- Build and Test Status
- About EnviRe Core
- Installation
- Rock CMake Macros
- Rock Standard Layout
- Developement and Contribution
- Documentation
- Code Examples
- Frames
- Plugins
- Items
- Creating Items
- Adding Item
- Accessing Items
- Checking Whether a Frame Contains Items of a Specific Type
- Accessing Items with Iterators
- Accessing Items without Iterators
- Removing Items
- Adding Transformations
- Removing Transformations
- Modifying Transformations
- Calculating Transformations
- Disconnecting a Frame from the Graph
- TreeViews
- Maintenance and development

This is the core library for Environment Representation. The goal of this core part is to deal with the representation commonalities among plugins.
Environment Representation (EnviRe) technologies are meant to close the gap and provide techniques to store, operate and interchange information within a robotic system. The application of EnviRe mainly focus to support navigation, simulation and operations and simplify the interchange of algorithms among software components.
The easiest way to build and install this package is to use Rock’s build system. See this page on how to install Rock.
The envire package set(https://github.com/envire/envire-package_set) is required to fulfil the
dependencies to base/boost_serialisation and external/ogdf. All other dependencies should be available in the default rock package sets.
First make sure that all dependencies are installed. Most of the dependencies can be installed using apt:
apt install build-essential gcc g++ cmake git wget libgoogle-glog-dev libboost-test-dev libboost-filesystem-dev libboost-serialization-dev libboost-system-dev pkg-config libeigen3-dev libclass-loader-dev libtinyxml-dev librosconsole-bridge-dev libeigen3-dev libclass-loader-dev libtinyxml-dev doxygen
Some dependencies need to be build from source. A script is provided to install those:
Defining -DINSTALL_DEPS=ON for cmake builds and isntalls the source dependencies automatically.
mkdir build
cd build
cmake -DINSTALL_DEPS=ON ..
make installWhen -DCMAKE_INSTALL_PREFIX is used, the dependencies are also installed there.
The install script generates an env.sh file in the CMAKE_INSTALL_PREFIX folder. If you did not install system wide, source this file before building and running code. It exports all neccessary environment variables.
Run make doc to generate the API documentation.
Set the COVERAGE flag during configuration to generate a code coverage make target.
Run make test && make coverage to generate the coverage report. You can find the
generated report in build/cov. Please note that coverage reporting only works
when code optimization is disabled. I.e. when CMAKE_BUILD_TYPE=Debug.
The option ROCK_TEST_ENABLED can be used to enabled/disabled the tests. It is on by default.
This package uses a set of CMake helper shipped as the Rock CMake macros. Documentations is available on this page.
This directory structure follows some simple rules, to allow for generic build processes and simplify reuse of this project. Following these rules ensures that the Rock CMake macros automatically handle the project’s build process and install setup properly.
STRUCTURE — src/ Contains all header (.h/.hpp) and source files — build/ The target directory for the build process, temporary content — bindings/ Language bindings for this package, e.g. put into subfolders such as |-- ruby/ Ruby language bindings — viz/ Source files for a vizkit plugin / widget related to this library — resources/ General resources such as images that are needed by the program — configuration/ Configuration files for running the program — external/ When including software that needs a non standard installation process, or one that can be easily embedded include the external software directly here — doc/ should contain the existing doxygen file: doxygen.conf
Contributions are very welcome. Please use the pull-request mechanism of github. The maintainers will give feedback and merge when they are satisfied. Please make sure that your contribution is covered by unit tests.
Envire Core is the main component of the envire library. It consists of:
-
A graph structure to represent the environment and utilities that help in manipulating and analyzing the structure.
-
An event system to notify users about changes in the environment.
-
A plugin system that allows the user to store arbitrary Objects in the envire graph.
-
Serialization.
The envire graph is the backbone of the whole library. It stores arbitrary data and time & space transformations between the data.
The graph itself is implemented as inheritance chain. Each class in the chain adds some of the functionality.
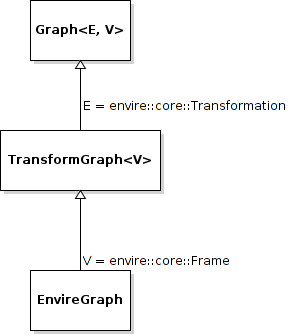
envire::core::Graph<E,V> is the root class of the graph structure. It extends
a boost::labeled_graph. The template parameters E and V are edge and
vertex properties, i.e. they define the type of the data that can be stored
in the edges and vertices of the graph. Edge properties need to implement the
envire::core::EdgePropertyConcept while vertex properties need to implement
envire::core::FramePropertyConcept.
The following features are provided by the Graph:
-
Frames (vertices) are indexed by a unique string-based frame id and can be retrieved in O(1).
-
A double-linked graph structure is enforced. I.e. if an edge is added, the inverse edge is calculated and added automatically. If an edge is updated, the inverse is updated as well.
-
Users are informed about changes in the graph structure via a publisher subscriber based event system.
-
TreeViews and Paths are provided to navigate the graph structure.
The TransformGraph<V> extends Graph<Transformation, V>. It adds functionality
to calculate and set transformations (including covariance) between frames.
Transformation chains are calculated automatically.
The EnvireGraph extends TransformGraph<Frame>. It adds functionality to
add, remove and manipulate items. Items can be used to store arbitrary data in
the graph.
Edge and vertex properties (E and V) need to follow special concepts to be compatible with
the Graph. All edge properties need to implement envire::core::EdgePropertyConcept
while all vertex properties have to implement envire::core::FramePropertyConcept.
Both concepts ensure, that the property is serializable using boost serialization
(boost::SerializableConcept) and that a string representation of the
vertex/edge can be generated. The string representation is used when
visualizing the graph.
Furthermore edge properties need to implement an inverse() method, that
inverts the meaning of the edge.
Vertex properties need to implement const FrameId& getId() and
void setId(const FrameId&). Those methods are used to store a unique
vertex identifier inside each vertex. This identifier is used as index when
storing a frame inside the graph.
Frames are vertices in the structure of the EnvireGraph and implement the
FramePropertyConcept. Each Frame stores a set of items indexed by type.
Transformations (envire::core::Transformation) are edges in the EnvireGraph.
They implement the EdgePropertyConcept and describe the spatial and temporal
displacement between frames.
The data elements that are stored in the Frames of the graph are called Items.
Every item must inherit from envire::core::ItemBase. getTypeInfo()
and getEmbeddedTypeInfo() need to be overridden to provide correct type information
about the item. getTypeInfo() should return the type_info of the item itself
while getEmbeddedTypeInfo() should return the type of the encapsulated data (i.e.
the type of the data that is returned in getRawData()).
A template (envire::core::Item<T>) that inherits from ItemBase and carries
arbitrary data T is provided for convenience. Thus manually inheriting from ItemBase
should not be necessary.
TreeViews are lightweight structures that view a portion of the graph as tree.
Views are generated by bfs-visiting the graph starting at a given frame.
All frames that are reachable from that frame will be part of the view. The structure
does not contain any loops (it is a tree, not a graph). Edges that would create
loops in the tree are called cross-edges and are stored in a special list inside
the TreeView.
A TreeView contains pointers to the actual data, thus if the underlying graph
is destroyed or manipulated, the view becomes invalid.
A TreeView can either be static or dynamic. A static view is a snapshot of the
graph at the time it was taken. I.e. it will not update or change. If the graph changes,
parts of the tree might become invalid. Accessing the graph trough a static view
after the underlying graph has changed may result in memory corruption and should
be used with care.
A dynamic TreeView is updated automatically whenever the underlying graph changes.
