^\/component_modules\/(.*)$/i,
release : '/public/c/$1'
},
{
//项目模块化目录没有版本号结构,用全局版本号控制发布结构
reg : /^\/components\/(.*)$/i,
release : '/public/c/${name}/${version}/$1'
},
{
//views目录下的文件发布到【public/项目名/版本】目录下
reg : /^\/views\/(.*)$/,
release : '/public/${name}/${version}/$1'
},
{
//其他文件就不属于前端项目了,比如nodejs的后端代码
//不处理这些文件的资源定位替换(useStandard: false)
//也不用对这些资源进行压缩(useOptimizer: false)
reg : '**',
useStandard : false,
useOptimizer : false
}
]);
fis.config.set('name', 'proj');
fis.config.set('version', '1.0.2');我构造了一个相对完整的目录结构,然后进行了一次构建,效果还不错:

不管部署规则多么复杂都不用担心,有fis强大的资源定位系统帮你在开发规范和部署规范之间建立联系,设计开发体系不在受制于工具的实现能力。
你可以尽情发挥想象力,设计出最优雅最合理的开发规范和最高效最贴合公司运维要求的部署规范,最终用fis的roadmap.path功能将它们连接起来,实现完美转换。
fis的roadmap功能实际上提供了项目代码与部署规范解耦的能力。
从前面的例子可以看出,开发使用相对路径即可,fis会在构建时会根据fis-conf.js中的配置完成开发路径到部署路径的转换工作。这意味着在fis体系下开发的模块将具有天然的可移植性,既能满足不同项目的不同部署需求,又能允许开发中使用相对路径进行资源定位,工程师再不用把部署路径写到代码中了。
愉快的一天就这么过去了,睡觉!
2014年02月14日 - 阴转多云
每到周五总是非常惬意的感觉,不管这一周多么辛苦,周五就是一个解脱,更何况今天还是个特别的日子——情人节!
昨天主要解决了开发概念、开发目录规范、部署目录规范以及初步的fis-conf.js配置。今天要进行前端开发体系设计的关键任务——模块化框架。
模块化框架是前端开发体系中最为核心的环节。
模块化框架肩负着模块管理、资源加载、性能优化(按需,请求合并)等多种重要职责,同时它也是组件开发的基础框架,因此模块化框架设计的好坏直接影响到开发体系的设计质量。
很遗憾的说,现在市面上已有的模块化框架都没能很好的处理模块管理、资源加载和性能优化三者之间的关系。这倒不是框架设计的问题,而是由前端领域语言特殊性决定的。框架设计者一般在思考模块化框架时,通常站在纯前端运行环境角度考虑,基本功能都是用原生js实现的,因此一个模块化开发的关键问题不能被很好的解决。这个关键问题就是依赖声明。
以 seajs 为例(无意冒犯),seajs采用运行时分析的方式实现依赖声明识别,并根据依赖关系做进一步的模块加载。比如如下代码:
define(function(require) {
var foo = require("foo");
//...
});当seajs要执行一个模块的factory函数之前,会先分析函数体中的require书写,具体代码在这里和这里,大概的代码逻辑如下:
Module.define = function (id, deps, factory) {
...
//抽取函数体的字符串内容
var code = factory.toString();
//设计一个正则,分析require语句
var reg = /\brequire\s*\(([.*]?)\)/g;
var deps = [];
//扫描字符串,得到require所声明的依赖
code.replace(reg, function(m, $1){
deps.push($1);
});
//加载依赖,完成后再执行factory
...
