CQL Implementation Strategies
Clinical Quality Language (CQL) is an HL7 International specification designed to support specification and sharing of clinical logic. CQL is:
- A query language, in that it is designed to support expressions for retrieval of and calculation with clinical data
- A functional language, in that it intentionally only supports calculation, it does not support update of any kind
- A domain specific language, in that it has several constructs designed to facilitate the expression of logic in the clinical domain
These characteristics help ensure that the language can meet its primary design goals of enabling the precise specification, sharing, and consistent evaluation of clinical logic. They also help ensure that implementations can approach the evaluation of CQL in a variety of different ways, as appropriate for specific contexts. For example, a decision support context will typically evaluate CQL for a particular patient and as part of a service integrated at the point of care. Whereas a quality measurement context will typically evaluate CQL for some population of patients, operating on a repository, or even in a federated context. The following topics describe the CQL approach to sharing logic that accesses clinical data, as well as strategies for implementation that support these various evaluation contexts.
CQL approaches knowledge sharing by separating the concerns of logic, model, and terminology:
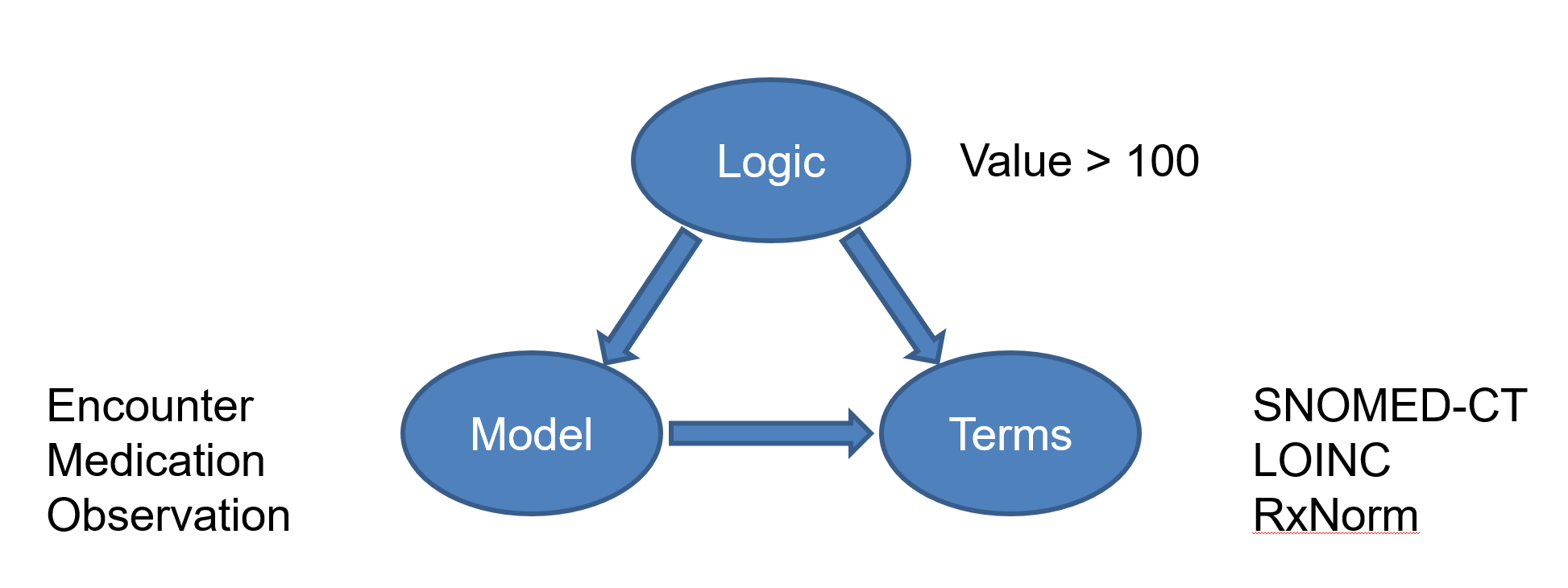
The approach allows for the fact that there are many standards for data models and terminologies, and that they each evolve at different rates. CQL uses Model Information to describe the characteristics of any particular model, and defines general purpose terminology structures to allow any terminology to be referenced without defining terminology contents.