The view provides signals that will be emitted when that happens. Dynamic views
significantly increase the computational cost of all manipulative graph operations.
Especially the removal of edges is expensive.
The event-system is used by the Graph to inform the user about changes to the
graph structure.
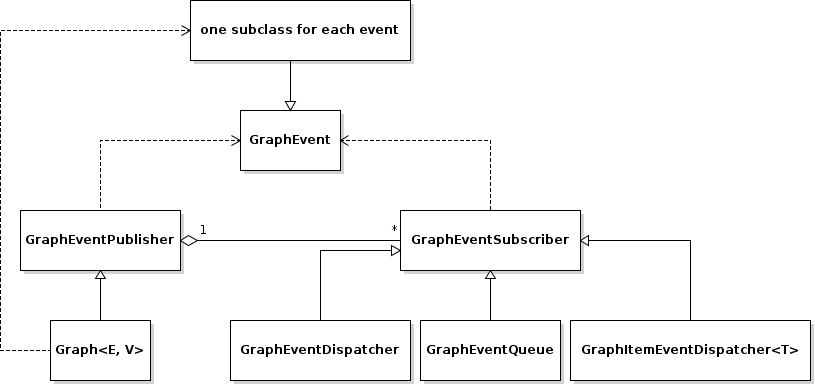
The GraphEventPublisher manages the subscribers and provides methods to
notify subscribers about events. Every class that wants to publish events
needs to extend GraphEventPublisher. Graph and its subclasses extend
this class.
In order to receive events a class needs to extend GraphEventSubscriber
and override the notifyGraphEvent() method.
Three convenience classes already exist, that do this and simplify
the usage of the event-system. Thus there is usually no need to derive from
GraphEventSubscriber directly:
-
The
GraphEventDispatcherhandles all events and provides virtual methods for each event. Thus a subscriber can simply extend the dispatcher and override the methods that it cares about. -
The
GraphEventQueuebuffers all events in a queue. Ifflush()is called, all events are processed at once. The user needs to override theprocess()method to process the events. The queue detects contradicting events and removes them from the queue. E.g. if a frame is added and removed beforeflush()is called, neither the added- nor the removed-event is processed. -
The
GraphItemEventDispatcher<T>is a special dispatcher that is used to receive typed item events. To receive only item events for a certain item type, the user should derive fromGraphItemEventDispatcher<T>whereTis the item type that he cares about.
EnviRe is designed on a modular plug-in mechanism in order to facilitate maintainability and integrability of 3rd party libraries as PCL and OctoMap.
EnviRe provides tooling to easily define and load plug-in classes. As plugin-in back-end EnviRe relies on the class_loader library. To gather and provide meta informations about all available plug-ins the plugin_manager library is used.
For more details see the chapter on plugin Design.
In order to handle user data types in EnviRe they have to be embedded into a envire::core::Item<T> class.
The Item class augments the embedded type by a time-stamp, a reference frame and an unique ID.
To register a new plug-in of the type envire::core::Item<namespace::UserType> for it’s use with EnviRe, the macro
ENVIRE_REGISTER_ITEM ( namespace::UserType ) has to be placed in a source file (*.cpp).
It adds the class loader registration macro CLASS_LOADER_REGISTER_CLASS and also registers the
class to the serialization (See the [serialization]({{site.baseurl}}/docs/core_serialization.html) section for further details).
Note that the class UserType must be serializeable by
boost serialization at that point.
In order to make the plug-in available to your system a XML file containing meta informations about the plug-in class needs to be exported.
The following example shows how a new EnviRe item, with the embedded type
boost::shared_ptr<::octomap::AbstractOcTree>, is defined in a *.cpp file:
#include <octomap/AbstractOcTree.h>
#include <boost/shared_ptr.hpp>
#include <envire_core/plugin/Plugin.hpp>
ENVIRE_REGISTER_ITEM( boost::shared_ptr<octomap::AbstractOcTree> )It is strongly recommended to use this macros when a new item is defined, since the plug-in mechanism and the serialization relay on it. Nonetheless it’s possible to define item classes without using this macro, in this case the class won’t be available as plug-in and it won’t be possible to serialize the class.
