Releases: emcie-co/parlant
v3.0.2
Added
- Added docs/* and llms.txt
- Added Vertex NLP service
- Added Ollama NLP service
- Added LiteLLM support to the SDK
- Added Gemini support to the SDK
- Added Journey.create_observation() helper
- Added auth permission READ_AGENT_DESCRIPTION
- Added optional AWS_SESSION_TOKEN to BedrockService
- Support creating status events via the API
Changed
- Moved tool call success log to DEBUG level
- Optimized canrep to not generate a draft in strict mode if no canrep candidates found
- Removed
acknowledged_event_offsetfrom status events - Removed
last_known_event_offsetfromLoadedContext.interaction
Fixed
- Fixed presentation of missing API keys for built-in NLP services
- Improvements to canned response generation
- Fixed bug with null journey paths in some cases
- Fixed tiny bug with terminal nodes in journey node selection
- Fixed evaluations not showing properly after version upgrade
v3.0.1
Today we're thrilled to announce Parlant 3.0, our most significant release yet. This version transforms Parlant into a truly production-ready conversational AI framework for customer-facing applications. With dramatic performance improvements, enhanced developer experience, and enterprise-grade security features, Parlant 3.0 is ready to fix your hardest AI consistency issues and power your most critical customer-facing applications.
What's New in Parlant 3.0
This release focuses on four major areas that matter most to teams deploying conversational AI in production:
- Latency Improvements & Perceived Performance - Dramatic speed improvements and responsive user experiences
- Enhanced Journeys - More powerful conversation flows with state diagrams and tool integration
- Canned Responses - New and improved (renamed from utterance templates), now supporting flexible composition modes
- Production Readiness - API hardening, human handoff, custom NLP services, and extreme engine extensibility
Let's dive into each area in detail.
Performance Improvements
Performance is critical for conversational AI. Users expect a responsive experience, as freezes and extended delays can break the conversational flow. Parlant 3.0 introduces significant improvements in both actual and perceived performance.
Optimized Response Generation Pipeline
We've completely redesigned our response generation pipeline with several key optimizations:
- Parallel Processing: Journey state matching happens in parallel with guideline evaluation, reducing response latency by up to 60%
- Predictive Journey Activation: The engine predicts which journeys will be activated based on conversation context, allowing preemptive state preparation
Perceived Performance with Preamble Responses
Beyond raw speed improvements, Parlant 3.0 leverages perceived performance techniques. The most impactful addition is preamble responses:
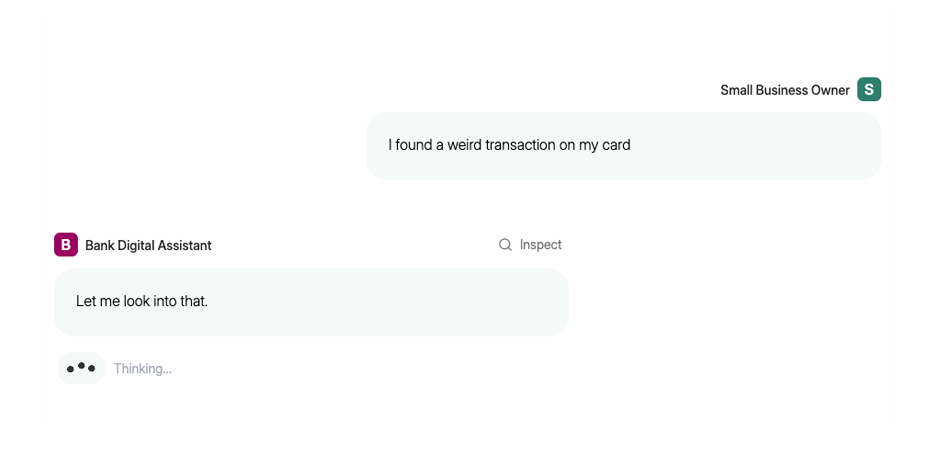
These instant acknowledgments keep users engaged while the agent processes complex requests in the background. The result is a conversational experience that feels immediate and responsive, even when performing complex operations.
Enhanced Journeys: Guiding Complex Conversations
Journeys in Parlant 3.0 have evolved into a sophisticated system for managing complex, multi-step conversations. They balance structure with flexibility, allowing agents to guide users through processes while remaining adaptive to natural conversation patterns.
Journey Architecture Improvements
Flexible State Transitions: Unlike rigid conversational frameworks, Parlant journeys allow agents to skip states, revisit previous states, or jump ahead based on context and user needs:
async def create_scheduling_journey(agent: p.Agent):
journey = await agent.create_journey(
title="Schedule Appointment",
description="Guides patients through appointment scheduling",
conditions=["The patient wants to schedule an appointment"]
)
# Create flexible state flow
t0 = await journey.initial_state.transition_to(
chat_state="Determine reason for visit"
)
t1 = await t0.target.transition_to(tool_state=get_upcoming_slots)
t2 = await t1.target.transition_to(
chat_state="Present available times"
)
# Conditional branching based on patient response
t3 = await t2.target.transition_to(
chat_state="Confirm appointment details",
condition="Patient selects a time"
)
# Alternative path for no suitable times
t4 = await t2.target.transition_to(
tool_state=get_later_slots,
condition="No suitable times available"
)
# ... additional states and transitions as needed
return journeyContext-Aware Journey Management
The engine dynamically manages which journeys are active based on conversation context, ensuring optimal performance and relevant responses:
- Dynamic Loading: Only relevant journeys are loaded into the LLM context
- Scoped Resources: Guidelines and canned responses can be scoped to specific journeys—even to specific states
Canned Responses
One of the biggest changes in Parlant 3.0 is the evolution from "utterance templates" to "Canned Responses" with flexible composition modes. This change reflects both improved functionality and clearer alignment with standard terminology.
Three Composition Modes
Parlant 3.0 introduces three distinct composition modes, each serving different use cases:
Fluid Mode
The agent prioritizes canned responses when good matches exist, but falls back to natural generation otherwise.
await server.create_agent(
name="Support Agent",
description="Helpful customer support agent",
composition_mode=p.CompositionMode.FLUID
)Use Cases:
- Prototyping agents while building response libraries
- Situations requiring mostly natural conversation with controlled responses for specific/sensitive responses
Composited Mode
The agent uses canned response candidates to alter generated messages, mimicking their style and tone.
await server.create_agent(
name="Brand Agent",
description="Agent representing our brand voice",
composition_mode=p.CompositionMode.COMPOSITED
)Use Cases:
- Brand-sensitive applications where tone consistency matters
- Maintaining voice and style guidelines across all responses
Strict Mode
The agent can only output pre-approved canned responses. If no match exists, it sends a customizable no-match message.
await server.create_agent(
name="Compliance Agent",
description="Agent for highly regulated interactions",
composition_mode=p.CompositionMode.STRICT
)Use Cases:
- High-risk environments that cannot tolerate hallucinations
- Regulated industries requiring pre-approved messaging
- Gradual UX improvement with tight control
Advanced Response Features
Dynamic Field Substitution:
await agent.create_canned_response(
template="Your current balance is {{account_balance}}"
)# Tool provides dynamic fields
@p.tool
def get_balance(context: p.ToolContext) -> p.ToolResult:
balance = fetch_balance(context.customer_id)
return p.ToolResult(
data=f"Balance: {balance}",
canned_response_fields={"account_balance": balance}
)Generative Fields for controlled localization:
await agent.create_canned_response(
template="Sorry about the delay with {{generative.item_name}}"
)Journey and State Scoping:
# Journey-scoped responses
await journey.create_canned_response(
template="Let's continue with your appointment booking"
)# State-specific responses
await state.transition_to(
chat_state="Ask for preferences",
canned_responses=[
await server.create_canned_response(
template="What type of appointment do you need?"
)
]
)No-Match Response Customization
For strict mode deployments, Parlant 3.0 provides flexible no-match response handling:
# Static no-match response
async def initialize_func(container: p.Container) -> None:
no_match_provider = container[p.BasicNoMatchResponseProvider]
no_match_provider.template = "Could you please rephrase that?"# Dynamic no-match responses
class CustomNoMatchProvider(p.NoMatchResponseProvider):
async def get_template(
self,
context: p.LoadedContext,
draft: str
) -> str:
return generate_contextual_no_match_response(context, draft)Production Readiness
Parlant 3.0 finally transforms from a prototyping framework into a production-ready platform with comprehensive enterprise features.
API Hardening with Advanced Authorization
Production deployments require robust security. Parlant 3.0 includes a complete API hardening system with fine-grained authorization and rate limiting.