When evaluating CQL, these components must be represented as part of the evaluation, for both data and terminology access.
All data access in CQL is performed using a retrieve:
define "All Smoking Status Observations":
[Observation: code in "Tobacco Smoking Status"]In this example, the retrieve is in square brackets ([ ]) and is asking for all Observation resources with a code in the "Tobacco Smoking Status" value set. The retrieve expression specifies the type of data being retrieved, and optionally a terminology, typically a value set.
A key aspect of data access in CQL is that it is conceptual as opposed to physical, meaning that CQL describes what data needs to be retrieved from a clinical system, not how that data is to be retrieved. This is critical to ensuring that the logic is portable to different environments, allowing implementations to provide data in whatever way is most appropriate:
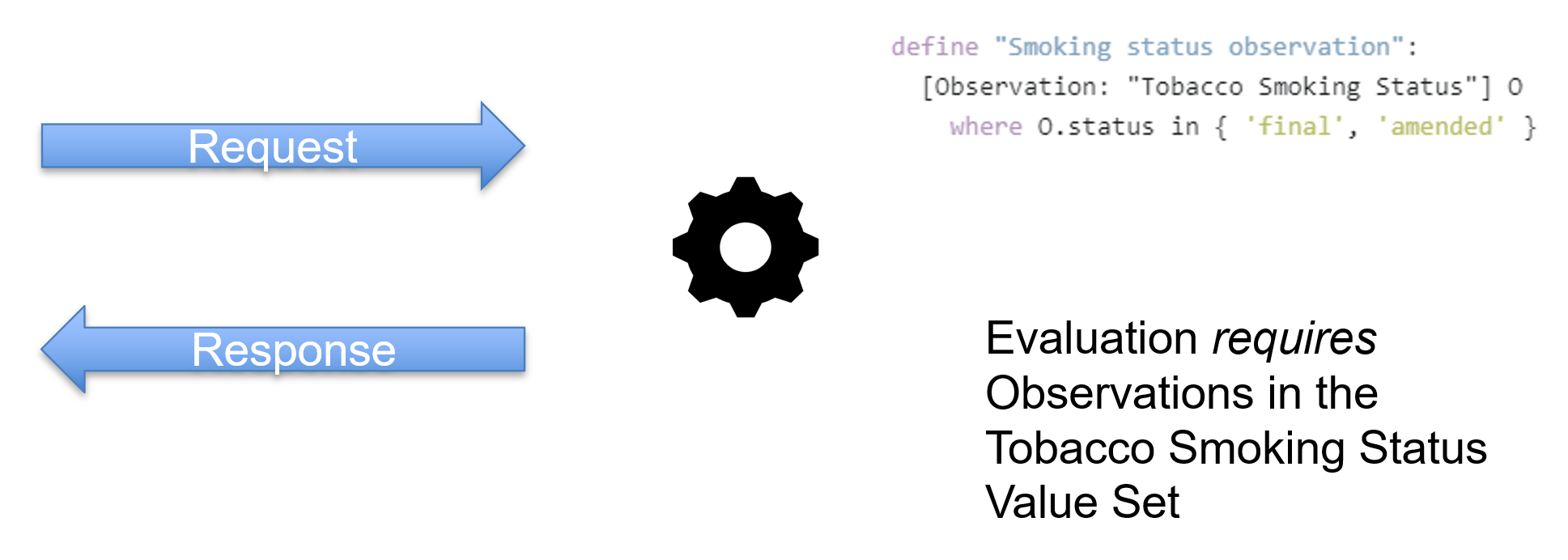
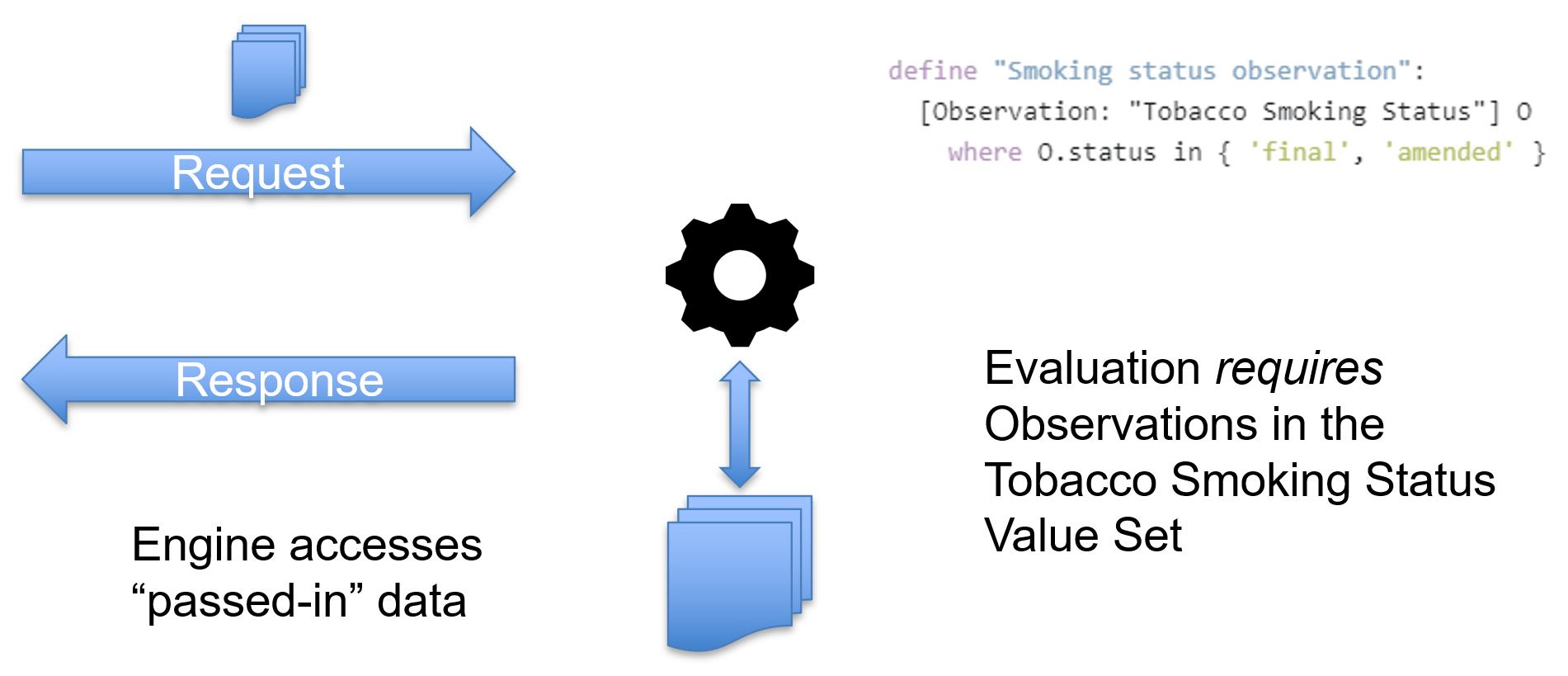
In CQL, given this query, we say that the evaluation requires Observations in the Smoking Status value set.
Because all data access in CQL is accomplished through retrieves, the data requirements for any set of CQL expressions can be determined by looking only at the retrieves. In addition, because retrieves only allow filtering in specific ways, these data requirements can be combined to determine the minimum set of data required to successfully evaluate the CQL.
There are three broad categories of implementation approaches for CQL:
- Manual - i.e. use the CQL as a "blueprint"
- Automatic - Translate the CQL to another language for execution
- Native - Run the CQL natively
Manual implementation involves using the CQL as a specification, or blueprint, for the clinical logic. Developers manually translate the CQL into whatever data language or programming environment is most effective/appropriate for their use on a case-by-case basis. For example, a CQL-based quality measure specification may be manually translated to an SQL query for execution.
Automatic implementation involves translating the CQL into another language for execution. For example, there is a .NET-based translator for CQL-to-SQL that will take arbitrary CQL and output the equivalent SQL query. CQL was intentionally designed to be very similar to SQL to facilitate this type of translation.
Native implementation involves running the CQL directly in a CQL engine. This is the approach most commonly taken in the open source space currently, with mature, open source engines available for JavaScript, Java, and .NET environments.