Since the embedded type must be serializeable by boost serialization, it might be necessary to implement the necessary methods in a header file.
To make the plug-in available to your system a XML file containing meta informations about the plug-in class needs to be exported. A minimal layout would look like this:
<library path="envire_octomap">
<class class_name="envire::core::Item<boost::shared_ptr<octomap::AbstractOcTree>>" base_class_name="envire::core::ItemBase">
</class>
</library>This minimal layout can be extended by a class description, associations to other types and a singleton flag. If this optional fields are not defined, the description will be empty, there won’t be any associations and the plug-in won’t be a singleton instance.
<library path="envire_octomap">
<class class_name="envire::core::Item<boost::shared_ptr<octomap::AbstractOcTree>>" base_class_name="envire::core::ItemBase">
<description>Octomap OcTree plugin</description>
<associations>
<class class_name="boost::shared_ptr<octomap::AbstractOcTree>"></class>
<class class_name="octomap::AbstractOcTree"></class>
<class class_name="octomap::OcTree"></class>
</associations>
<singleton>false</singleton>
</class>
</library>To install the XML file there is a cmake macro install_plugin_info available, which is
exported by the plugin_manager library.
rock_library(envire_octomap
SOURCES OcTree.cpp
HEADERS OcTree.hpp
DEPS_CMAKE Boost octomap
DEPS_PKGCONFIG class_loader envire_core)
install_plugin_info(envire_octomap)The macro install_plugin_info installs a file named envire_octomap.xml to the folder
lib/plugin_manager relative to the currently defined CMAKE install path.
To create an instance of a plug-in the envire::core::ClassLoader singleton class can be used.
Since EnviRe plug-ins are pure class_loader plug-ins it’s also possible to load them by using
only the class_loader library or the PluginLoader class of the plugin_manager library.
For more details read the design section of this page.
In the following example the OcTree plug-in class is loaded as abstract ItemBase class:
envire::core::ClassLoader* loader = envire::core::ClassLoader::getInstance();
if(loader->hasEnvireItem("envire::core::Item<boost::shared_ptr<octomap::AbstractOcTree>>"))
{
ItemBase::Ptr item;
if (loader->createEnvireItem("envire::core::Item<boost::shared_ptr<octomap::AbstractOcTree>>", item))
{
// A new item has been successfully created
}
}The plug-in class can be also directly casted:
envire::core::Item<boost::shared_ptr<octomap::AbstractOcTree>>::Ptr item;
envire::core::ClassLoader::getInstance()->createEnvireItem< envire::core::Item<boost::shared_ptr<octomap::AbstractOcTree>> >("envire::core::Item<boost::shared_ptr<octomap::AbstractOcTree>>", item);In this case at least the embedded type has to be known at compile time.
It is also possible to get an Item for a given embedded type by calling
the method createEnvireItemFor("boost::shared_ptr<octomap::AbstractOcTree>", item).

The EnviRe envire_core::ClassLoader relies on the plugin_manager library which relies on the
class_loader library.
The class_loader library handles the export of classes, loading of shared libraries
and the creation of new instances. More informations about the class_loader can be
found here.
The plugin_manager library handles XML files to provide a-priori meta informations
about the available plug-ins. In contrast to the ROS plugin_lib,
the plugin_manager supports singleton instances, associations and is framework
independent.
Advantages of the plugin_manager library:
-
Gather meta informations of available plugins without loading them
-
Model associations between classes
-
Support of singleton instances
-
Framework independent
The plugin_manager::PluginManager class parses all XML files and preprocesses the informations.
It can be queried about available plug-in classes, relations, associations or properties of classes.
An example of a XML file can be found in the previous section.
