Experiment scripts are included directly in the root directory:
- aux_0.99_0.1.py
- aux_0.99_1.0.py
- aux_0.99_10.0.py
- aux_0.99_100.0.py
- aux_0.99_1000.0.py
- aux_none.py
Note that while the original code used RMSProp I found that I would get nan values in the optimizer
during training. I never managed to debug the source of this problem, but found that switching to Adam
optimizer worked.
Bash files were created for launching these on skynet.
To run the bash files first source skynet.sh
cd bash
source skynet.sh
activate_venv
To launch one of the training scripts (here shown for 3 seeds):
sbatch --array=0-2 aux_none.sh
-
deep_rl/network/network_heads.py
Added TDAuxNet which adds only the heads for the auxiliary prediction tasks.
-
deep_rl/agent/TDAux_agent.py
This is actual agent used for training.
If you have any question or want to report a bug, please open an issue instead of emailing me directly.
Modularized implementation of popular deep RL algorithms by PyTorch. Easy switch between toy tasks and challenging games.
Implemented algorithms:
- (Double/Dueling) Deep Q-Learning (DQN)
- Categorical DQN (C51, Distributional DQN with KL Distance)
- Quantile Regression DQN
- (Continuous/Discrete) Synchronous Advantage Actor Critic (A2C)
- Synchronous N-Step Q-Learning
- Deep Deterministic Policy Gradient (DDPG, low-dim-state)
- (Continuous/Discrete) Synchronous Proximal Policy Optimization (PPO, pixel & low-dim-state)
- The Option-Critic Architecture (OC)
Asynchronous algorithms (e.g., A3C) can be found in v0.1. Action Conditional Video Prediction can be found in v0.4.
- MacOS 10.12 or Ubuntu 16.04
- PyTorch v1.1.0
- Python 3.6, 3.5
- OpenAI Baselines (commit
8e56dd) - Core dependencies:
pip install -e .
- PyTorch v0.4.0 should also work in principle, at least for commit
80939f. - There is a super fast DQN implementation with an async actor for data generation and an async replay buffer to transfer data to GPU. Enable this implementation by setting
config.async_actor = Trueand usingAsyncReplay. However, with atari games this fast implementation may not work in macOS. Use Ubuntu or Docker instead. - Although there is a
setup.py, which means you can install the repo as a library, this repo is never designed to be a high-level library like Keras. Use it as your codebase instead. - Code for my papers can be found in corresponding branches, which may be good examples for extending this codebase.
- TensorFlow is used only for logging. Open AI baselines is used very slightly. If you carefully read the code, you should be able to remove/replace them.
examples.py contains examples for all the implemented algorithms
Dockerfile contains the environment for generating the curves below.
Please use this bibtex if you want to cite this repo
@misc{deeprl,
author = {Shangtong, Zhang},
title = {Modularized Implementation of Deep RL Algorithms in PyTorch},
year = {2018},
publisher = {GitHub},
journal = {GitHub Repository},
howpublished = {\url{https://github.com/ShangtongZhang/DeepRL}},
}
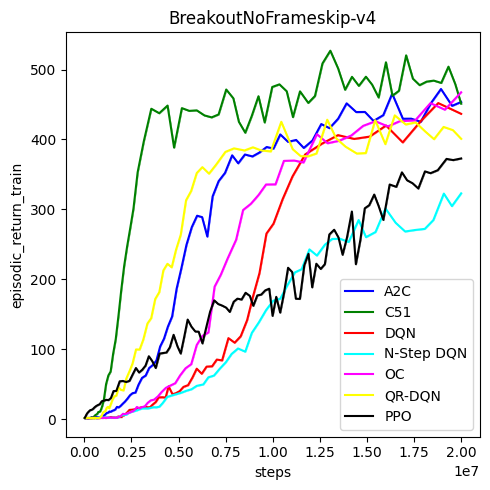
- This is my synchronous option-critic implementation, not the original one.
- The curves are not directly comparable, as many hyper-parameters are different.
-
DDPG evaluation performance.

-
PPO online performance.

- Human Level Control through Deep Reinforcement Learning
- Asynchronous Methods for Deep Reinforcement Learning
- Deep Reinforcement Learning with Double Q-learning
- Dueling Network Architectures for Deep Reinforcement Learning
- Playing Atari with Deep Reinforcement Learning
- HOGWILD!: A Lock-Free Approach to Parallelizing Stochastic Gradient Descent
- Deterministic Policy Gradient Algorithms
- Continuous control with deep reinforcement learning
- High-Dimensional Continuous Control Using Generalized Advantage Estimation
- Hybrid Reward Architecture for Reinforcement Learning
- Trust Region Policy Optimization
- Proximal Policy Optimization Algorithms
- Emergence of Locomotion Behaviours in Rich Environments
- Action-Conditional Video Prediction using Deep Networks in Atari Games
- A Distributional Perspective on Reinforcement Learning
- Distributional Reinforcement Learning with Quantile Regression
- The Option-Critic Architecture
- Some hyper-parameters are from DeepMind Control Suite, OpenAI Baselines and Ilya Kostrikov