Do not identify observation by token only. #173
Comments
|
Ok, here's a proposal: we introduce a new interface WDYT? |
|
It sounds good. |
|
Just to be clear, this basically means replacing the InetAddress/port combination everywhere throughout Californium/Scandium with a source and destination Still sounds like a good idea? My feeling is that we would need to change around 30 percent of the classes in the project ... don't get me wrong, I believe this is the right thing to do but it will take some time to actually do it ... |
|
I thought you just plan to change the way we identify observation not all messages. |
|
That data would still be available, but only as part of the |
|
Though currently the observe is the trigger, I could life with reduce the scope to that for the first step. |
|
Let's think about the API. Currently the API looks like this : // create request
Request request = new Request(Code.GET);
request.setObserve();
request.setURI("my/path");
request.setDestination(destinationAddress)
// listen new notification
endpoint.addNotificationListener(new NotificationListener() {
@Override
public void onNotification(Request request, Response response) {
System.out.println("Get new notification :" + response);
}
});
// send request
endpoint.sendRequest(request);
// receive response which acknowledge observation relation
Response response = request.waitForResponse();
// do some stuff ...
// cancel observation
endpoint.cancelObservation(request.getToken());How does it looks like with this new kind of observation identifier (token+endpoint identifier) // create request
Request request = new Request(Code.GET);
request.setObserve();
request.setURI("my/path");
request.setDestination(destinationAddress)
// listen new notification
endpoint.addNotificationListener(new NotificationListener() {
@Override
public void onNotification(Request request, Response response) {
System.out.println("Get new notification :" + response);
}
});
// send request
endpoint.sendRequest(request);
// receive response which acknowledge observation relation
Response response = request.waitForResponse();
// do some stuff ...
// cancel observation :
// this one could be used when there is no authentication or if you keep a reference to the response
endpoint.cancelObservation(response.getSourceEndpointIdentifier(), request.getToken());
// or
endpoint.cancelObservation(new PSKIdentifier(pskIdentity, request.getToken());
// or
endpoint.cancelObservation(new RPKIdentifier(publicKey, request.getToken());
// or
endpoint.cancelObservation(new X509CommonNameIdentifier(commonName, request.getToken());
// or
endpoint.cancelObservation(new SocketIdentifier(peerAddress, request.getToken());I think all of this is also linked to this issue #104. // create request
Request request = new Request(Code.GET);
request.setURI("my/path");
request.setDestination(destinationAddress)
// send request
endpoint.sendRequest(new PSKIdentifier(pskIdentifiy), request); or // create request
Request request = new Request(Code.GET);
request.setURI("my/path");
request.setDestinationIdentifier(new PSKIdentifier(pskIdentity));
request.setDestination(destinationAddress)
// send request
endpoint.sendRequest(request); Then ideally application layer should be notified if the request is not delivered because identity does not matched. request.addMessageObserver(new MessageObserverAdapter() {
@Override
public void onResponse(Response response) {
}
@Override
public void onDropped(String reason) {
// or maybe a onDropped(Exception reason) signature
}
});WDYT ? |
|
So you would add the "EndpointIdentifier" to the response? This indicates to me, that you don't have the EndpointIdentifier when you create the request. |
|
Based on @sbernard31's comment regariding keeping the scope of this issue limited, I am currently only using |
|
I still don't understand, how we can create a unique <token + EndpointIdentifier> pair, if we don't know the EndpointIdentifier. Or is it intended, that tokens are unique by them self? |
|
No, the tokens are only unique within the context of the peer endpoint. This is one of the problems we want to address in this issue. |
|
Currently, the TokenProvider create unique token across all the peer endpoint. But If we finally aim unique token by peer, I think using random generation is enough (without reservation). How many exchange by peer at the same time ? 1, 5, 10 maybe 50 ? chances of collision are really slow : 50 on 2^64 = 1,844674407×10¹⁹. |
|
I looked at the branch, the whole If I well understand, this API seems a bit less intuitive than what I propose above, but this is also less code modification. |
|
Or, instead of removing keys, add an additional matcher method to |
I seem to have been mistaken regarding the tokens :-) We seem to have agreed some time ago that the token space would be large enough to be shared by all peers. If we only consider the problem of making sure that a notification received over DTLS can be matched with the corresponding entry in the ObservationStore on a single node then this should actually work. However, considering the case we introduced the ObservationStore for in the first place, i.e. fail-over between nodes, the problem still seems to exist. FMPOV we could/should defer setting the token (and maybe the MID as well) to when we have established the destination |
|
Having taken a look again at |
It is actually quite the same if you keep in mind that In most cases you wouldn't even care about the particular type/instance because the |
We are actually doing this already because we are keeping the original |
|
Ouch, it's hard to answer to all of this.
Not exactly, as timeout is just for ACK, not for response.
Ok but the idea was to avoid token collision, not just to be able to release token ^^. If we use address+token, you can have the same device which can use 2 different addresses and the same token. The collision is not detected... As I explained above this kind of collision is extremely unlikely so from my point of view we can just start without this mechanism of reserve/release for TokenProvider.
It sounds really strange to me oO.