For a native implementation, because the CQL may be evaluated in a variety of environments, there are multiple possible approaches to accessing the data:
- In-process
- Service-based
- Pre-Fetch
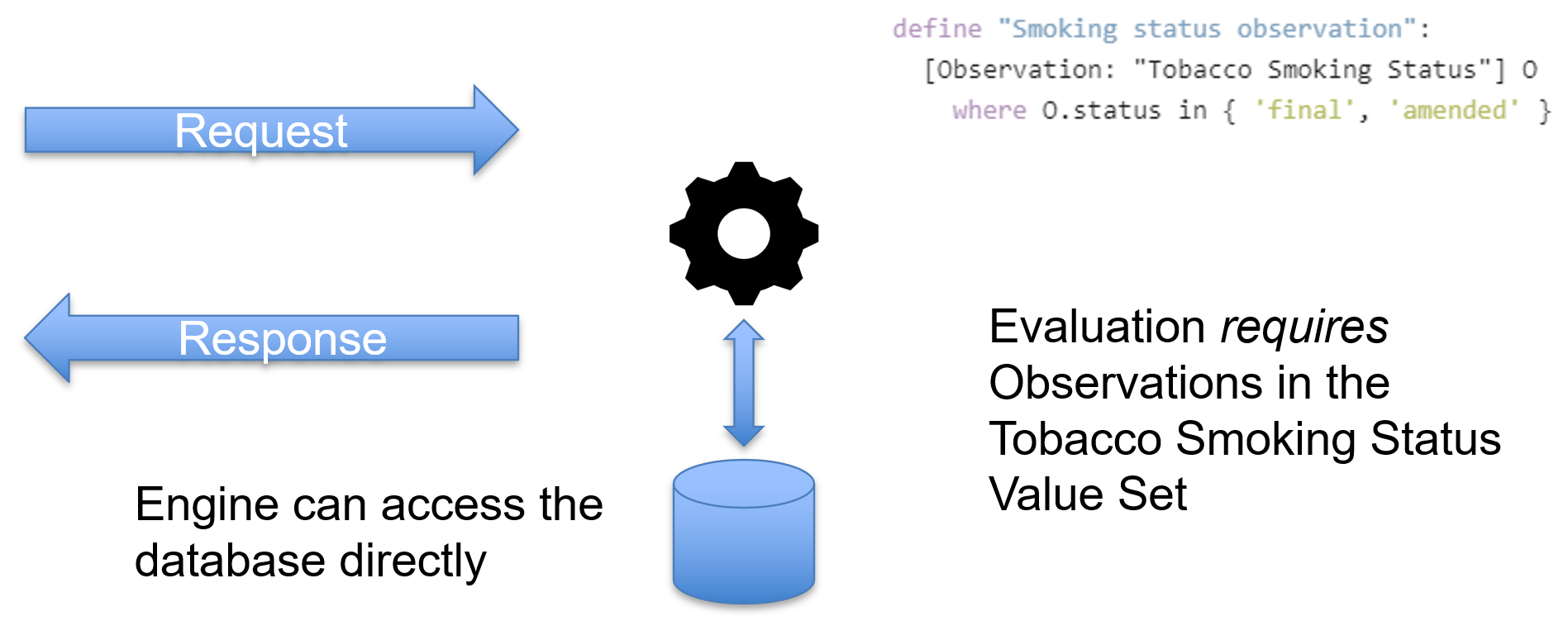
For in-process evaluation, the engine is running in the same process or application as the data being accessed, and so can access the data directly:
For service-based evaluation, the engine is running in a service, or otherwise outside the data store, and so the engine must access the data via a service-call:
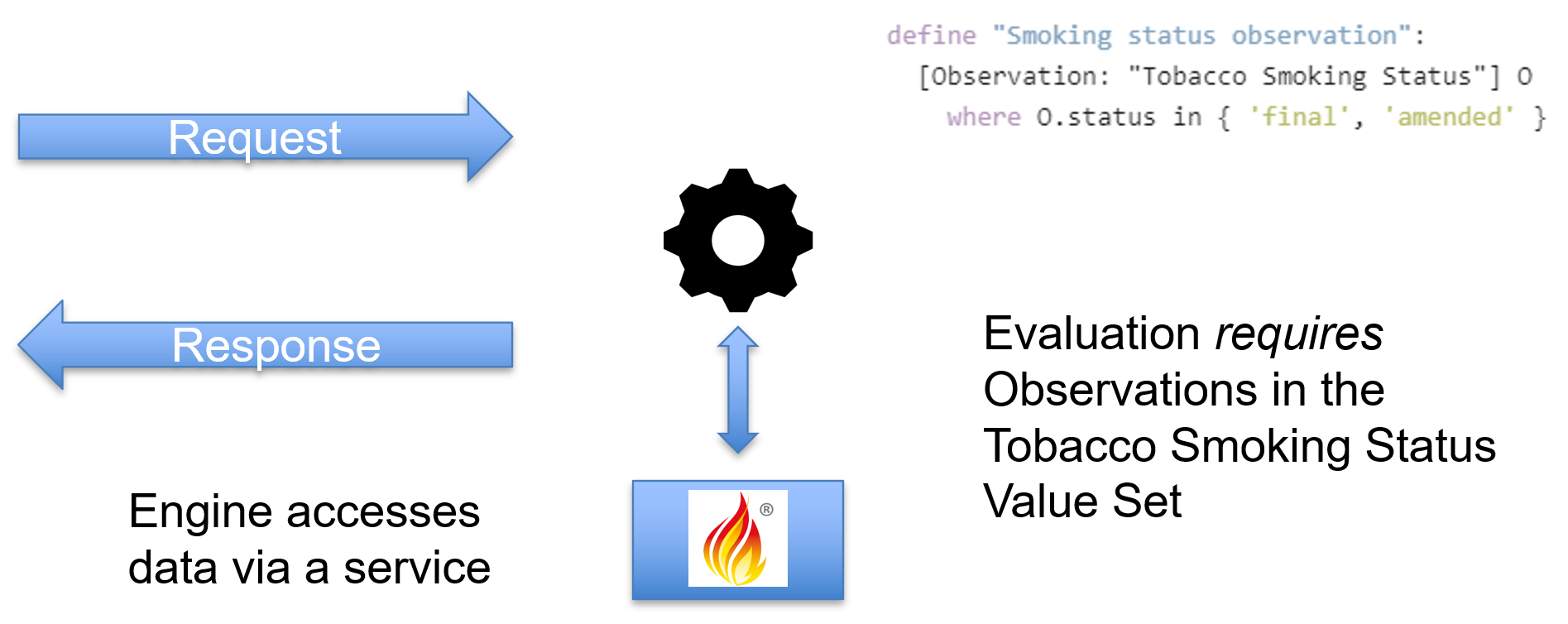
For pre-fetch evaluation, the required data is provided to the engine as part of the request:
As with any query language, the performance of CQL depends a great deal on the implementation environment, including many factors such as co-location with the data, availability of indexes, organization of the data structures involved, and responsiveness and latency of the data access layer.
For almost all CQL use cases, and all the known open source engines, raw engine performance is not a significant issue. For example, the raw Java engine throughput is about 5,000 operations per second on commodity hardware, and there's a benchmark as part of the test suite that validates that performance.
Rather, performance issues tend to arise in the data access layer when retrieving the required data, either as part of a pre-fetch based on the data requirements, or when accessing the data from a database or FHIR server.
This leads to several potential performance and optimization strategies for CQL:
Although CQL retrieves only allow terminology-valued filters, the underlying ELM implementation of the retrieve supports date-valued and string-valued filters as well. This feature of ELM can be used to provide query planning features, where the query to be run is analyzed to determine whether restrictions in queries outside the retrieve can be pushed down into the retrieve so they can be evaluated in the data access layer. This allows filtering to be done on the service providing the data, resulting in potentially significant performance improvements for certain types of queries.
The CQL-to-ELM translator, using the date-range-optimization option, will detect date-valued filters and push them into the retrieves. In addition, the translator tooling has a DataRequirementsProcessor that performs more sophisticated query analysis and planning when the analyzeDataRequirements option is used.