};由于框架设计是在“纯前端实现”的约束条件下,使得模块化框架对于依赖的分析必须在模块资源加载完成之后才能做出识别。这将引起两个性能相关的问题:
- require被强制为关键字而不能被压缩。否则factory.toString()的分析将没有意义。
- 依赖加载只能串行进行,当一个模块加载完成之后才知道后面的依赖关系。
第一个问题还好,尤其是在gzip下差不多多少字节,但是要配置js压缩器保留require函数不压缩。第二个问题就比较麻烦了,虽然seajs有seajs-combo插件可以一定程度上减少请求,但仍然不能很好的解决这个问题。举个例子,有如下seajs模块依赖关系树:
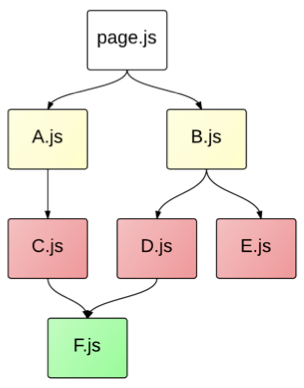
ps: 图片来源 @raphealguo
采用seajs-combo插件之后,静态资源请求的效果是这样的:
- http://www.example.com/page.js
- http://www.example.com/a.js,b.js
- http://www.example.com/c.js,d.js,e.js
- http://www.example.com/f.js
工作过程是
- 框架先请求了入口文件page.js
- 加载完成后分析factory函数,发现依赖了a.js和b.js,然后发起一个combo请求,加载a.js和b.js
- a.js和b.js加载完成后又进一步分析源码,才发现还依赖了c.js、d.js和e.js,再发起请求加载这三个文件
- 完成c、d、e的加载之后,再分析,发现f.js依赖,再请求
- 完成f.js的请求,page.js的依赖全部满足,执行它的factory函数。
虽然combo可以在依赖层级上进行合并,但完成page.js的请求仍需要4个。很多团队在使用seajs的时候,为了避免这样的串行依赖请求问题,会自己实现打包方案,将所有文件直接打包在一起,放弃了模块化的按需加载能力,也是一种无奈之举。
原因很简单
以纯前端方式来实现模块依赖加载不能同时解决性能优化问题。
归根结底,这样的结论是由前端领域语言的特点决定的。前端语言缺少三种编译能力,前面讲目录规范和部署规范时其实已经提到了一种能力,就是“资源定位的能力”,让工程师使用开发路径定位资源,编译后可转换为部署路径。其他语言编写的程序几乎都没有web这种物理上分离的资源部署策略,而且大多具都有类似'getResource(path)'这样的函数,用于在运行环境下定位当初的开发资源,这样不管项目怎么部署,只要getResource函数运行正常就行了。可惜前端语言没有这样的资源定位接口,只有url这样的资源定位符,它指向的其实并不是开发路径,而是部署路径。
这里可以简单列举出前端语言缺少三种的语言能力:
- 资源定位的能力:使用开发路径进行资源定位,项目发布后转换成部署路径
- 依赖声明的能力:声明一个资源依赖另一个资源的能力
- 资源嵌入的能力:把一个资源的编译内容嵌入到另一个文件中
以后我会在完善前端开发体系理论的时候在详细介绍这三种语言能力的必要性和原子性,这里就暂时不展开说明了。
fis最核心的编译思想就是围绕这三种语言能力设计的。
要兼顾性能的同时解决模块化依赖管理和加载问题,其关键点在于
不能运行时去分析模块间的依赖关系,而要让框架提前知道依赖树。
了解了原因,我们就要自己动手设计模块化框架了。不要害怕,模块化框架其实很简单,思想、规范都是经过很多前辈总结的结果,我们只要遵从他们的设计思想去实现就好了。
参照已有规范,我定义了三个模块化框架接口:
- 模块定义接口:
define(id, factory); - 异步加载接口:
require.async(ids, callback); - 框架配置接口:
require.config(options);
利用构建工具建立模块依赖关系表,再将关系表注入到代码中,调用require.config接口让框架知道完整的依赖树,从而实现require.async在异步加载模块时能提前预知所有依赖的资源,一次性请求回来。
以上面的page.js依赖树为例,构建工具会生成如下代码:
require.config({
deps : {
'page.js' : [ 'a.js', 'b.js' ],
'a.js' : [ 'c.js' ],
'b.js' : [ 'd.js', 'e.js' ],
'c.js' : [ 'f.js' ],
'd.js' : [ 'f.js' ]
}
});当执行require.async('page.js', fn);语句时,框架查询config.deps表,就能知道要发起一个这样的combo请求:
http://www.example.com/f.js,c.js,d.js,e.js,a.js,b.js,page.js
从而实现按需加载和请求合并两项性能优化需求。
根据这样的设计思路,我请 @hinc 帮忙实现了这个框架,我告诉他,deps里不但会有js,还会有css,所以也要兼容一下。hinc果然是执行能力非常强的小伙伴,仅一个下午的时间就搞定了框架的实现,我们给这个框架取名为 scrat.js,仅有393行。
前面提到fis具有资源依赖声明的编译能力。因此只要工程师按照fis规定的书写方式在代码中声明依赖关系,就能在构建的最后阶段自动获得fis系统整理好的依赖树,然后对依赖的数据结构进行调整、输出,满足框架要求就搞定了!fis规定的资源依赖声明方式为:在html中声明依赖,在js中声明依赖,在css中声明依赖。
