![]()


🚀 Some experiment with NeMo, ASR use QuartzNet model is a smaller version of Jaser model.
The pretrained model on this repo was trained with ~100 hours Vietnamese speech dataset, was collected from youtube, radio, call center(8k), text to speech data and some public dataset (vlsp, vivos, fpt). It is very small model (13M parameters) make it inference so fast ⚡
🌱 Update: The new version available on branch v2.0 is built from scratch with PyTorch
🌱 For Text to Speech, visit VietTTS repo
- Update & install linux libs:
apt-get update && apt-get install -y libsndfile1 ffmpeg- Install python>=3.8
- Python libs:
pip install -r requirements.txt- Install torch 1.8.1:
# cpu only, you can install CUDA version if you have NVidia GPU
pip install torch==1.8.1+cpu torchvision==0.9.1+cpu torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html- Install kemlm for LM decoding (only support Linux)
pip install https://github.com/kpu/kenlm/archive/master.zippython infer.py audio_samples # will transcribe audio file in folder: audio_samples- Run app:
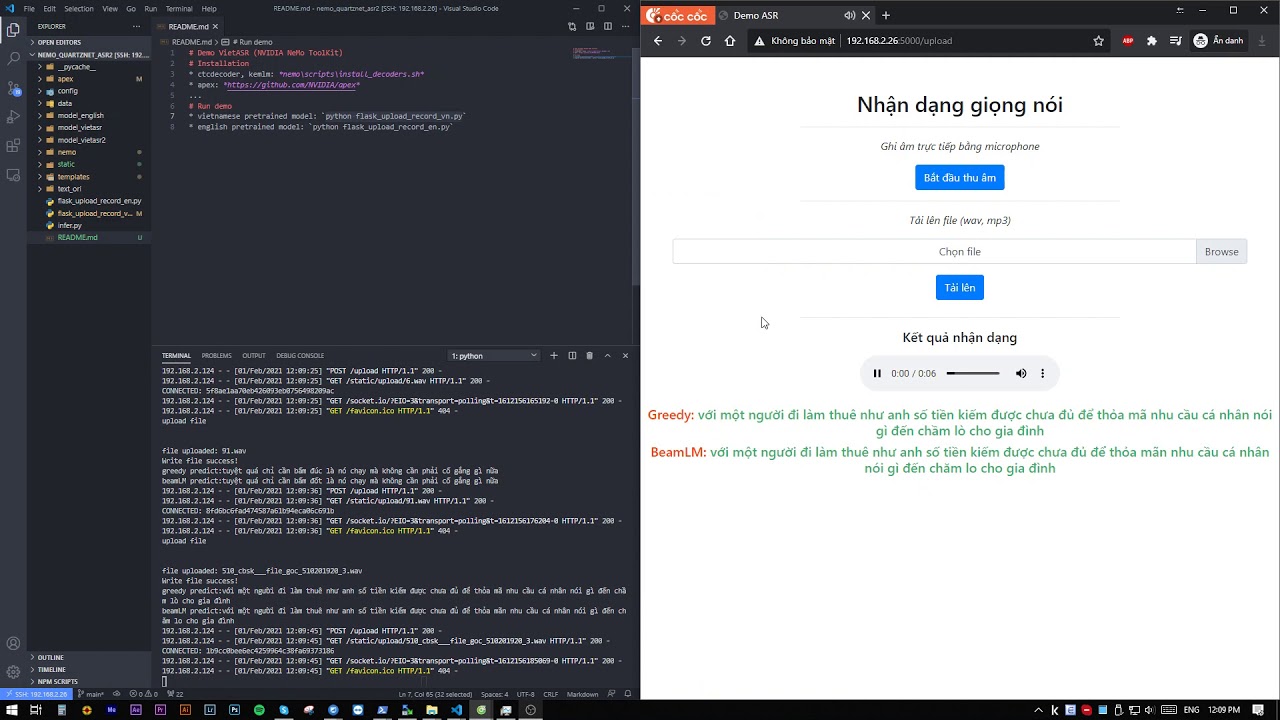
python app.py # app will run on address: https://localhost:5000
- Video demo on Youtube:
- Conformer Model
- Data augumentation: speed, noise, pitch shift, time shift,...
- FastAPI
- Add Dockerfile
@article{kuchaiev2019nemo,
title={Nemo: a toolkit for building ai applications using neural modules},
author={Kuchaiev, Oleksii and Li, Jason and Nguyen, Huyen and Hrinchuk, Oleksii and Leary, Ryan and Ginsburg, Boris and Kriman, Samuel and Beliaev, Stanislav and Lavrukhin, Vitaly and Cook, Jack and others},
journal={arXiv preprint arXiv:1909.09577},
year={2019}
}