The plugin_manager::PluginLoader is a singleton class which on demand creates a new
class_loader::ClassLoader instance for each new library that is required. It also holds and
returns the same instance of a plug-in class if it is marked as singleton.
The envire_core::ClassLoader extends the PluginLoader by knowledge about the EnviRe
base classes.
EnviRe supports serialization and de-serialization based on the boost serialization library.
EnviRe relays on boost serialization to be able to save and load it’s internal state.
By making use of the plugin architecture, it is possible to serialize and de-serialize
Item's when knowing only their base class ItemBase.
However in this case the following methods need to be used:
envire::core::ItemBase::Ptr plugin;
// instantiate item base pointer
if (envire::core::Serialization::save(stream, plugin))
{
// plugin was successfully serialized
} envire::core::ItemBase::Ptr plugin;
if (envire::core::Serialization::load(stream, plugin))
{
// plugin was successfully de-serialized
}Also the complete graph with all it’s items can be serialized.
envire::core::EnvireGraph graph;
// fill envire graph
boost::archive::binary_oarchive oa(stream);
oa << graph; envire::core::EnvireGraph graph;
boost::archive::binary_iarchive ia(stream);
ia >> graph;In order to create a new EnviRe item and support it’s serialization the item and it’s embedded type must be serializable.
To register a new Item of type envire::core::Item<namespace::UserType> for it’s use with EnviRe, the macro
ENVIRE_REGISTER_ITEM ( namespace::UserType ) has to be placed in a source file (*.cpp).
It registers the class to the serialization by exporting the class to boost using BOOST_CLASS_EXPORT and creates a helper class which is statically instantiated as soon as the library is loaded. This allows to serialize base classes correctly even if the concrete class is not included (unknown to the implementation at runtime). However the shared library needs to be linked or dynamically loaded of course.
The serialization will try to load the necessary plugin libraries on it’s own, i.e. they have to be available on your system.
The macro will also export the class as class_loader plugin (See the [plugins]({{site.baseurl}}/docs/core_plugins.html) section for further details).
The embedded type must be serializable by boost serialization as well. This can be done by defining a intrusive or non-intrusive function. More information can be found in the [boost serialization](http://www.boost.org/libs/serialization/doc/) documentation.
// Include the actual type definition (can also be in the same header)
#include <example/DummyType.hpp>
// write non-intrusive boost serialization for DummyType (if the type is already serializable by boost the header file might not be necessary)
namespace boost { namespace serialization {
template<class Archive>
void serialize(Archive & ar, ::example::DummyType & dummy_type, const unsigned int version)
{
ar & dummy_type.member1;
ar & dummy_type.member2;
}
}}#include "DummyType.hpp"
#include <envire_core/plugin/Plugin.hpp>
// Register the new Item
ENVIRE_REGISTER_ITEM( example::DummyType )How to create and install the plugin meta-informations on your system is described in the Plugins section.
In the [ROCK](http://www.rock-robotics.org) framework types are exported using the [typelib](http://rock-robotics.org/master/api/typelib/) library. Typelib is able to automatically parse types, but has some limitations: e.g. pointer, virtual functions, private members, std library container (besides of std::vector and std::string). For those more complex classes it is possible to define so called opaque types and write methods to convert the data structure from the origin type to the opaque type and vise versa. The opaque type must be typelib compatible and does hold the same data that the origin type does.
Since EnviRe items (envire::core::Item<T>) are not typelib compatible due to it’s use of virtual functions, only the inner data container is exported to typelib.
The inner data holding container of every Item is a envire::core::SpatioTemporal<T> class. Since it is also templated with the user data type the concrete type has to
be exported to typelib. This can be achieved using the following commands in an .orogen file:
# exports the type envire::core::SpatioTemporal<example::DummyType> to typelib
typekit do
envire_someclass = spatio_temporal '/example/DummyType'
export_types envire_someclass
endNote that at this point the embedded type example::DummyType must already be known to typelib.
