





InterpretML is an open-source python package for training interpretable machine learning models and explaining blackbox systems. Interpretability is essential for:
- Model debugging - Why did my model make this mistake?
- Detecting bias - Does my model discriminate?
- Human-AI cooperation - How can I understand and trust the model's decisions?
- Regulatory compliance - Does my model satisfy legal requirements?
- High-risk applications - Healthcare, finance, judicial, ...
Historically, the most interpretable machine learning models were not very accurate, and the most accurate models were not very interpretable. Microsoft Research has developed an algorithm called the Explainable Boosting Machine (EBM)* which has both high accuracy and interpretability. EBM uses modern machine learning techniques like bagging and gradient boosting to breathe new life into traditional GAMs (Generalized Additive Models). This makes them as accurate as random forests and gradient boosted trees, and also enhances their intelligibility and editability.
Notebook for reproducing table
| Dataset/AUROC | Domain | Logistic Regression | Random Forest | XGBoost | Explainable Boosting Machine |
|---|---|---|---|---|---|
| Adult Income | Finance | .907±.003 | .903±.002 | .922±.002 | .928±.002 |
| Heart Disease | Medical | .895±.030 | .890±.008 | .870±.014 | .916±.010 |
| Breast Cancer | Medical | .995±.005 | .992±.009 | .995±.006 | .995±.006 |
| Telecom Churn | Business | .804±.015 | .824±.002 | .850±.006 | .851±.005 |
| Credit Fraud | Security | .979±.002 | .950±.007 | .981±.003 | .975±.005 |
In addition to EBM, InterpretML also supports methods like LIME, SHAP, linear models, partial dependence, decision trees and rule lists. The package makes it easy to compare and contrast models to find the best one for your needs.
