If you have any question or want to report a bug, please open an issue instead of emailing me directly.
Modularized implementation of popular deep RL algorithms in PyTorch.
Easy switch between toy tasks and challenging games.
Implemented algorithms:
- (Double/Dueling/Prioritized) Deep Q-Learning (DQN)
- Categorical DQN (C51)
- Quantile Regression DQN (QR-DQN)
- (Continuous/Discrete) Synchronous Advantage Actor Critic (A2C)
- Synchronous N-Step Q-Learning (N-Step DQN)
- Deep Deterministic Policy Gradient (DDPG)
- Proximal Policy Optimization (PPO)
- The Option-Critic Architecture (OC)
- Twined Delayed DDPG (TD3)
- Off-PAC-KL/TruncatedETD/DifferentialGQ/MVPI/ReverseRL/COF-PAC/GradientDICE/Bi-Res-DDPG/DAC/Geoff-PAC/QUOTA/ACE
The DQN agent, as well as C51 and QR-DQN, has an asynchronous actor for data generation and an asynchronous replay buffer for transferring data to GPU. Using 1 RTX 2080 Ti and 3 threads, the DQN agent runs for 10M steps (40M frames, 2.5M gradient updates) for Breakout within 6 hours.
- PyTorch v1.5.1
- See
Dockerfileandrequirements.txtfor more details
examples.py contains examples for all the implemented algorithms.
Dockerfile contains the environment for generating the curves below.
Please use this bibtex if you want to cite this repo
@misc{deeprl,
author = {Zhang, Shangtong},
title = {Modularized Implementation of Deep RL Algorithms in PyTorch},
year = {2018},
publisher = {GitHub},
journal = {GitHub Repository},
howpublished = {\url{https://github.com/ShangtongZhang/DeepRL}},
}
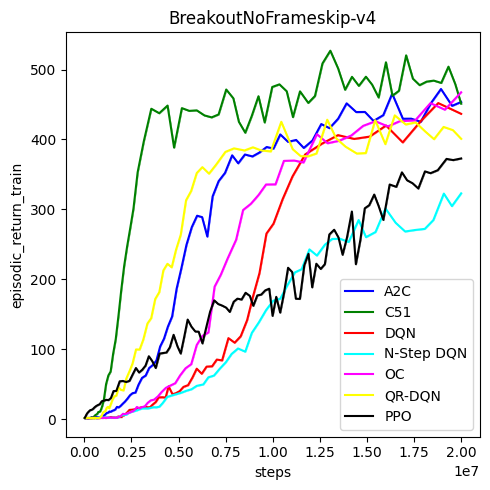
-
DDPG/TD3 evaluation performance.
 (5 runs, mean + standard error)
(5 runs, mean + standard error) -
PPO online performance.
 (5 runs, mean + standard error, smoothed by a window of size 10)
(5 runs, mean + standard error, smoothed by a window of size 10)
- Human Level Control through Deep Reinforcement Learning
- Asynchronous Methods for Deep Reinforcement Learning
- Deep Reinforcement Learning with Double Q-learning
- Dueling Network Architectures for Deep Reinforcement Learning
- Playing Atari with Deep Reinforcement Learning
- HOGWILD!: A Lock-Free Approach to Parallelizing Stochastic Gradient Descent
- Deterministic Policy Gradient Algorithms
- Continuous control with deep reinforcement learning
- High-Dimensional Continuous Control Using Generalized Advantage Estimation
- Hybrid Reward Architecture for Reinforcement Learning
- Trust Region Policy Optimization
- Proximal Policy Optimization Algorithms
- Emergence of Locomotion Behaviours in Rich Environments
- Action-Conditional Video Prediction using Deep Networks in Atari Games
- A Distributional Perspective on Reinforcement Learning
- Distributional Reinforcement Learning with Quantile Regression
- The Option-Critic Architecture
- Addressing Function Approximation Error in Actor-Critic Methods
- Some hyper-parameters are from DeepMind Control Suite, OpenAI Baselines and Ilya Kostrikov
They are located in other branches of this repo and seem to be good examples for using this codebase.
- Global Optimality and Finite Sample Analysis of Softmax Off-Policy Actor Critic under State Distribution Mismatch [Off-PAC-KL]
- Truncated Emphatic Temporal Difference Methods for Prediction and Control [TruncatedETD]
- A Deeper Look at Discounting Mismatch in Actor-Critic Algorithms [Discounting]
- Breaking the Deadly Triad with a Target Network [TargetNetwork]
- Average-Reward Off-Policy Policy Evaluation with Function Approximation [DifferentialGQ]
- Mean-Variance Policy Iteration for Risk-Averse Reinforcement Learning [MVPI]
- Learning Retrospective Knowledge with Reverse Reinforcement Learning [ReverseRL]
- Provably Convergent Two-Timescale Off-Policy Actor-Critic with Function Approximation [COF-PAC, TD3-random]
- GradientDICE: Rethinking Generalized Offline Estimation of Stationary Values [GradientDICE]
- Deep Residual Reinforcement Learning [Bi-Res-DDPG]
- Generalized Off-Policy Actor-Critic [Geoff-PAC, TD3-random]
- DAC: The Double Actor-Critic Architecture for Learning Options [DAC]
- QUOTA: The Quantile Option Architecture for Reinforcement Learning [QUOTA-discrete, QUOTA-continuous]
- ACE: An Actor Ensemble Algorithm for Continuous Control with Tree Search [ACE]