It can either be typelib compatible (the header of the type can be parsed), the user can write it’s own opaque type or the boost serialization based opaque auto-generation can be used.
If the embedded type isn’t directly typelib compatible the easiest way of exporting it is to make use of the fact that it is serializable by boost. To auto-generate opaque (transport) types for classes supporting boost serialization the following commands in an .orogen file can be used:
# define opaque
typekit do
opaque_autogen '/example/DummyType',
:includes => 'example/DummyType.hpp',
:type => :boost_serialization
end
# type export
typekit do
export_types '/example/DummyType'
endThis makes the type example::DummyType known to typelib.
This section contains code examples showcasing most of the envire core features. Additional there exist over 100 unit tests that show how every aspect of the framework can be used. Make sure to take a look at the tests!
Frames can be added either explicitly by calling addFrame()
EnvireGraph g;
const FrameId frame = "frame_a";
g.addFrame(frame);or implicitly by using a unknown frame id in addTransform().
EnvireGraph g;
const FrameId frameA = "frame_a";
const FrameId frameB = "frame_b";
Transform tf;
g.addTransform(frameA, frameB, tf);Frames cannot be added twice. If a frame with the given name already exists, an exception will be thrown.
The above examples will create the frame property using the default constructor.
Another constructor can be used by calling emplaceFrame(). Calling
emplaceFrame() does only make sense, if the frame property has non-default
constructors.
Frames can be removed by calling removeFrame():
EnvireGraph g;
const FrameId frame = "frame_a";
g.addFrame(frame);
g.disconnectFrame(frame);
g.removeFrame(frame);disconnectFrame() removes all transforms that are connected to the given frame.
Frames can only be removed, if they are not connected to the graph. I.e. if no
edges are connected to the frame. An exception will be thrown, if the frame is
still connected. This is an artificial restriction, technically it would be
possible to remove frames while they are still connected. The intention of this
restriction is, to make the user aware of the consequences that removing a frame
might have for the graph structure as a whole.
Before an item can be added to a frame, it has to be loaded using the ClassLoader.
#include <envire_core/plugin/ClassLoader.hpp>
#include <envire_core/items/Item.hpp>
#include <octomap/AbstractOcTree.h>envire::core::Item<boost::shared_ptr<octomap::AbstractOcTree>>::Ptr octree;
ClassLoader* loader = ClassLoader::getInstance();
if(!loader->createEnvireItem("envire::core::Item<boost::shared_ptr<octomap::AbstractOcTree>>", octree))
{
std::cerr << "Unabled to load envire::octomap::OcTree" << std::endl;
return -1;
}It is also possible to instantiate items directly, however this is only
recommended for testing because visualization and serialization only work if
the ClassLoader was used to load the item.
Once the item is loaded, there are two ways to add it to the graph.
The common way is to add it using addItemToFrame():
g.addItemToFrame(frame, octree);The item will remember the frame that it was added to. I.e. an item cannot be part of two frames at the same time.
It is also possible to set the frame id beforehand and add the item using
addItem().
octree->setFrame(frame);
g.addItem(octree);The item type can be a boost::shared_ptr to any subclass of ItemBase.
Item contains a typedef Ptr to make working with the pointer more convenient.
envire::core::Item<...>::Ptr p;When working with items, the user needs to know the item type. The type can
either be provided at compile time using template parameters or at runtime using
std::type_index.
containsItems() is used to check for the existence of items of a given type
in a given frame.
const bool contains = g.containsItems<envire::core::Item<boost::shared_ptr<octomap::AbstractOcTree>>>(frame);If the type is not known at compile time, there is also an overload that
accepts std::type_index. You can get the type index by calling
getTypeIndex() on any Item.