接下来,我要写一个配置,将依赖关系表注入到代码中。fis构建是分流程的,具体构建流程可以看这里。fis会在postpackager阶段之前创建好完整的依赖树表,我就在这个时候写一个插件来处理即可。
编辑fis-conf.js
//postpackager插件接受4个参数,
//ret包含了所有项目资源以及资源表、依赖树,其中包括:
// ret.src: 所有项目文件对象
// ret.pkg: 所有项目打包生成的额外文件
// reg.map: 资源表结构化数据
//其他参数暂时不用管
var createFrameworkConfig = function(ret, conf, settings, opt){
//创建一个对象,存放处理后的配置项
var map = {};
//依赖树数据
map.deps = {};
//遍历所有项目文件
fis.util.map(ret.src, function(subpath, file){
//文件的依赖数据就在file对象的requires属性中,直接赋值即可
if(file.requires && file.requires.length){
map.deps[file.id] = file.requires;
}
});
console.log(map.deps);
};
//在modules.postpackager阶段处理依赖树,调用插件函数
fis.config.set('modules.postpackager', [createFrameworkConfig]);我们准备一下项目代码,看看构建的时候发生了什么:
执行fis release查看命令行输出,可以看到consolog.log的内容为:
{
deps: {
'components/bar/bar.js': [
'components/bar/bar.css'
],
'components/foo/foo.js': [
'components/bar/bar.js',
'components/foo/foo.css'
]
}
}可以看到js和同名的css自动建立了依赖关系,这是fis默认进行的依赖声明。有了这个表,我们就可以把它注入到代码中了。我们为页面准备一个替换用的钩子,比如约定为__FRAMEWORK_CONFIG__,这样用户就可以根据需要在合适的地方获取并使用这些数据。模块化框架的配置一般都是写在非模块化文件中的,比如html页面里,所以我们应该只针对views目录下的文件做这样的替换就可以。所以我们需要给views下的文件进行一个标记,只有views下的html或js文件才需要进行依赖树数据注入,具体的配置为:
fis.config.set('roadmap.path', [
{
reg : '**.md',
release : false
},
{
reg : /^\/component_modules\/(.*)$/i,
release : '/public/c/$1'
},
{
reg : /^\/components\/(.*)$/i,
release : '/public/c/${name}/${version}/$1'
},
{
reg : /^\/views\/(.*)$/,
//给views目录下的文件加一个isViews属性标记,用以标记文件分类
//我们可以在插件中拿到文件对象的这个值
isViews : true,
release : '/public/${name}/${version}/$1'
},
{
reg : '**',
useStandard : false,
useOptimizer : false
}
]);
var createFrameworkConfig = function(ret, conf, settings, opt){
var map = {};
map.deps = {};
fis.util.map(ret.src, function(subpath, file){
if(file.requires && file.requires.length){
map.deps[file.id] = file.requires;
}
});
//把配置文件序列化
var stringify = JSON.stringify(map, null, opt.optimize ? null : 4);
//再次遍历文件,找到isViews标记的文件
//替换里面的__FRAMEWORK_CONFIG__钩子
fis.util.map(ret.src, function(subpath, file){
//有isViews标记,并且是js或者html类文件,才需要做替换
if(file.isViews && (file.isJsLike || file.isHtmlLike)){
var content = file.getContent();
//替换文件内容
content = content.replace(/\b__FRAMEWORK_CONFIG__\b/g, stringify);
file.setContent(content);
}
});
};
fis.config.set('modules.postpackager', [createFrameworkConfig]);
//项目配置
fis.config.set('name', 'proj'); //将name、version独立配置,统管全局
fis.config.set('version', '1.0.3');我在views/index.html中写了这样的代码:
<!doctype html>
<html>
<head>
<title>hello</title>
</head>
<body>
<script type="text/javascript" src="scrat.js"></script>
<script type="text/javascript">
require.config(__FRAMEWORK_CONFIG__);
require.async('components/foo/foo.js', function(foo){
//todo
});
</script>
</body>
</html>执行 fis release -d ../release 之后,得到构建后的内容为:
<!doctype html>
<html>
<head>
<title>hello</title>
</head>
<body>
<script type="text/javascript" src="/public/proj/1.0.3/scrat.js"></script>
<script type="text/javascript">
require.config({
"deps": {
"components/bar/bar.js": [
"components/bar/bar.css"
],
"components/foo/foo.js": [
"components/bar/bar.js",
"components/foo/foo.css"
]
}
});
require.async('components/foo/foo.js', function(foo){
//todo
});
</script>
</body>
</html>在调用 require.async('components/foo/foo.js') 之际,模块化框架已经知道了这个foo.js依赖于bar.js、bar.css以及foo.css,因此可以发起两个combo请求去加载所有依赖的js、css文件,完成后再执行回调。
现在模块的id有一些问题,因为模块发布会有版本号信息,因此模块id也应该携带版本信息,从前面的依赖树生成配置代码中我们可以看到模块id其实也是文件的一个属性,因此我们可以在roadmap.path中重新为文件赋予id属性,使其携带版本信息:
fis.config.set('roadmap.path', [
{
reg : '**.md',
release : false,
isHtmlLike : true
},
{
reg : /^\/component_modules\/(.*)$/i,
//追加id属性
id : '$1',
release : '/public/c/$1'
},
{
reg : /^\/components\/(.*)$/i,
//追加id属性,id为【项目名/版本号/文件路径】
id : '${name}/${version}/$1',
release : '/public/c/${name}/${version}/$1'
},
{
reg : /^\/views\/(.*)$/,
//给views目录下的文件加一个isViews属性标记,用以标记文件分类
//我们可以在插件中拿到文件对象的这个值
isViews : true,
release : '/public/${name}/${version}/$1'
},
{
reg : '**',
useStandard : false,
useOptimizer : false
}
]);重新构建项目,我们得到了新的结果:
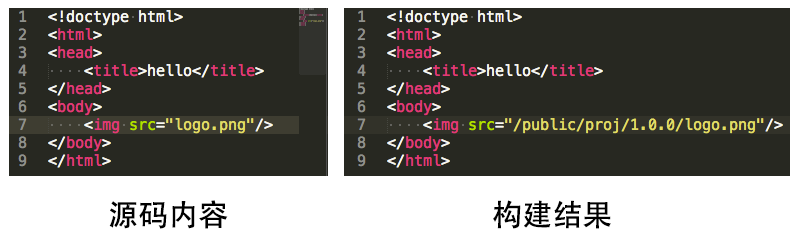
<!doctype html>
<html>
<head>
<title>hello</title>
</head>
<body>
<img src="/public/proj/1.0.4/logo.png"/>
<script type="text/javascript" src="/public/proj/1.0.4/scrat.js"></script>
<script type="text/javascript">
require.config({
"deps": {
"proj/1.0.4/bar/bar.js": [
"proj/1.0.4/bar/bar.css"
],
"proj/1.0.4/foo/foo.js": [
"proj/1.0.4/bar/bar.js",
"proj/1.0.4/foo/foo.css"
]
}
});
require.async('proj/1.0.4/foo/foo.js', function(foo){
//todo
});
</script>
</body>
</html>you see?所有id都会被修改为我们指定的模式,这就是以文件为中心的编译系统的威力。
以文件对象为中心构建系统应该通过配置指定文件的各种属性。插件并不自己实现某种规范规定,而是读取file对象的对应属性值,这样插件的职责单一,规范又能统一起来被用户指定,为完整的前端开发体系设计奠定了坚实规范配置的基础。
接下来还有一个问题,就是模块名太长,开发中写这么长的模块名非常麻烦。我们可以借鉴流行的模块化框架中常用的缩短模块名手段——别名(alias)——来降低开发中模块引用的成本。此外,目前的配置其实会针对所有文件生成依赖关系表,我们的开发概念定义只有components和component_modules目录下的文件才是模块化的,因此我们可以进一步的对文件进行分类,得到这样配置规范:
fis.config.set('roadmap.path', [
{
reg : '**.md',
release : false,
isHtmlLike : true
},
{
reg : /^\/component_modules\/(.*)$/i,
id : '$1',
//追加isComponentModules标记属性
isComponentModules : true,
release : '/public/c/$1'
},
{
reg : /^\/components\/(.*)$/i,
id : '${name}/${version}/$1',
//追加isComponents标记属性
isComponents : true,
release : '/public/c/${name}/${version}/$1'
},
{
reg : /^\/views\/(.*)$/,
isViews : true,
release : '/public/${name}/${version}/$1'
},
{
reg : '**',
useStandard : false,
useOptimizer : false
}
]);然后我们为一些模块id建立别名:
var createFrameworkConfig = function(ret, conf, settings, opt){
var map = {};
map.deps = {};
//别名收集表
map.alias = {};
fis.util.map(ret.src, function(subpath, file){
//添加判断,只有components和component_modules目录下的文件才需要建立依赖树或别名
if(file.isComponents || file.isComponentModules){
//判断一下文件名和文件夹是否同名,如果同名则建立一个别名
var match = subpath.match(/^\/components\/(.*?([^\/]+))\/\2\.js$/i);
if(match && match[1] && !map.alias.hasOwnProperty(match[1])){
map.alias[match[1]] = file.id;
}
if(file.requires && file.requires.length){
map.deps[file.id] = file.requires;
}
}
});
var stringify = JSON.stringify(map, null, opt.optimize ? null : 4);
fis.util.map(ret.src, function(subpath, file){
if(file.isViews && (file.isJsLike || file.isHtmlLike)){
var content = file.getContent();
content = content.replace(/\b__FRAMEWORK_CONFIG__\b/g, stringify);
file.setContent(content);
}
});
};
fis.config.set('modules.postpackager', [createFrameworkConfig]);再次构建,在注入的代码中就能看到alias字段了:
require.config({
"deps": {
"proj/1.0.5/bar/bar.js": [
"proj/1.0.5/bar/bar.css"
],
"proj/1.0.5/foo/foo.js": [
"proj/1.0.5/bar/bar.js",
"proj/1.0.5/foo/foo.css"
]
},
"alias": {
"bar": "proj/1.0.5/bar/bar.js",
"foo": "proj/1.0.5/foo/foo.js"
}
});这样,代码中的 require('foo'); 就等价于 require('proj/1.0.5/foo/foo.js');了。
还剩最后一个小小的需求,就是希望能像写nodejs一样开发js模块,也就是要求实现define的自动包裹功能,这个可以通过文件编译的 postprocessor 插件完成。配置为:
//在postprocessor对所有js后缀的文件进行内容处理:
fis.config.set('modules.postprocessor.js', function(content, file){
//只对模块化js文件进行包装
if(file.isComponents || file.isComponentModules){
content = 'define("' + file.id +
'", function(require,exports,module){' +
content + '});';
}
return content;
});所有在components目录和component_modules目录下的js文件都会被包裹define,并自动根据roadmap.path中的id配置进行模块定义了。
最煎熬的一天终于过去了,睡一觉,拥抱一下周末。
2014年02月15日 - 超晴
周末的天气非常好哇,一觉睡到中午才起,这么好的天气写码岂不是很loser?!
2014年02月16日 - 小雨
居然浪费了一天,剩下的时间不多了,今天要抓紧啊!!!
让我们来回顾一下已经完成了哪些工作:
- 规范
- 开发规范
模块化开发,js模块化,css模块化,像nodejs一样的模块化开发组件化开发,js、css、handlebars维护在一起
- 部署规范
采用nodejs后端,基本部署规范应该参考 express 项目部署按版本号做非覆盖式发布公共模块可发布给第三方共享
- 开发规范
- 框架
js模块化框架,支持请求合并,按需加载等性能优化点
- 工具
- 可以编译stylus为css
- 支持js、css、图片压缩
- 允许图片压缩后以base64编码形式嵌入到css、js或html中
- 与ci平台集成
- 文件监听、浏览器自动刷新
- 本地预览、数据模拟
- 仓库
- 支持component模块安装和使用
剩下的几个需求中有些是fis默认支持的,比如base64内嵌功能,图片会先经过编译流程,得到压缩后的内容fis再对其进行base64化的内嵌处理。由于fis的内嵌功能支持任意文件的内嵌,所以,这个语言能力扩展可以同时解决前端模板和图片base64内嵌需求,比如我们有这样的代码:
project
- components
- foo
- foo.js
- foo.css
- foo.handlebars
- foo.png
无需配置,既可以在js中嵌入资源,比如 foo.js 中可以这样写:
//依赖声明
var bar = require('../bar/bar.js');
//把handlebars文件的字符串形式嵌入到js中
var text = __inline('foo.handlebars');
var tpl = Handlebars.compile(text);
exports.render = function(data){
return tpl(data);
};
//把图片的base64嵌入到js中
var data = __inline('foo.png');
exports.getImage = function(){
var img = new Image();
img.src = data;
return img;
};编译后得到:
define("proj/1.0.5/foo/foo.js", function(require,exports,module){
//依赖声明
var bar = require('proj/1.0.5/bar/bar.js');
//把handlebars文件的字符串形式嵌入到js中
var text = "<h1>{{title}}</h1>";
var tpl = Handlebars.compile(text);
exports.render = function(data){
return tpl(data);
};
//把图片的base64嵌入到js中
var data = 'data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAACoA...';
exports.getImage = function(){
var img = new Image();
img.src = data;
return img;
};
});支持stylus也非常简单,fis在 parser 阶段处理非标准语言,这个阶段可以把非标准的js(coffee/前端模板)、css(less/sass/stylus)、html(markdown)语言转换为标准的js、css或html。处理之后那些文件还能和标准语言一起经历预处理、语言能力扩展、后处理、校验、测试、压缩等阶段。
所以,要支持stylus的编译,只要在fis-conf.js中添加这样的配置即可:
//依赖开源的stylus包
var stylus = require('stylus');
//编译插件只负责处理文件内容
var stylusParser = function(content, file, conf){
return stylus(content, conf).render();
};
//配置编译流程,styl后缀的文件经过编译插件函数处理
fis.config.set('modules.parser.styl', stylusParser);
//告诉fis,styl后缀的文件,被当做css处理,编译后后缀也是css
fis.config.set('roadmap.ext.styl', 'css');这样我们项目中的*.styl后缀的文件都会被编译为css内容,并且会在后面的流程中被当做css内容处理,比如压缩、csssprite等。
文件监听、自动刷新都是fis内置的功能,fis的release命令集合了所有编译所需的参数,
fis release -h
Usage: release [options]
Options:
-h, --help output usage information
-d, --dest <names> release output destination
-m, --md5 [level] md5 release option
-D, --domains add domain name
-l, --lint with lint
-t, --test with unit testing
-o, --optimize with optimizing
-p, --pack with package
-w, --watch monitor the changes of project
-L, --live automatically reload your browser
-c, --clean clean compile cache
