CVR转化问题是推荐系统,计算广告领域一个比较核心的问题。如何做好CVR转化对于产品变现是非常重要的。这里对阿里妈妈团队提出的ESSM模型进行梳理,同时对CVR中的一些核心难点进行简单的分析。
CVR问题的算法优化迭代经历了传统CF算法到机器学习算法再到现阶段深度学习算法的发展。其中用到的算法非常的多,最常用的方式是利用用户的历史点击数据作为样本空间集,然后根据用户从click—>buy的样本构造样本空间集中的正负样本。有了正负样本后利用很多经典的分类算法都能给出数据一个较为不错的预测结果。
然而如果我们稍微有一点实际的生产经验就会发现上述做法存在几个非常严重的问题:1.模型训练的样本空间集和实际预测的样本空间集是不一致的,构造模型训练的样本集是click—>buy的数据,而实际生产中预测的是impression—>buy的数据,前者仅仅是后者的一个子集而且数据量小一到两个级别,因此会造成预测的偏差;2.数据稀疏的问题,由于从click->buy的数据很少,我们的数据是100:1左右的比率,因此整个数据的正负样本会非常的不均,这个对模型的拟合造成了非常大的困难。
针对上述存在的问题,阿里妈妈团队结合淘宝真实的业务场景,提出了一个基于multi-task的多任务训练模型,同时优化ctr和ctcvr两个指标,通过参数共享的方式缓解数据稀疏,而联合学习通过约束两个目标来优化样本空间分布不一致的问题。
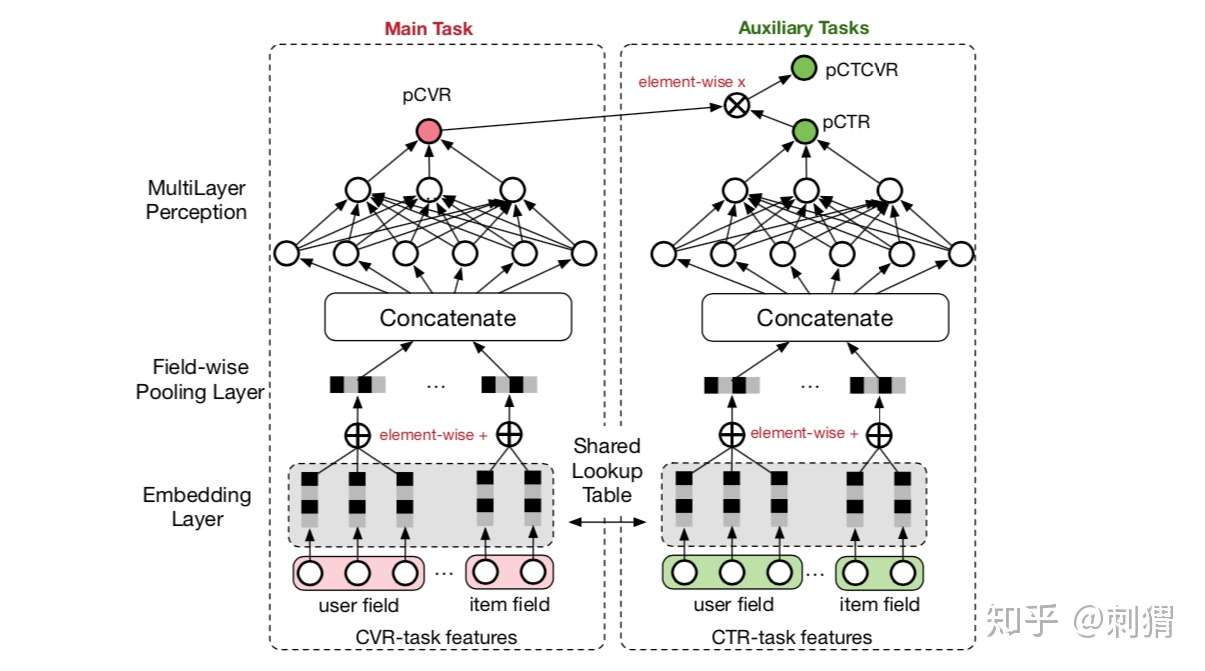
整个模型的结构非常的简单清晰,分为一个main task和一个auxiliary task其中main task依然是传统的cvr转化模型,auxiliary task通过shared lookup table与main task共享embedding层这样可以一定程度上缓解数据稀疏导致的embeding学习表达较弱的问题,auxiliary task是一个ctr预估模型,其主要用到了impression数据,通过cvr和ctr的乘法运算学习ctcvr,这种同时约束cvr和ctr的方式可以为main task模型带来一些impression相关的数据信息,解决了样本分布不一致的问题。整个模型的目标函数是:
这里有几个需要注意的点:
1.实现这个模型的时候怎么训练,损失函数怎么写,数据怎么构造?
这里我们可以看到主任务是CVR任务,副任务是CTR任务,实际生产的数据是用户曝光数据,点击数据和转化数据,那么曝光和点击数据可以构造副任务的CTR模型,曝光和转化数据(转化必点击)构造的是CTCVR任务,模型的输出有3个,CTR模型输出预测的pCTR,CVR模型输出预测的pCVR,联合模型输出预测的pCTCVR=pCTR*pCVR,由于CVR模型的输出标签不好直接构造,因此这里损失函数loss = ctr的损失函数 + ctcvr的损失函数,因为pctcvr=pctr*pcvr所以loss中也充分利用到CVR模型的参数。
实验部分这里不细讲,有兴趣可以直接看论文实验部分
《Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate》