![]()
![]()
NOTE
Active development on stable-fast has been paused. I am currently working on a new torch._dynamo based project targeting new models such as stable-cascade, SD3 and Sora like mmodels.
It would be faster and more flexible, as well as supporting more hardware backends rather than CUDA.
Contact is welcomed.
stable-fast achieves SOTA inference performance on ALL kinds of diffuser models, even with the latest StableVideoDiffusionPipeline.
And unlike TensorRT or AITemplate, which takes dozens of minutes to compile a model, stable-fast only takes a few seconds to compile a model.
stable-fast also supports dynamic shape, LoRA and ControlNet out of the box.
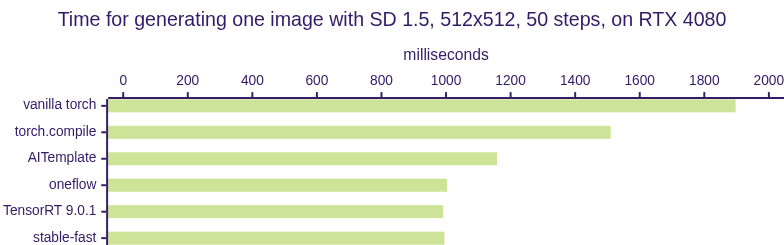
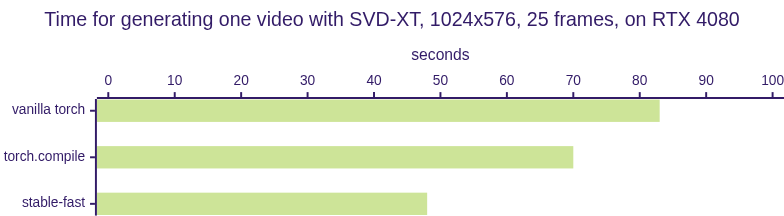
| Model | torch | torch.compile | AIT | oneflow | TensorRT | stable-fast |
|---|---|---|---|---|---|---|
| SD 1.5 (ms) | 1897 | 1510 | 1158 | 1003 | 991 | 995 |
| SVD-XT (s) | 83 | 70 | 47 |
NOTE: During benchmarking, TensorRT is tested with static batch size and CUDA Graph enabled while stable-fast is running with dynamic shape.
stable-fast is an ultra lightweight inference optimization framework for HuggingFace Diffusers on NVIDIA GPUs.
stable-fast provides super fast inference optimization by utilizing some key techniques and features:
- CUDNN Convolution Fusion:
stable-fastimplements a series of fully-functional and fully-compatible CUDNN convolution fusion operators for all kinds of combinations ofConv + Bias + Add + Actcomputation patterns. - Low Precision & Fused GEMM:
stable-fastimplements a series of fused GEMM operators that compute withfp16precision, which is fast than PyTorch's defaults (read & write withfp16while compute withfp32). - Fused Linear GEGLU:
stable-fastis able to fuseGEGLU(x, W, V, b, c) = GELU(xW + b) ⊗ (xV + c)into one CUDA kernel. - NHWC & Fused GroupNorm:
stable-fastimplements a highly optimized fused NHWCGroupNorm + Siluoperator with OpenAI'sTriton, which eliminates the need of memory format permutation operators. - Fully Traced Model:
stable-fastimproves thetorch.jit.traceinterface to make it more proper for tracing complex models. Nearly every part ofStableDiffusionPipeline/StableVideoDiffusionPipelinecan be traced and converted to TorchScript. It is more stable thantorch.compileand has a significantly lower CPU overhead thantorch.compileand supports ControlNet and LoRA. - CUDA Graph:
stable-fastcan capture theUNet,VAEandTextEncoderinto CUDA Graph format, which can reduce the CPU overhead when the batch size is small. This implemention also supports dynamic shape. - Fused Multihead Attention:
stable-fastjust uses xformers and makes it compatible with TorchScript.
My next goal is to keep stable-fast as one of the fastest inference optimization frameworks for diffusers and also
provide both speedup and VRAM reduction for transformers.
In fact, I already use stable-fast to optimize LLMs and achieve a significant speedup.
But I still need to do some work to make it more stable and easy to use and provide a stable user interface.
- Fast:
stable-fastis specialy optimized for HuggingFace Diffusers. It achieves a high performance across many libraries. And it provides a very fast compilation speed within only a few seconds. It is significantly faster thantorch.compile,TensorRTandAITemplatein compilation time. - Minimal:
stable-fastworks as a plugin framework forPyTorch. It utilizes existingPyTorchfunctionality and infrastructures and is compatible with other acceleration techniques, as well as popular fine-tuning techniques and deployment solutions. - Maximum Compatibility:
stable-fastis compatible with all kinds ofHuggingFace DiffusersandPyTorchversions. It is also compatible withControlNetandLoRA. And it even supports the latestStableVideoDiffusionPipelineout of the box!
NOTE: stable-fast is currently only tested on Linux and WSL2 in Windows.
You need to install PyTorch with CUDA support at first (versions from 1.12 to 2.1 are suggested).
I only test stable-fast with torch>=2.1.0, xformers>=0.0.22 and triton>=2.1.0 on CUDA 12.1 and Python 3.10.
Other versions might build and run successfully but that's not guaranteed.
Download the wheel corresponding to your system from the Releases Page and install it with pip3 install <wheel file>.
Currently both Linux and Windows wheels are available.
# Change cu121 to your CUDA version and <wheel file> to the path of the wheel file.
# And make sure the wheel file is compatible with your PyTorch version.
pip3 install --index-url https://download.pytorch.org/whl/cu121 \
'torch>=2.1.0' 'xformers>=0.0.22' 'triton>=2.1.0' 'diffusers>=0.19.3' \
'<wheel file>'# Make sure you have CUDNN/CUBLAS installed.
# https://developer.nvidia.com/cudnn
# https://developer.nvidia.com/cublas
# Install PyTorch with CUDA and other packages at first.
# Windows user: Triton might be not available, you could skip it.
# NOTE: 'wheel' is required or you will meet `No module named 'torch'` error when building.
pip3 install wheel 'torch>=2.1.0' 'xformers>=0.0.22' 'triton>=2.1.0' 'diffusers>=0.19.3'
# (Optional) Makes the build much faster.
pip3 install ninja
# Set TORCH_CUDA_ARCH_LIST if running and building on different GPU types.
# You can also install the latest stable release from PyPI.
# pip3 install -v -U stable-fast
pip3 install -v -U git+https://github.com/chengzeyi/stable-fast.git@main#egg=stable-fast
# (this can take dozens of minutes)NOTE: Any usage outside sfast.compilers is not guaranteed to be backward compatible.
NOTE: To get the best performance, xformers and OpenAI's triton>=2.1.0 need to be installed and enabled.
You might need to build xformers from source to make it compatible with your PyTorch.
stable-fast is able to optimize StableDiffusionPipeline and StableDiffusionPipelineXL directly.
import time
import torch
from diffusers import (StableDiffusionPipeline,
EulerAncestralDiscreteScheduler)
from sfast.compilers.diffusion_pipeline_compiler import (compile,
CompilationConfig)
def load_model():
model = StableDiffusionPipeline.from_pretrained(
'runwayml/stable-diffusion-v1-5',
torch_dtype=torch.float16)
model.scheduler = EulerAncestralDiscreteScheduler.from_config(
model.scheduler.config)
model.safety_checker = None
model.to(torch.device('cuda'))
return model
model = load_model()
config = CompilationConfig.Default()
# xformers and Triton are suggested for achieving best performance.
try:
import xformers
config.enable_xformers = True
except ImportError:
print('xformers not installed, skip')
try:
import triton
config.enable_triton = True
except ImportError:
print('Triton not installed, skip')
# CUDA Graph is suggested for small batch sizes and small resolutions to reduce CPU overhead.
# But it can increase the amount of GPU memory used.
# For StableVideoDiffusionPipeline it is not needed.
config.enable_cuda_graph = True
model = compile(model, config)
kwarg_inputs = dict(
prompt=
'(masterpiece:1,2), best quality, masterpiece, best detailed face, a beautiful girl',
height=512,
width=512,
num_inference_steps=30,
num_images_per_prompt=1,
)
# NOTE: Warm it up.
# The initial calls will trigger compilation and might be very slow.
# After that, it should be very fast.
for _ in range(3):
output_image = model(**kwarg_inputs).images[0]
# Let's see it!
# Note: Progress bar might work incorrectly due to the async nature of CUDA.
begin = time.time()
output_image = model(**kwarg_inputs).images[0]
print(f'Inference time: {time.time() - begin:.3f}s')
# Let's view it in terminal!
from sfast.utils.term_image import print_image
print_image(output_image, max_width=80)Refer to examples/optimize_stable_diffusion_pipeline.py for more details.
You can check this Colab to see how it works on T4 GPU:
stable-fast is able to optimize the newest latent consistency model pipeline and achieve a significant speedup.
Refer to examples/optimize_lcm_pipeline.py for more details about how to optimize normal SD model with LCM LoRA. Refer to examples/optimize_lcm_pipeline.py for more details about how to optimize the standalone LCM model.
stable-fast is able to optimize the newest StableVideoDiffusionPipeline and achieve a 2x speedup
Refer to examples/optimize_stable_video_diffusion_pipeline.py for more details
Switching LoRA dynamically is supported but you need to do some extra work.
It is possible because the compiled graph and CUDA Graph share the same
underlaying data (pointers) with the original UNet model. So all you need to do
is to update the original UNet model's parameters inplace.
The following code assumes you have already load a LoRA and compiled the model, and you want to switch to another LoRA.
If you don't enable CUDA graph and keep preserve_parameters = True, things could be much easier.
The following code might not even be needed.
# load_state_dict with assign=True requires torch >= 2.1.0
def update_state_dict(dst, src):
for key, value in src.items():
# Do inplace copy.
# As the traced forward function shares the same underlaying data (pointers),
# this modification will be reflected in the traced forward function.
dst[key].copy_(value)
# Switch "another" LoRA into UNet
def switch_lora(unet, lora):
# Store the original UNet parameters
state_dict = unet.state_dict()
# Load another LoRA into unet
unet.load_attn_procs(lora)
# Inplace copy current UNet parameters to the original unet parameters
update_state_dict(state_dict, unet.state_dict())
# Load the original UNet parameters back.
# We use assign=True because we still want to hold the references
# of the original UNet parameters
unet.load_state_dict(state_dict, assign=True)
switch_lora(compiled_model.unet, lora_b_path)stable-fast extends PyTorch's quantize_dynamic functionality and provides a dynamically quantized linear operator on CUDA backend.
By enabling it, you could get a slight VRAM reduction for diffusers and significant VRAM reduction for transformers,
and cound get a potential speedup (not always).
For SD XL, it is expected to see VRAM reduction of 2GB with an image size of 1024x1024.
def quantize_unet(m):
from diffusers.utils import USE_PEFT_BACKEND
assert USE_PEFT_BACKEND
m = torch.quantization.quantize_dynamic(m, {torch.nn.Linear},
dtype=torch.qint8,
inplace=True)
return m
model.unet = quantize_unet(model.unet)
if hasattr(model, 'controlnet'):
model.controlnet = quantize_unet(model.controlnet)Refer to examples/optimize_stable_diffusion_pipeline.py for more details.
# TCMalloc is highly suggested to reduce CPU overhead
# https://github.com/google/tcmalloc
LD_PRELOAD=/path/to/libtcmalloc.so python3 ...import packaging.version
import torch
if packaging.version.parse(torch.__version__) >= packaging.version.parse('1.12.0'):
torch.backends.cuda.matmul.allow_tf32 = TruePerformance varies very greatly across different hardware/software/platform/driver configurations.
It is very hard to benchmark accurately. And preparing the environment for benchmarking is also a hard job.
I have tested on some platforms before but the results may still be inaccurate.
Note that when benchmarking, the progress bar showed by tqdm may be inaccurate because of the asynchronous nature of CUDA.
To solve this problem, I use CUDA Event to measure the speed of iterations per second accurately.
stable-fast is expected to work better on newer GPUs and newer CUDA versions.
On older GPUs, the performance increase might be limited.
During benchmarking, the progress bar might work incorrectly because of the asynchronous nature of CUDA.
This is my personal gaming PC😄. It has a more powerful CPU than those from cloud server providers.
| Framework | SD 1.5 | SD XL (1024x1024) | SD 1.5 ControlNet |
|---|---|---|---|
| Vanilla PyTorch (2.1.0) | 29.5 it/s | 4.6 it/s | 19.7 it/s |
| torch.compile (2.1.0, max-autotune) | 40.0 it/s | 6.1 it/s | 21.8 it/s |
| AITemplate | 44.2 it/s | ||
| OneFlow | 53.6 it/s | ||
| AUTO1111 WebUI | 17.2 it/s | 3.6 it/s | |
| AUTO1111 WebUI (with SDPA) | 24.5 it/s | 4.3 it/s | |
| TensorRT (AUTO1111 WebUI) | 40.8 it/s | ||
| TensorRT Official Demo | 52.6 it/s | ||
| stable-fast (with xformers & Triton) | 51.6 it/s | 9.1 it/s | 36.7 it/s |
Thanks for @Consceleratus and @harishp's help, I have tested speed on H100.
| Framework | SD 1.5 | SD XL (1024x1024) | SD 1.5 ControlNet |
|---|---|---|---|
| Vanilla PyTorch (2.1.0) | 54.5 it/s | 14.9 it/s | 35.8 it/s |
| torch.compile (2.1.0, max-autotune) | 66.0 it/s | 18.5 it/s | |
| stable-fast (with xformers & Triton) | 104.6 it/s | 21.6 it/s | 72.6 it/s |
Thanks for @SuperSecureHuman and @jon-chuang's help, benchmarking on A100 is available now.
| Framework | SD 1.5 | SD XL (1024x1024) | SD 1.5 ControlNet |
|---|---|---|---|
| Vanilla PyTorch (2.1.0) | 35.6 it/s | 8.7 it/s | 25.1 it/s |
| torch.compile (2.1.0, max-autotune) | 41.9 it/s | 10.0 it/s | |
| stable-fast (with xformers & Triton) | 61.8 it/s | 11.9 it/s | 41.1 it/s |
| Model | Supported |
|---|---|
| Hugging Face Diffusers (1.5/2.1/XL) | Yes |
| With ControlNet | Yes |
| With LoRA | Yes |
| Latent Consistency Model | Yes |
| SDXL Turbo | Yes |
| Stable Video Diffusion | Yes |
| Functionality | Supported |
|---|---|
| Dynamic Shape | Yes |
| Text to Image | Yes |
| Image to Image | Yes |
| Image Inpainting | Yes |
| UI Framework | Supported | Link |
|---|---|---|
| AUTOMATIC1111 | WIP | |
| SD Next | Yes | SD Next |
| ComfyUI | Yes | ComfyUI_stable_fast |
| Operating System | Supported |
|---|---|
| Linux | Yes |
| Windows | Yes |
| Windows WSL | Yes |
Refer to doc/troubleshooting.md for more details.
And you can join the Discord Channel to ask for help.