Engine Extensibility with Dependency Injection
async def configure_container(container: p.Container) -> p.Container:
container[p.AuthorizationPolicy] = CustomProductionAuthPolicy(
jwt_secret=os.environ["JWT_SECRET"],
jwt_algorithm="HS256",
)
return container
async with p.Server(configure_container=configure_container) as server:
await server.serve()Human Handoff Integration
Real-world AI agents need seamless human escalation. Parlant 3.0 provides comprehensive human handoff capabilities:
Custom NLP Services
Parlant 3.0 supports complete NLP service customization for specialized models or providers:
class CustomNLPService(p.NLPService):
async def get_schematic_generator(
self,
t: type[p.T]
) -> p.SchematicGenerator[p.T]:
return CustomGenerator[p.T](model_config=self.config)
async def get_embedder(self) -> p.Embedder:
return CustomEmbedder(model_name="custom-embeddings-v2")
async def get_moderation_service(self) -> p.ModerationService:
return CustomModerationService(api_key=self.api_key)
# Inject custom NLP service
async def load_nlp_service(container: p.Container) -> p.NLPService:
return CustomNLPService(logger=container[p.Logger])
async with p.Server(nlp_service=load_nlp_service) as server:
# Agent behavior modeling code hereEngine Extensions and Hooks
Parlant 3.0 provides compr...
v2.2.0
[2.2.0] - 2025-05-20
Added
- Add journeys
- Add of guideline properties evaluation
- Add automatic guideline action deduction when adding direct tool guidelines
- Added choices of invalid and missing tool parameters to tool insights
Changed
- Make guideline action optional
v2.1.2
[2.1.2] - 2025-05-07
Changed
- Remove interaction history from utterance recomposition prompt
- Use tool calls from the entire interaction for utterance field substitution
- Improve error handling and reporting with utterance rendering failures
Fixed
- Always reason about utterance selection to improve performance
v2.1.1
[2.1.1] - 2025-04-30
Fixed
- Fixed rendering relationships in CLI
- Fixed parlant client using old imports from python client SDK
v2.1.0
[2.1.0] - 2025-04-29
Added
- ToolParameterOptions.choice_provider can now access ToolContext
- Added utterance/draft toggle in the integrated UI
- Added new guideline relationship: Dependency
- Added tool relationships and the OVERLAP relationship
- Added the 'overlap' property to tools. By default, tools will be assumed not to overlap with each other, simplifying their evaluation at runtime.
Changed
- Improved tool calling efficiency by adjusting the prompt to the tool at hand
- Revised completion schema (ARQs) for tool calling
- Utterances now follow a 2-stage process: draft + select
- Changed guest customer name to Guest
Fixed
- Fixed deprioritized guidelines always being skipped
- Fixed agent creation with tags
- Fixed client CLI exit status when encountering an error
- Fixed agent update
Known Issues
- OpenAPI tool services sometimes run into issues due to a version update in aiopenapi3
v2.0.0
[2.0.0] - 2025-04-09
Added
- Improved tool parameter flexibility: custom types, Pydantic models, and annotated ToolParameterOptions
- Allow returning a new (modified) container in modules using configure_module()
- Added Tool Insights with tool parameter options
- Added support for default values for tool parameters in tool calling
- Added WebSocket logger feature for streaming logs in real time
- Added a log viewer to the sandbox UI
- Added API and CLI for Utterances
- Added support for the --migrate CLI flag to enable seamless store version upgrades during server startup
- Added clear rate limit error logs for NLP adapters
- Added enabled/disabled flag for guidelines to facilitate experimentation without deletion
- Allow different schematic generators to adjust incoming prompts in a structured manner
- Added tags to context variables, guidelines, glossary and agents
- Added guideline matching strategies
- Added guideline relationships
Changed
- Made the message generator slightly more polite by default, following user feedback
- Allow only specifying guideline condition or action when updating guideline from CLI
- Renamed guideline proposer with guideline matcher
Fixed
- Lowered likelihood of the agent hallucinating facts in fluid mode
- Lowered likelihood of the agent offering services that were not specifically mentioned by the business
Version 1.6.7
[1.6.7] - 2025-02-23
Fixed
- Fix major issue with tool-call inference of non-string parameters on OpenAI
Version 1.6.6
[1.6.6] - 2025-02-23
Fixed
- Fix unicode generation issues in gemini
- Adapt tool calling with optional parameters
Version 1.6.5
[1.6.5] - 2025-02-20
Fixed
- Improve guideline proposer generation consistency