-r, --root <path> set project root
-f, --file <filename> set fis-conf file
-u, --unique use unique compile caching
--verbose enable verbose output这些参数是可以随意组合的,比如我们想文件监听、自动刷新,则使用:
fis release -wL
压缩、打包、文件监听、自动刷新、发布到output目录,则使用:
fis release -opwLd output
构建工具不需要那么多命令,或者develop、release等不同状态的配置文件,应该从命令行切换编译参数,从而实现开发/上线构建模式的切换。
另外,fis是命令行工具,各种内置的插件也是完全独立无环境依赖的,可以与ci平台直接对接,并在各个主流操作系统下运行正常。
利用fis的内置的各种编译功能,我们离目标又近了许多:
- 规范
- 开发规范
模块化开发,js模块化,css模块化,像nodejs一样的模块化开发组件化开发,js、css、handlebars维护在一起
- 部署规范
采用nodejs后端,基本部署规范应该参考express项目部署按版本号做非覆盖式发布公共模块可发布给第三方共享
- 开发规范
- 框架
js模块化框架,支持请求合并,按需加载等性能优化点
- 工具
可以编译stylus为css支持js、css、图片压缩允许图片压缩后以base64编码形式嵌入到css、js或html中与ci平台集成文件监听、浏览器自动刷新- 本地预览、数据模拟
- 仓库
- 支持component模块安装和使用
剩下两个,我们可以通过扩展fis的命令行插件来实现。fis有11个编译流程扩展点,还有一个命令行扩展点。要扩展命令行插件很简单,只要我们将插件安装到与fis同级的node_modules目录下即可。比如:
node_modules
- fis
- fis-command-say
那么执行 fis say 这个命令,就能调用到那个fis-command-say插件了。剩下的这个component模块安装,我就利用了这个扩展点,结合component开源的 component-installer 包,我就可以把component整合当前开发体系中,这里我们需要创建一个npm包来提供扩展,而不能直接在fis-conf.js中扩展命令行,插件代码我就不贴了,可以看 这里。
眼前我们有了一个差不多100行的fis-conf.js文件,还有几个插件,如果我把这样一个零散的系统交付团队使用,那么大家使用的步骤差不多是这样的:
- 安装fis,
npm install -g fis - 安装component安装用的命令行插件,
npm insatll -g fis-command-component - 安装stylus编译插件,
npm install -g fis-parser-stylus - 下载一份配置文件,fis-conf.js,修改里面的name、version配置
这种情况让团队用起来会有很多问题。首先,安装过程太过麻烦,其次如果项目多,那么fis-conf.js不能同步升级,这是非常严重的问题。grunt的gruntfile.js也是如此。如果说有一个项目用了某套grunt配置感觉很爽,那么下个项目也想用这套方案,复制gruntfile.js是必须的操作,项目用的多了,同步gruntfile的成本就变得非常高了。
因此,fis提供了一种“包装”的能力,它允许你将fis作为内核,包装出一个新的命令行工具,这个工具内置了一些fis的配置,并且把所有命令行调用的参数传递给fis内核去处理。
我准备把这套系统打包为一个新的工具,给它取名为 scrat,也是一只松鼠。这个新工具的目录结构是这样的:
scrat
- bin
- scrat
- node_modules
- fis
- fis-parser-handlebars
- fis-lint-jshint
- scrat-command-install
- scrat-command-server
- scrat-parser-stylus
- index.js
- package.json
其中,index.js的内容为:
//require一下fis模块
var fis = module.exports = require('fis');
//声明命令行工具名称
fis.cli.name = 'scrat';
//定义插件前缀,允许加载scrat-xxx-xxx插件,或者fis-xxx-xxx插件,
//这样可以形成scrat自己的插件系统
fis.require.prefixes = [ 'scrat', 'fis' ];
//把前面的配置都写在这里统一管理
//项目中就不用再写了
fis.config.merge({...});将这个npm包发布出来,我们就有了一个全新的开发工具,这个工具可以解决前面说的13项技术问题,并提供一套完整的集成解决方案,而你的团队使用的时候,只有两个步骤:
- 安装这个工具,npm install -g scrat
- 项目配置只有两项,name和version
使用新工具的命令、参数几乎和fis完全一样:
scrat release [options]
scrat server start
scrat install <name@version> [options]
而scrat这个工具所内置的配置将变成规范文档描述给团队同学,这套系统要比grunt那种松散的构建系统组成方式更容易被多个团队、多个项目同时共享。
熬了一个通宵,基本算是完成了。。。
2014年02月17日 - 多云
终于到了周一,交付了一个新的开发工具——scrat,及其使用 文档。
然而,过去的三天,为了构造这套前端开发体系,都写了哪些代码呢?
- 基于fis的一套规范及插件配置,274行;
- scrat install命令行插件,用于安装component模块,74行;
- scrat server命令行插件,用于启动nodejs的服务器,203行
- 编译stylus的插件,10行
- 编译handlebars的插件,6行
- 一个模块化框架 scrat.js,393行
一共 960行 代码,用了4人/天。
总结
不可否认,为大规模前端团队设计集成解决方案需要花费非常多的心思。
如果说只是实现一个简单的编译+压缩+文件监+听自动刷新的常规构建系统,基于fis应该不超过1小时就能完成一个,但要实践完整的前端集成解决方案,确实需要点时间。
如之前一篇 文章 所讲,前端集成解决方案有8项技术要素,除了组件仓库,其他7项对于企业级前端团队来说,应该都需要完整实现的。即便暂时不想实现,也会随着业务发展而被迫慢慢完善,这个完善过程是普适的。
对于前端集成解决方案的实践,可以总结出这些设计步骤:
- 设计开发概念,定义开发资源的分类(模块化/非模块化)
- 设计开发目录,降低开发、维护成本(开发规范)
- 根据运维和业务要求,设计部署规范(部署规范)
- 设计工具,完成开发目录和部署目录的转换(开发-部署转换)
- 设计模块化框架,兼顾性能优化(开发框架)
- 扩展工具,支持开发框架的构建需求(框架构建需求)
- 流程整合(开发、测试、联调、上线等流程接入)
我们可以看看业界已有团队提出的各种解决方案,无不以这种思路来设计和发展的:
- seajs开发体系,支付宝团队前端开发体系,以 spm 为构建和包管理工具
- fis-plus,百度绝大多数前端团队使用的开发体系,以fis为构建工具内核,以lights为包管理工具
- edp,百度ecomfe前端开发体系,以 edp 为构建和包管理工具
- modjs,腾讯AlloyTeam团队出品的开发体系
- yeoman,google出品的解决方案,以grunt为构建工具,bower为包管理工具
纵观这些公司出品的前端集成解决方案,深入剖析其中的框架、规范、工具和流程,都可以发现一些共通的影子,设计思想殊途同归,不约而同的朝着一种方向前进,那就是前端集成解决方案。尝试将前端工程孤立的技术要素整合起来,解决常见的领域问题。
或许有人会问,不就是写页面么,用得着这么复杂?
在这里我不能给出肯定或者否定的答复。
因为单纯从语言的角度来说,html、js、css(甚至有人认为css是数据结构,而非语言)确实是最简单最容易上手的开发语言,不用模块化、不用工具、不用压缩,任何人都可以快速上手,完成一两个功能简单的页面。所以说,在一般情况下,前端开发非常简单。
在规模很小的项目中,前端技术要素彼此不会直接产生影响,因此无需集成解决方案。
但正是由于前端语言这种灵活松散的特点,使得前端项目规模在达到一定规模后,工程问题凸显,成为发展瓶颈,各种技术要素彼此之间开始出现关联,要用模块化开发,就必须对应某个模块化框架,用这个框架就必须对应某个构建工具,要用这个工具,就必须对应某个包管理工具……这个时候,完整实践前端集成解决方案就成了不二选择。
当前端项目达到一定规模后,工程问题将成为主要瓶颈,原来孤立的技术要素开始彼此产生影响,需要有人从比较高的角度去梳理、寻找适合自己团队的集成解决方案。
所以会出现一些框架或工具在小项目中使用的好好的,一旦放到团队里使用就非常困难的情况。
前端入门虽易工程不易,且行写珍惜!