const std::type_index index(octree->getTypeIndex());
const bool contains2 = g.containsItems(frame, index);The ItemIterator can be used to iterate over all items of a specific type
in a frame. The iterator internally takes care of the necessary type casting
and type checks.
using OcTreeItem = envire::core::Item<boost::shared_ptr<octomap::AbstractOcTree>>;
using OcTreeItemIt = EnvireGraph::ItemIterator<envire::core::Item<boost::shared_ptr<octomap::AbstractOcTree>>>;
OcTreeItemIt it, end;
std::tie(it, end) = g.getItems<envire::core::Item<boost::shared_ptr<octomap::AbstractOcTree>>>(frame);
for(; it != end; ++it)
{
std::cout << "Item uuid: " << it->getIDString() << std::endl;
}A convenience method exist to get an ItemIterator of the i’th item:
OcTreeItemIt itemIt = g.getItem<OcTreeItem>(frame, 42);If type information is not available at compile time, getItems() can also
be used with std::type_index:
const std::type_index index2(octree->getTypeIndex());
const Frame::ItemList& items = g.getItems(frame, index2);However without compile time type information automatic type casting is not
available, thus in this case getItems returns a list of ItemBase::Ptr.
The list is returned as reference and points to graph internal memory.
Items can be removed by calling removeItemFromFrame(). Removing items invalidates
all iterators of the same type. To be able to iteratively remove items, the
method returns a new pair of iterators.
OcTreeItemIt i, endI;
std::tie(i, endI) = g.getItems<OcTreeItem>(frame);
for(; i != endI;)
{
std::tie(i, endI) = g.removeItemFromFrame(frame, i);
}All items can be removed at once using clearFrame().
g.clearFrame(frame);EnvireGraph g;
const FrameId a = "frame_a";
const FrameId b = "frame_b";
Transform ab;
/** initialize Transform */
g.addTransform(a, b, ab);If a transformation is added, the inverse will be added automatically. If one or both of the frames are not part of the graph, they will be added.
Transformations can be replaced using updateTransform.
The inverse will be updated automatically.
Transform tf;
tf.transform.translation << 84, 21, 42;
g.updateTransform(a, b, tf);getTransform() can be used to calculate the transformation between two
frames if a path connecting the two exists in the graph. Breadth first search is
used to find the path connecting the two frames.
const Transform tf2 = g.getTransform(a, b);Calculating the transformation between two frames might be expensive depending
on the complexity of the graph structure. A TreeView can be used to speed
up the calculation:
TreeView view = g.getTree(g.getVertex(a));
const Transform tf3 = g.getTransform(a, b, view);Since creating the TreeView walks the whole graph once, using this methods
only makes sense when multiple transformations need to be calculated.
If you need to calculate the same transformation multiple times, you can
use getPath() to retrieve a list of all frames that need to be traversed
to calculate the transformation. The path can be used to speed up the calculation
of the transform even further.
envire::core::Path::Ptr path = g.getPath(a, b, false);
const Transform tf4 = g.getTransform(path);TreeViews provide a tree view of the graph structure. I.e. when viewed
through a TreeView the graph turns into a tree with a specific root node.
TreeViews use vertex_descriptors instead of FrameIds to reference frames because vertex_descriptors can be hashed in constant time (they are just pointers).
TreeViews can be created by calling getTree() and providing a root node.
EnvireGraph g;
const FrameId root("root");
TreeView view = g.getTree(root);Note that the view will most likely be copied on return. If the tree is large you might want to avoid that copy and pass an empty view as out-parameter instead:
TreeView view2;
g.getTree(root, &view2);By default, a tree view shows a snapshot of the graph. I.e. if the graph changes, the changes will not be visible in the view. The view or parts of it might become invalid when vertices or edges are removed from the graph. To avoid this, you can request a self-updating tree view:
g.getTree(root, true, &view);The view has three signals crossEdgeAdded, edgeAdded and edgeRemoved
that will be emitted whenever the tree view changes.