* EBM is a fast implementation of GA2M. Details on the algorithm can be found here.
Python 3.5+ | Linux, Mac OS X, Windows
pip install -U interpretLet's fit an Explainable Boosting Machine
from interpret.glassbox import ExplainableBoostingClassifier
ebm = ExplainableBoostingClassifier()
ebm.fit(X_train, y_train)
# EBM supports pandas dataframes, numpy arrays, and handles "string" data natively.Understand the model
from interpret import show
ebm_global = ebm.explain_global()
show(ebm_global)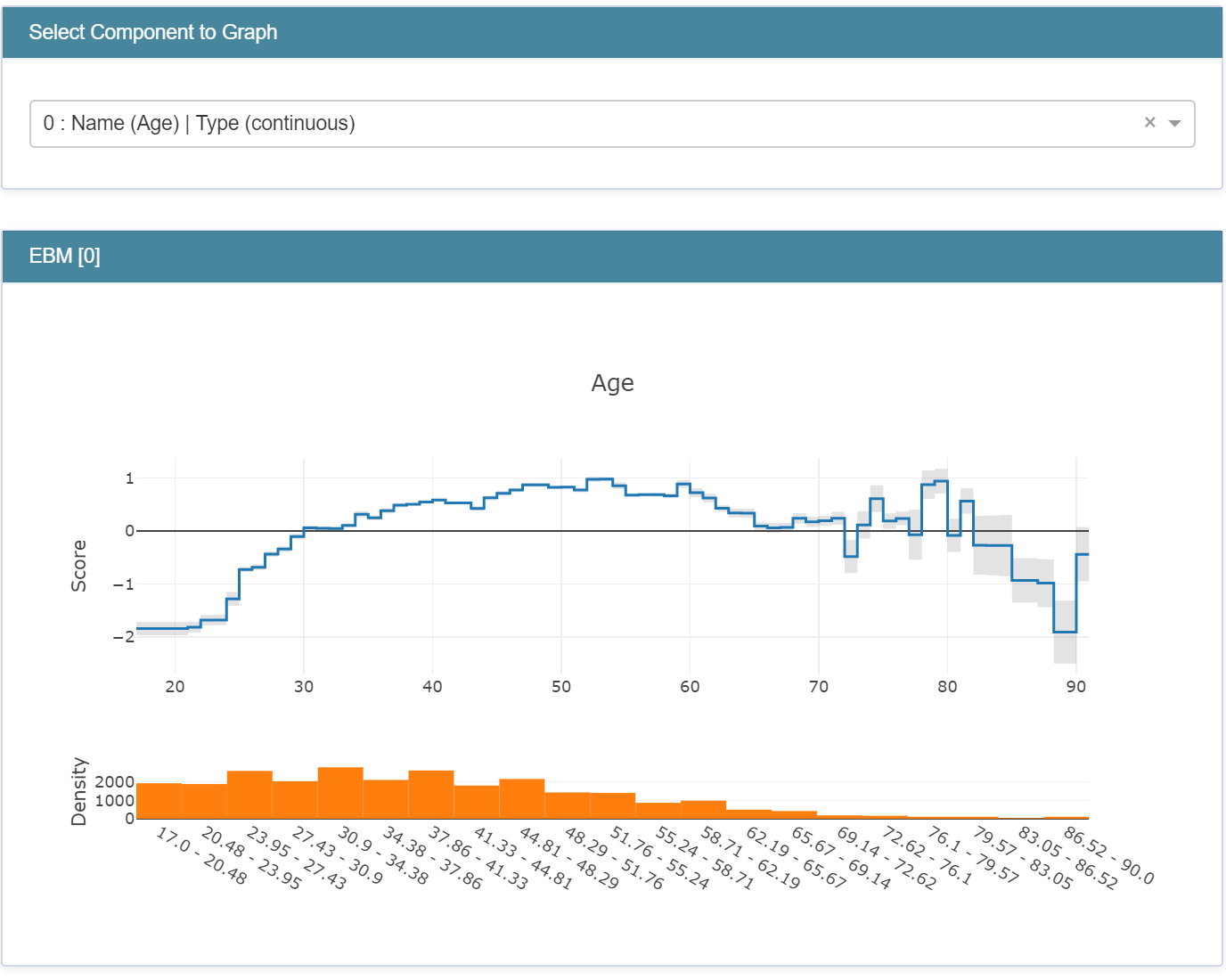
Understand individual predictions
ebm_local = ebm.explain_local(X_test, y_test)
show(ebm_local)
And if you have multiple models, compare them
show([logistic_regression, decision_tree])
- Interpretable machine learning models for binary classification
- Interpretable machine learning models for regression
- Blackbox interpretability for binary classification
- Blackbox interpretability for regression
Currently we're working on:
- R language interface (R is currently a WIP. Basic EBM classification can be done via the ebm_classify & ebm_predict_proba functions, but the predictions are a bit less accurate than in python. No plotting included yet, but other R plotting tools can do a basic job visualizing EBM models)
- Missing Values Support
- Improved Categorical Encoding
- Interaction effect purification (see citations for details)
...and lots more! Get in touch to find out more.
If you are interested contributing directly to the code base, please see CONTRIBUTING.md.
InterpretML was originally created by (equal contributions): Samuel Jenkins, Harsha Nori, Paul Koch, and Rich Caruana
Many people have supported us along the way. Check out ACKNOWLEDGEMENTS.md!
We also build on top of many great packages. Please check them out!
plotly | dash | scikit-learn | lime | shap | salib | skope-rules | treeinterpreter | gevent | joblib | pytest | jupyter
InterpretML
"InterpretML: A Unified Framework for Machine Learning Interpretability" (H. Nori, S. Jenkins, P. Koch, and R. Caruana 2019)
@article{nori2019interpretml,
title={InterpretML: A Unified Framework for Machine Learning Interpretability},
author={Nori, Harsha and Jenkins, Samuel and Koch, Paul and Caruana, Rich},
journal={arXiv preprint arXiv:1909.09223},
year={2019}
}
Paper link
Explainable Boosting
"Intelligible models for healthcare: Predicting pneumonia risk and hospital 30-day readmission" (R. Caruana, Y. Lou, J. Gehrke, P. Koch, M. Sturm, and N. Elhadad 2015)
@inproceedings{caruana2015intelligible,
title={Intelligible models for healthcare: Predicting pneumonia risk and hospital 30-day readmission},
author={Caruana, Rich and Lou, Yin and Gehrke, Johannes and Koch, Paul and Sturm, Marc and Elhadad, Noemie},
booktitle={Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining},
pages={1721--1730},
year={2015},
organization={ACM}
}
Paper link
"Accurate intelligible models with pairwise interactions" (Y. Lou, R. Caruana, J. Gehrke, and G. Hooker 2013)
@inproceedings{lou2013accurate,
title={Accurate intelligible models with pairwise interactions},
author={Lou, Yin and Caruana, Rich and Gehrke, Johannes and Hooker, Giles},
booktitle={Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining},
pages={623--631},
year={2013},
organization={ACM}
}
Paper link
"Intelligible models for classification and regression" (Y. Lou, R. Caruana, and J. Gehrke 2012)
@inproceedings{lou2012intelligible,
title={Intelligible models for classification and regression},
author={Lou, Yin and Caruana, Rich and Gehrke, Johannes},
booktitle={Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining},
pages={150--158},
year={2012},
organization={ACM}
}
Paper link
"Axiomatic Interpretability for Multiclass Additive Models" (X. Zhang, S. Tan, P. Koch, Y. Lou, U. Chajewska, and R. Caruana 2019)
@inproceedings{zhang2019axiomatic,
title={Axiomatic Interpretability for Multiclass Additive Models},
author={Zhang, Xuezhou and Tan, Sarah and Koch, Paul and Lou, Yin and Chajewska, Urszula and Caruana, Rich},
booktitle={Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery \& Data Mining},
pages={226--234},
year={2019},
organization={ACM}
}
Paper link
"Distill-and-compare: auditing black-box models using transparent model distillation" (S. Tan, R. Caruana, G. Hooker, and Y. Lou 2018)
@inproceedings{tan2018distill,
title={Distill-and-compare: auditing black-box models using transparent model distillation},
author={Tan, Sarah and Caruana, Rich and Hooker, Giles and Lou, Yin},
booktitle={Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society},
pages={303--310},
year={2018},
organization={ACM}
}
Paper link
"Purifying Interaction Effects with the Functional ANOVA: An Efficient Algorithm for Recovering Identifiable Additive Models" (B. Lengerich, S. Tan, C. Chang, G. Hooker, R. Caruana 2019)
@article{lengerich2019purifying,
title={Purifying Interaction Effects with the Functional ANOVA: An Efficient Algorithm for Recovering Identifiable Additive Models},
author={Lengerich, Benjamin and Tan, Sarah and Chang, Chun-Hao and Hooker, Giles and Caruana, Rich},
journal={arXiv preprint arXiv:1911.04974},
year={2019}
}
Paper link
LIME
"Why should i trust you?: Explaining the predictions of any classifier" (M. T. Ribeiro, S. Singh, and C. Guestrin 2016)
@inproceedings{ribeiro2016should,
title={Why should i trust you?: Explaining the predictions of any classifier},
author={Ribeiro, Marco Tulio and Singh, Sameer and Guestrin, Carlos},
booktitle={Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining},
pages={1135--1144},
year={2016},
organization={ACM}
}
Paper link
SHAP
"A Unified Approach to Interpreting Model Predictions" (S. M. Lundberg and S.-I. Lee 2017)
@incollection{NIPS2017_7062,