Not exactly. Currently in CorrelationContext there is a lot of information. Intuitively when you implement your observationStore you will use the whole context as endpoint key (as you described in javadoc)but most of the time we don't want to do that. So in observation store, you need to extract from this context what you want to use as key. Not so good in term of separation of concerns. What I have in mind is that EndpointIdentifier and CorrelationContext was 2 differents concepts. I'm not sure this is clear enough ... |
You're right, this is exactly what @joemag1 pointed out in #73 (which we never fixed BTW). |
What kind of collision are we actually talking about and what is the scenario where we are facing a problem? Please keep in mind that we are identifying observe relations by means of the |
|
Already explained, but I can try better. eg : I repeat again, I don't consider this collision is a real problem as this will probably never happened. My conclusion is that if we succeed to identify observation by endpointIdentifier+token we don't need anymore to reserve/release token generate it randomly is enough. |
|
|
I looked at it. If we want to exclude the nasty effects of token collisions, then we should agree, that the identity must be passed in along with the request. If we agree on that, I think your branch will change, but not too much. In general it points in the right direction. (So the pain from the token scope in RFC7252 (short term intended) with a "long term usage" of the RFC7641 grows :-) .) |
|
About TokenProvider, It's hard to get your opinion :). Does it mean you think this is a problem or not ? or maybe this means you don't know ? |
I "don't know" :-). But analysing a token collision would be hard. |
|
I think the token space is large enough to keep the risk of running out of tokens during runtime at a very low level. I cannot quite follow the argument that there is no risk simply because of the size of the token space. That seems to assume that the random function is distributed perfectly equally (which it probably isn't). I therefore do think that we need to prevent token collisions. Given the sheer number of available tokens we could, however, just keep one instance of However, I think we need to make sure that we are not leaking tokens too easily, i.e. that all tokens are released eventually, either explicitly (if the exchange is complete or the observe relation is canceled) or implicitly because the token hasn't been used for a long period. This doesn't affect the need to qualify the tokens with the |
see : https://docs.oracle.com/javase/7/docs/api/java/util/Random.html |
|
Some math to help to the decision : We have 2^64 possibilities. (number of days in our "year" ^^) What is the chance to have collision. (6,7*10^-19 for 5 requests) |
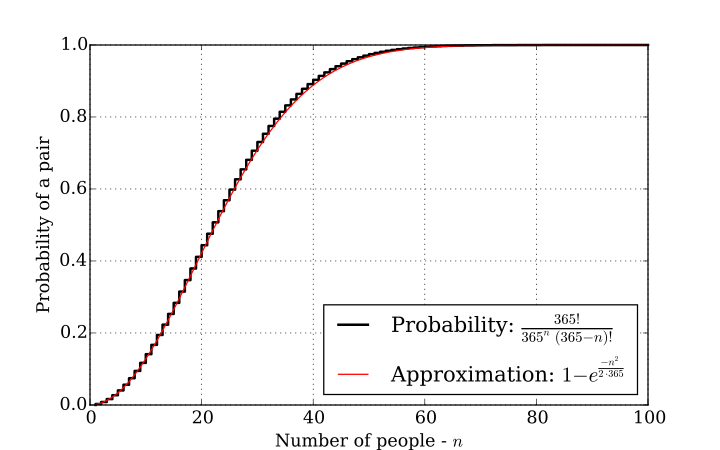
|
I would like to move forward on this. |
|
From my side, I can live with both: a.) either rely on the unique token by random If we go for a.) then I'm not sure, why we should introduce But I'm not sure, how we would map a notification from a coap-server with a changed ip-address/port. |
|
You're right, if we go for If we go for In all case I think, we will need something like About Mapping observation with a changed ip-address/port : |
|
I'm not sure, if you have exchanged a) and b). Because a) rely on a "random token is unique", why should then a cluster have a special handling for token generation? |
|
Oops I have exchanged a) and b). |
|
Just to mention: |
|
FMPOV the problem is not that there will be some collisions, and according to @sbernard31's reference to the birthday problem the probability will be quite low. The interesting question for me is: what happens if there is a collision? Are we able to detect a collision and act accordingly? What is a proper reaction in case of a collision? As long as we do not have answers to these questions, AFAIC the low probability of occurrence is not a sufficient argument for not having tokens being qualified by the endpoint identifier. As I have already layed out before, I guess we can make this work for both cases: if client code already has a grip on the target's EndpointIdentifier, then it can set it on the request. If not, then we can set the EndpointIdentifier when sending out the message at the connector layer. |
This is not what I advocate.
|
|
So we seem to agree that we want to qualify each token with the EndpointIdentifier, right? |
|
Yes but if we do that, how do we deal with the token provider ? 1. remove reserve/release token, random generation only. 2. reserve/release token by endpoint identifier 3. reserve/release token for all peer, so 2 peers can not use the same token. |
|
So, let me try to get this straight. We need to find answers to two questions:
My understanding is that for the second question we agree to use the EndpointIdentifier in conjunction with the token used for the observe relation, right? So the idea would be that whenever we put an observe request to the So, now we are discussing how to deal with the first problem. My understanding here is that you, @sbernard31, propose to rely on the fact that collisions are very unlikely even if we simply create the tokens randomly (using the system's PRNG). Together with the fact that in the DTLS case we are using additional properties (session ID, cypher) to correlate a response with a request, I tend to agree with you that this is acceptable. |
|
For me this seems, that we still have a open/ongoing discussion. And the current implementation seems also to require some more work ( @vikram919 point in #219 (comment) to the special token usage in multicast (requires uniqueness for token across address/port). So I guess, after 2.0.0-M6 we have to "finalize this again" :-). |
|
Closed with PR #521 |
Currently, Observation is identify by token in observation store.
We should identify it by token + a peer identifier.
I recommend that peer identifier was :
- peer-address for unsecure connection
- DTLS identity for secure connection or session if there is not authentication
As there is no real consensus on this, I suppose we should find a way to allow users to bring its own behavior.
The text was updated successfully, but these errors were encountered: