Tensor parallelism for Mixture of Experts #63
Merged
+44
−23
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Author
|
Comparing loss curves with no tensor parallelism
|
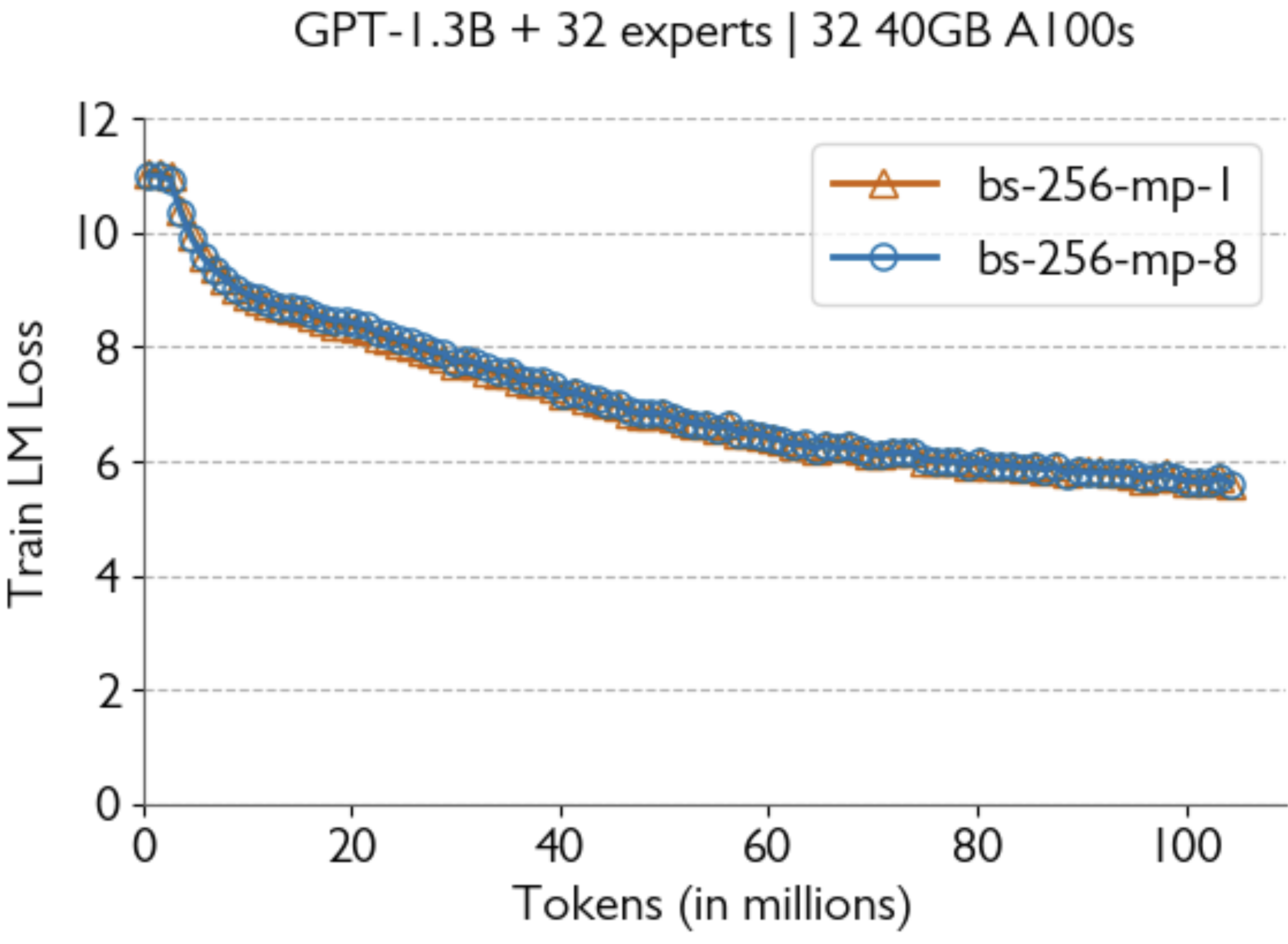
awan-10
reviewed
Jul 11, 2022
awan-10
reviewed
Jul 15, 2022
awan-10
reviewed
Jul 15, 2022
Author
|
Here are the loss curves when tensor parallelism is used for both the experts and non experts. Note: these were buggy and were fixed subsequently |
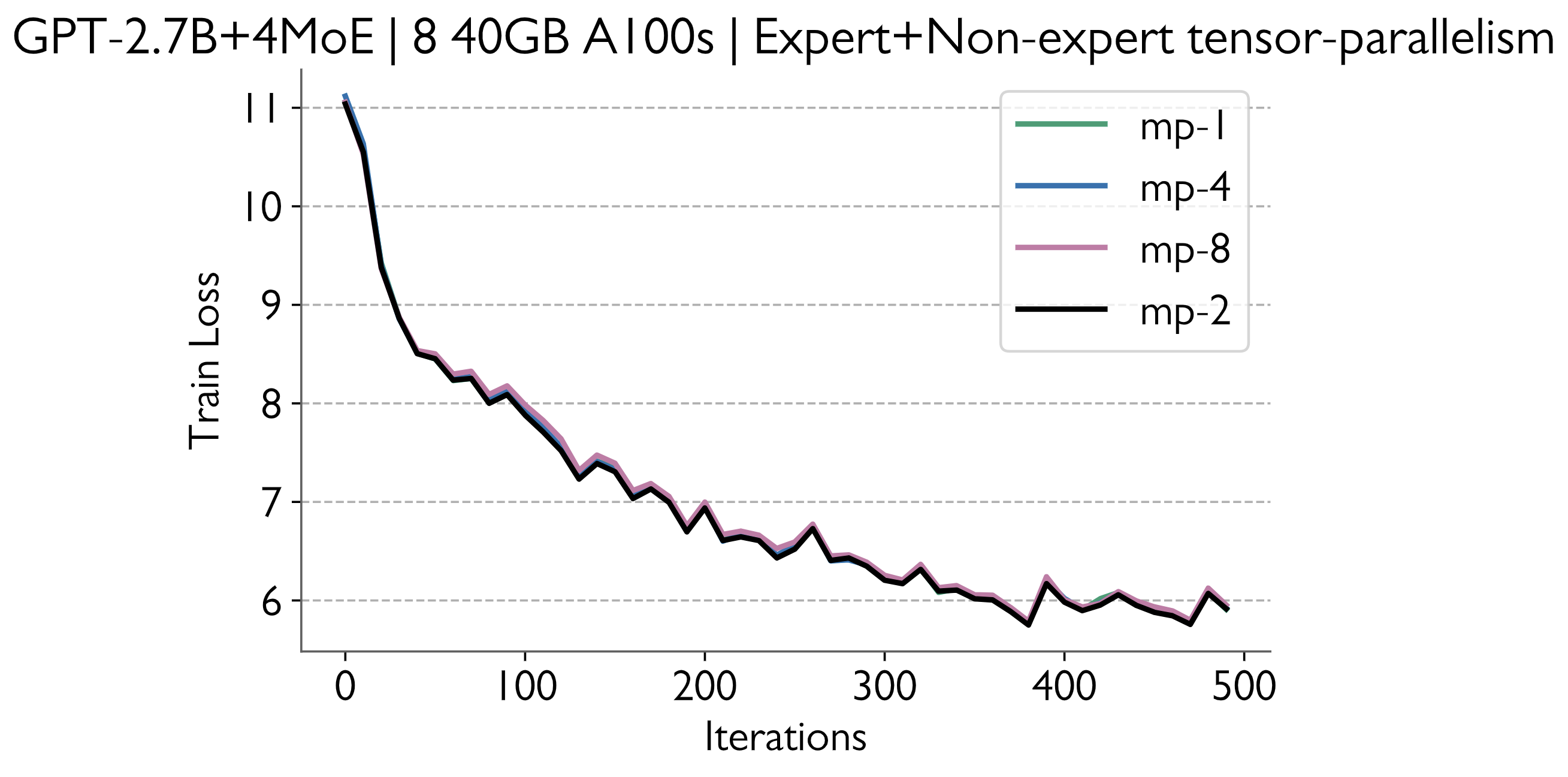
siddharth9820
commented
Jul 20, 2022
conglongli
approved these changes
Jul 26, 2022
awan-10
reviewed
Jul 26, 2022
awan-10
approved these changes
Jul 26, 2022
hyoo
pushed a commit
to hyoo/Megatron-DeepSpeed
that referenced
this pull request
Apr 21, 2023
saforem2
added a commit
to saforem2/Megatron-DeepSpeed
that referenced
this pull request
Nov 15, 2024
[merge]: into `microsoft-main` $\leftarrow$ from `hzheng-data-fix`
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Note: This is in conjunction with this PR on the deepspeed repo.
This PR adds tensor parallelism for non-experts. This combined with ZeRO-2 allows us to scale to roughly 2x larger base models than ZeRO-2. When tensor parallelism is enabled only for non-experts, there are duplicate tokens at each gate. It is important to drop the duplicates before they reach the experts, otherwise we run into convergence issues. In
megatron/mpu/mappings.py, we provide new autograd functions that drop these tokens and gather them, namely_DropTokensand_AllGatherFromModelParallelRegion.In the current implementation, we drop tokens right before the AlltoAll and gather them right after the AlltoAll. These calls are done in the Deepspeed codebase.
Update: This PR now supports tensor parallelism for experts as well. This can be enabled by passing the
--enable-expert-tensor-parallelismargument.