title = {A Unified Approach to Interpreting Model Predictions},
author = {Lundberg, Scott M and Lee, Su-In},
booktitle = {Advances in Neural Information Processing Systems 30},
editor = {I. Guyon and U. V. Luxburg and S. Bengio and H. Wallach and R. Fergus and S. Vishwanathan and R. Garnett},
pages = {4765--4774},
year = {2017},
publisher = {Curran Associates, Inc.},
url = {http://papers.nips.cc/paper/7062-a-unified-approach-to-interpreting-model-predictions.pdf}
}
Paper link
"Consistent individualized feature attribution for tree ensembles" (Lundberg, Scott M and Erion, Gabriel G and Lee, Su-In 2018)
@article{lundberg2018consistent,
title={Consistent individualized feature attribution for tree ensembles},
author={Lundberg, Scott M and Erion, Gabriel G and Lee, Su-In},
journal={arXiv preprint arXiv:1802.03888},
year={2018}
}
Paper link
"Explainable machine-learning predictions for the prevention of hypoxaemia during surgery" (S. M. Lundberg et al. 2018)
@article{lundberg2018explainable,
title={Explainable machine-learning predictions for the prevention of hypoxaemia during surgery},
author={Lundberg, Scott M and Nair, Bala and Vavilala, Monica S and Horibe, Mayumi and Eisses, Michael J and Adams, Trevor and Liston, David E and Low, Daniel King-Wai and Newman, Shu-Fang and Kim, Jerry and others},
journal={Nature Biomedical Engineering},
volume={2},
number={10},
pages={749},
year={2018},
publisher={Nature Publishing Group}
}
Paper link
Sensitivity Analysis
"SALib: An open-source Python library for Sensitivity Analysis" (J. D. Herman and W. Usher 2017)
@article{herman2017salib,
title={SALib: An open-source Python library for Sensitivity Analysis.},
author={Herman, Jonathan D and Usher, Will},
journal={J. Open Source Software},
volume={2},
number={9},
pages={97},
year={2017}
}
Paper link
"Factorial sampling plans for preliminary computational experiments" (M. D. Morris 1991)
@article{morris1991factorial,
title={},
author={Morris, Max D},
journal={Technometrics},
volume={33},
number={2},
pages={161--174},
year={1991},
publisher={Taylor \& Francis Group}
}
Paper link
Partial Dependence
"Greedy function approximation: a gradient boosting machine" (J. H. Friedman 2001)
@article{friedman2001greedy,
title={Greedy function approximation: a gradient boosting machine},
author={Friedman, Jerome H},
journal={Annals of statistics},
pages={1189--1232},
year={2001},
publisher={JSTOR}
}
Paper link
Open Source Software
"Scikit-learn: Machine learning in Python" (F. Pedregosa et al. 2011)
@article{pedregosa2011scikit,
title={Scikit-learn: Machine learning in Python},
author={Pedregosa, Fabian and Varoquaux, Ga{\"e}l and Gramfort, Alexandre and Michel, Vincent and Thirion, Bertrand and Grisel, Olivier and Blondel, Mathieu and Prettenhofer, Peter and Weiss, Ron and Dubourg, Vincent and others},
journal={Journal of machine learning research},
volume={12},
number={Oct},
pages={2825--2830},
year={2011}
}
Paper link
"Collaborative data science" (Plotly Technologies Inc. 2015)
@online{plotly,
author = {Plotly Technologies Inc.},
title = {Collaborative data science},
publisher = {Plotly Technologies Inc.},
address = {Montreal, QC},
year = {2015},
url = {https://plot.ly} }
Link
"Joblib: running python function as pipeline jobs" (G. Varoquaux and O. Grisel 2009)
@article{varoquaux2009joblib,
title={Joblib: running python function as pipeline jobs},
author={Varoquaux, Ga{\"e}l and Grisel, O},
journal={packages. python. org/joblib},
year={2009}
}
Link
- A gentle introduction to GA2Ms, a white box model
- On Model Explainability: From LIME, SHAP, to Explainable Boosting
- Benchmarking and MLI experiments on the Adult dataset
- Dealing with Imbalanced Data (Mortgage loans defaults)
- Kaggle PGA Tour analysis by GAM
- Interpretable Prediction of Goals in Soccer
- Explaining Model Pipelines With InterpretML
- Explain Your Model with Microsoft’s InterpretML
There are multiple ways to get in touch:
- Email us at [email protected]
- Or, feel free to raise a GitHub issue