{kind=link}
This README discusses the installation and configuration instructions for the Sysdig datasource plugin for Grafana.

The Sysdig datasource plugin is currently in BETA and tested with Grafana version up to 8.5.5.
NOTE: this plugin is not supported with later versions of Grafana. Instead, use the official Prometheus data source plugin to query the Sysdig API. For more info: Sysdig Docs.
Known limitations of the Sysdig datasource plugin are listed below:
- Annotations are leveraged to show Sysdig events, but not broadly supported.
- With Grafana you can enter any arbitrary time range, but data will be fetched according to retention and granularity restrictions as explained in Sysdig Docs.
There are several installation approaches available for the Sysdig datasource plugin.
Note: The Sysdig datasource plugin is currently not included in the official & community built plugin page, and needs to be installed manually.
| Grafana Version | Plugin Version |
|---|---|
| <= 7.3.10 | <= 0.10 |
| 7.4.0 - 8.5.5 | 0.11 |
Note: Starting from version 8, Grafana will not load unsigned plugins.
To load the sysdig plugin you must set the allow_loading_unsigned_plugins property. (E.g.allow_loading_unsigned_plugins=sysdig)
For more information about the configuration files, refer to the Grafana docs.
We offer a Docker container image based on Grafana that comes with the plugin pre-installed:
docker run -d -p 3000:3000 -e GF_PLUGINS_ALLOW_LOADING_UNSIGNED_PLUGINS=sysdig --name grafana sysdiglabs/grafana:latest
For more information, refer to the Docker Hub repository page.
Alternatively, the default Grafana container image can be used as is, and the plugin directory can be mounted on the host to make it available in the container:
- Prepare the Grafana data directory and download the plugin:
mkdir grafana-data
mkdir grafana-data/plugins
curl https://download.sysdig.com/stable/grafana-sysdig-datasource/grafana-sysdig-datasource-v0.11.tgz -o sysdig.tgz
tar zxf sysdig.tgz -C grafana-data/plugins
- Start the container with the current user, to give read/write permissions to the data directory:
ID=$(id -u)
docker run -d --user $ID --volume "$PWD/grafana-data:/var/lib/grafana" -p 3000:3000 -e GF_PLUGINS_ALLOW_LOADING_UNSIGNED_PLUGINS=sysdig grafana/grafana:latest
For more information, refer to the Grafana installation documentation and the Docker documentation.
These instructions will often apply to container-based platforms such as kubernetes and is focused more on how to codify the installation and configuration of the datasource & dashboards. Grafana supports many dynamic configuration capabilites such as using Environment Variables or loading in dashboard and datasource configurations.
You can refer to CONFIGURE_AS_CODE file for instructions.
The plugin can be installed on any host where Grafana is installed. To install the plugin:
- Open a shell terminal.
- Run the series of commands below:
curl https://download.sysdig.com/stable/grafana-sysdig-datasource/grafana-sysdig-datasource-v0.11.tgz -o sysdig.tgz
tar zxf sysdig.tgz
sudo cp -R sysdig /var/lib/grafana/plugins
sudo service grafana-server restart
Note: Grafana plugins are installed in
/usr/share/grafana/plugins. However, the Sysdig plugin must be installed in/var/lib/grafana/pluginsinstead.
- Open a shell terminal.
- Run the series of commands below:
curl https://download.sysdig.com/stable/grafana-sysdig-datasource/grafana-sysdig-datasource-v0.11.tgz -o sysdig.tgz
tar zxf sysdig.tgz
cp -R sysdig /usr/local/var/lib/grafana/plugins
brew services restart grafana
Note: For more information, refer to the Grafana installation on Mac documentation.
- Download the plugin from: https://download.sysdig.com/stable/grafana-sysdig-datasource/grafana-sysdig-datasource-v0.11.zip
- Install the plugin in the Grafana plugins folder.
- Restart Grafana.
Note: For more information, refer to the Grafana installation on Windows documentation.
To add a datasource to Grafana:
- Open Grafana.
- On the Datasources tab, click the Add Data Sources button.
- Define a name for the datasource.
- Open the Type dropdown menu, and select Sysdig.
- Open the Plan dropdown menu, and select either Basic/Pro Cloud for Sysdig SaaS or Pro Software for on-premises installations.
- Open the Sysdig UI, and navigate to Settings -> User Profile -> Sysdig Monitor API token.
- Copy the API token, and paste it into the API Token field in Grafana.

Custom panels can be added once the Sysdig datasource is installed. Any panel supported by Grafana can be used.
Note: For more information, refer to the Grafana documentation website.
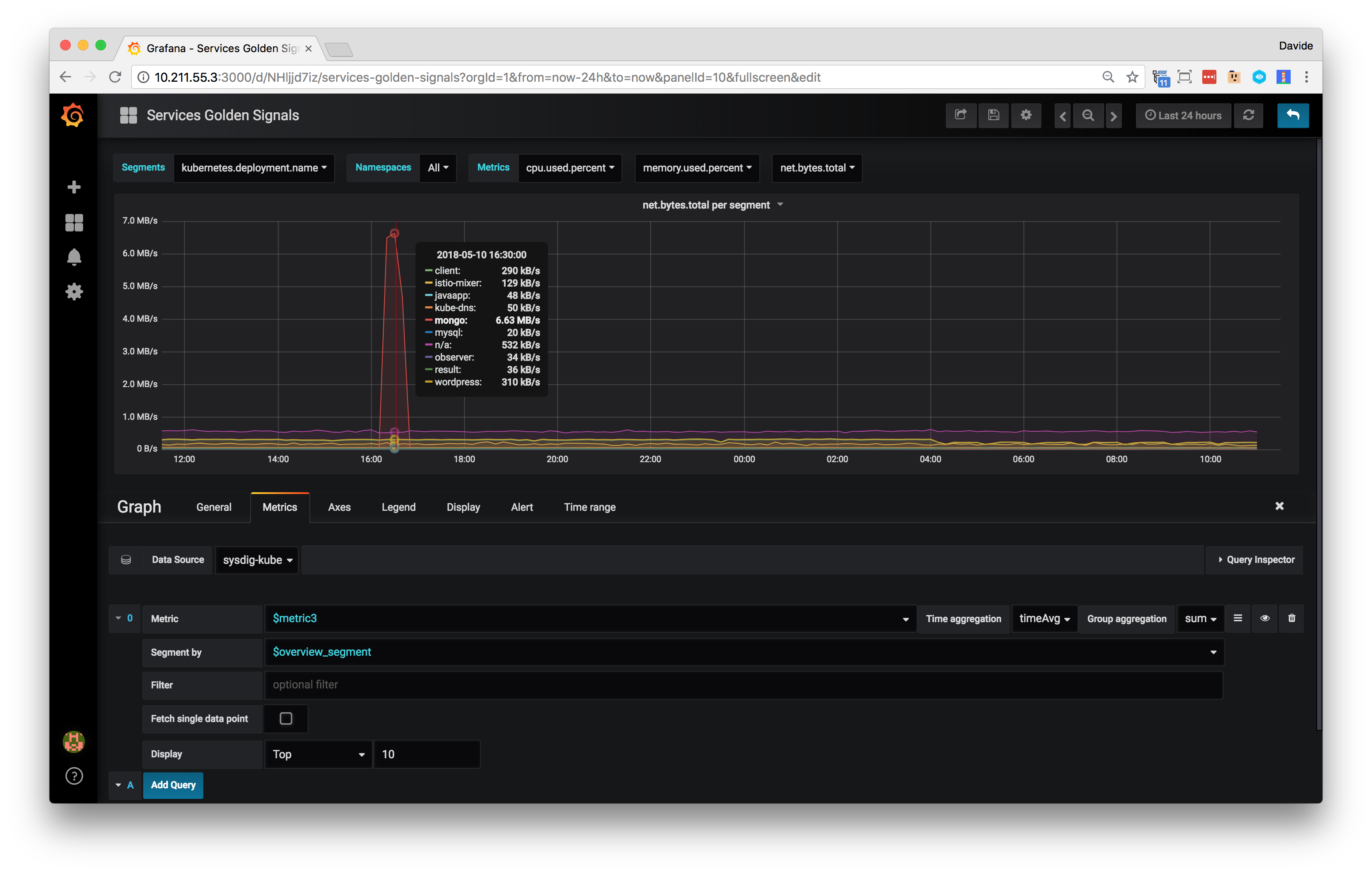
In Sysdig, number panels, bar charts and histograms display aggregated data (i.e. a single data point across the entire time window). By default, Grafana loads time series and then applies an additional aggregation to data points to calculate a single value (displayed in the Singlestat panel for instance).
Note: To maintain the same aggregation mechanism and precision offered by the Sysdig API, create panels with the "Fetch single data point" flag turned on. This will instruct the datasource to make an aggregated data request to the API.
Starting from Grafana 7.4, and Sysdig plugin 0.11, the table panel must be created with the "Fetch as table" flag turned on.
This flag can be used also with other Grafana panel types that requires data in a table format, like Bar chart and Bar gauge.
Note: no migration is required for the existing panels.
A panel can be configured with an optional filter to fetch data for a subset of the infrastructure or only for a given label.
The filter is a string, and should follow the Sysdig filtering language syntax:
- The syntax of an expression is
label_name operator "label_value"(double-quotes are mandatory) - Expressions can be combined with the boolean operators and/or (
expression and expression or expression) - The following operators are supported:
=and!=(e.g.name = "value"orname != "value")containsandnot ... contains(e.g.name contains "value"ornot name contains "value")inandnot... in(e.g.name in ("value-1", "value-2")ornot name in ("value-1", "value-2"))
- Valid label names are essentially the ones used for the segmentation (use the Segment by dropdown to review what is needed).
Some examples:
host.hostName = "ip-1-2-3-4"cloudProvider.availabilityZone = "us-east-2b" and container.name = "boring_sinoussi"(wherecloudProvider.*are labels coming from AWS)kubernetes.namespace.name = "java-app" and kubernetes.deployment.name in ("cassandra", "redis")
The Sysdig datasource tries to name panel graphical element (eg. graph line, or table column) so that the legend can clearly identify what eacy element refers to (eg. which process, or host, or container).
In some cases, the default configuration is not enough.
You can use the alias field to configure how elements of a query should be named in the panel. Here's what you can do:
- Any literal text will be used as is (eg.
host:) - The following patterns are available
{{metric}}will be replaced with the metric name (eg.cpu.used.percent){{segment_name}}will be replaced with the segment label name (eg.proc.name){{segment_value}}will be replaced with the segment value name (eg.cassandra)
- Each pattern can also use the following modifiers:
{{pattern:X:Y}}whereXis the number of characters to be used at the beginning, andYis the number of characters to be used from the end. Example:{{segment_value:4:6}}forsysdig-34e2a10ccwould be replaced withsysd..2a10cc{{pattern /regular expression/}}will be replaced with the result of the regular expression, where only capturing groups will be used. Example:{{segment_value /(\w+)$/}}forsysdig-34e2a10ccwould be replaced with34e2a10cc. Please refer to Regular Expressions guide on MDN for additional information about regular expressions
Here's an example:

The Sysdig datasource plugin supports variables, allowing for dynamic and interactive dashboards to be created.
Note: Sysdig recommends reviewing the Grafana Variables documentation for use cases, examples, and more.
Variables can be used to configure any property of a dashboard panel:
- Metric: Select the metric name to use for the panel query
- Time and group aggregations: Select the aggregation (basic aggregations are
timeAvgfor rate,avg,sum,min,max) - Segmentation (Segment by fields): Select the label name to segment data
- Filter: Use either label names or label values to define a data filter
- Display direction: Select to show top or bottom values (valid values are
descandtopfor "top values", orascandbottomfor "bottom values") - Display paging: Select how many elements to show
The following list shows how variables can be configured:
- Query, custom, and constant variable types are supported
- The query for a metric name can use the function
metrics(pattern)that returns a list of metrics matching the specificpatternregex - The query for a label name can use the function
label_names(pattern)that returns a list of label names matching the specificpatternregex - The query for a label value can use the function
label_values(label_name)that returns a list of label values for the specified label name - A label value can be configured with multi-value and/or include all option properties enabled only with
inandnot ... inoperators
Please note that metric name and label name variables cannot have multi-value or include all option properties enabled
Variables can be created to identify a metric name, and then use it to configure a panel with a dynamic metric.
A couple of notes about variables for metric names:
- Query, Custom, or Constant variables can be used.
Note: Please note that the Multi-value and Include All options must be disabled.
- Query variables can use the
metrics(pattern)function, that returns a list of metrics matching the specificpatternregex.

Label names are used for panel segmentations (Segment by field) and filters.
A couple of notes about variables for label names:
- Query, Custom, or Constant variables can be used.
Note: Please note that the Multi-value and Include All options must be disabled.
- Query variables can use the
label_names(pattern)function, that returns a list of label names matching the specificpatternregex.


Label values are used in filters to identify a subset of the infrastructure or data in general, allowing users to create a row per service, or use a single dashboard to analyze all available applications.
Some notes about variables for label values:
- You can use a Query, Custom, or Constant variables.
- Query variables can use the
label_values(label_name)function, that returns a list of label values for the specified label name. - The query accepts the following optional parameters:
filterto limit the list of values according to the specified filter. Example:label_values(kubernetes.namespace.name, filter='kubernetes.deployment.name = "foo"')to return a list of Kubernetes namespaces within the Kubernetes deployment namedfoo. You can also refer to other variables in the filter for an additional level of customization in dashboardsfrom,to,limitto control the subset of values to show in the menu in the dashboard (by default,from=0, to=99to return the first 100 entries)
- Multi-value variables, or variables with the Include All option enabled can only be used with
inandnot ... inoperators. - Variables must not be enclosed by quotes.
Note: The final string will contain quotes when needed (e.g.
$name = $valuewill be resolved tometric = "foo").


The complete example below contains dynamic rows and panels:

We'd love to hear from you! Join our Public Slack channel (#grafana) for announcements and discussions.