This data requirements processor currently detects and optimizes relative comparisons in where clauses (e.g. status = 'active' or quantity > 10 'mg') as well as include queries (e.g. 'medication.id = medication.reference.getId()), and more work is underway to perform additional optimizations and query planning.
CQL supports a context keyword that allows clinical logic to be written from the perspective of a particular subject. This is most often a Patient content, allowing the logic to be expressed from the perspective of a single patient. This simplifies authoring, and allows for an ideal optimization strategy, parallelization. When evaluating a quality measure, for example, processing can be parallelized per patient, and then the results can be aggregated as a single step at the end, allowing for effectively horizontal scaling of population-level calculations.
As a principle, CQL should not be written with performance considerations in mind. CQL authors should be focused on providing correct and complete representations of the conceptual logic involved (i.e. the what not the how). However, given the state of current tooling, there are cases where understanding that the translator can detect and optimize certain types of queries can be an effective way to improve performance of CQL.
In particular, choosing terminology-valued filters that align with known search parameters is a best-practice, and is one of the focuses of the US Common Elements content implementation guide, to provide a set of common expressions that are known to work with the search parameters defined in the US Core implementation guide. This ensures that CQL evaluation will be able to choose FHIR queries that align with the way US Core has been implemented by vendor systems.
In addition, writing queries in such a way that the translator can easily recognize a date-range optimization can be helpful as well. For example:
define "Acitve Aspirin Orders in the Past Year":
[MedicationRequest: medication in "Aspirin"] MR
where MR.intent = 'order'
and MR.status = 'active'
and MR.doNotPerform is not true
and MR.authoredOn 1 year on or before Today()In this case, the authoredOn condition could be optimized as a date-range filter, but the CQL-to-ELM translator processing is not yet sophisticated enough to extract the date filter from the other conditions in the where clause, so re-writing it as follows:
define "All Aspirin Medication Requests in the Past Year":
[MedicationRequest: medication in "Aspirin"] MR
where MR.authoredOn 1 year on or before Today()
define "Active Aspirin Orders in the Past Year":
"All Aspirin Medication Requests in the Past Year" MR
where MR.intent = 'order'
and MR.status = 'active'
and MR.doNotPerform is not trueAs of the time of this writing, the following are some known benchmarks for CQL performance in both open source and commercial offerings:
The raw Java-based CQL engine throughput is around 5,000 operations per second on commodity hardware, and the regression suite for the engine includes a benchmark test that validates this performance.
The Measure Calculation Tool (MCT) is an open-source implementation of measure calculation that makes use of the Java-based CQFramework CQL evaluation stack. On commodity hardware, the MCT can process about a patient-measure per second. For details see the MCT Implementation Guide - Performance
The open source Java measure engine, with data and terminology pre-cached, currently runs at about 1,000 operations per second for a breast-cancer screening measure, and there is a benchmark test that validates this performance.
A Smile CDR cluster setup with 10 nodes can process
- 1 million patient measures in < 1 hour (~300 patient-measures/second)
- 50,000 patients for 6 measures in < 5 minutes (~1000 patient-measures/second)
Note that the faster performance for the 6 measures benchmark is because much of the patient data is shared across measures, so the performance improves for multiple measures due to data caching. This illustrates one of the core aspects of CQL (or indeed any data processing application), data architecture and transfer times are the most important aspect of getting to enterprise scale.
By pipelining execution, using the parallelization approach, but the same core CQL and Clinical Reasoning engine components can be scaled even further using Spark clustering. For the Smile Digital Health dQM Platform configured as a 400 core Spark cluster, the benchmark is around a billion patient-measures an hour.
One of the primary design goals of Clinical Quality Language is to support the precise and unambiguous specification and sharing of clinical logic. To support implementation of this logic, several open source, as well as commercial engines exist to evaluate CQL in various settings throughout the healthcare space, from running CQL as part of the delivery of guideline-directed care in an Android application, through providing decision support as a service as part of a CDS Hooks integration, all the way up to enterprise-scale quality measure evaluation, the performance of CQL in any given environment is heavily dependent on how the data is accessed. The performance and optimization strategies outlined here are being used to successfully and performantly evaluate CQL in all these settings.