这个是利用pytorch中的torchvision实现的一个maskrcnn的目标检测和实例分割的小例子
@[toc]
最近做目标检测,然后记录一下 Faster RCNN、Mask RCNN来做目标检测踩得那些坑。
首先,本文并不是利用Pytorch从头去实现Faster RCNN、Mask RCNN这两个结构的文章。如果有意向去从头实现并了解每一步细节可以看看下面这些视频和博客:
来自B站的两位大佬讲解
上面都是利用pytorch从原理到具体实现的步骤。
不过本文主要还是利用Pytorch中的Torchvision.model中的Faster RCNN、Mask RCNN来实现迁移学习。
关于如何利用迁移学习来训练自己的数据集,这里也给出两个超赞的教程:
看完以上三个教程,基本上利用Pytorch中的Torchvision.model中的Faster RCNN、Mask RCNN来实现迁移学习也基本上没问题了。
这里讲一下如何制作自己的数据集训练这两个网络:
首先你得准备图片数据,这个数据可能是别人给你提供的,也可能是你自己下载的,反正你得先准备好你的图片并放在一个指定的文件夹里。 这里推荐一个批量下载网上图片的工具:IMAGE CYBORG
现在一般用于目标检测、实力分割的数据集制作的有两个工具:labelme和labeling。至于这两个有什么区别和联系呢,有如下解释:labelimg用于做目标检测,占内存小,labelme用于图像语义/实例分割,占内存大。
| Labelme | LabelImg | |
|---|---|---|
| 打开文件 | Open | Open |
| 打开文件夹 | OpenDir | OpenDir |
| 前后帧变换 | Next & Prev Image | Next & Prev Image |
| 标注方式 | 聚点分割&矩形框&圆&线 | 矩形框 |
| 保存方式 | JSON | VOC&YOLO格式 |
| 标注大小 | 内存占比大 | 忽略不计 |
| 优点 | 标注类型多(分割和检测)标注文件另存了原始图像 | 存储简单,RCNN、SSD、YOLO指定标注格式,对象,明确,模式灵活 |
| 适应场景 | 大部分2D分割任务,少数据量2D检测任务 | 单目标的2D检测任务,适用于VOC格式的数据 |
windows安装
conda install pyqt #conda现在已经自带pyqt5了,所以会提示你已安装
pip install labelme使用
在终端中执行以下命令:labelme就可以使用了,具体如何使用百度吧。
-
将
new_json_to_dataset.py,draw.py两个文件复制到下面labelme的路径下C:\Users\lee\Anaconda3\Lib\site-packages\labelme\cli -
修改new_json_to_dataset.py中的你自己的类别名(一定得修改,不然会报错):
NAME_LABEL_MAP = {
'_background_': 0,
"che": 1,
"biao": 2
}
LABEL_NAME_MAP = ['0: _background_',
'1: che',
'2: biao']-
在当前路径下打开命令行窗口,输入:
python ./new_json_to_dataset.py C:\TorchVision_Maskrcnn\Maskrcnn_LPR\labelme其中C:\TorchVision_Maskrcnn\Maskrcnn_LPR\labelme是你存放图片的路径 -
将
copy.py复制到刚刚的C:\TorchVision_Maskrcnn\Maskrcnn_LPR\labelme存放图片的路径,运行python ./copy.py将生成gts(mask)和png(原始图片)两个文件夹 -
将gts(mask)里面的所有文件复制到PedMasks文件夹,png(原始图片)里面的所有文件复制到PNGImages文件夹
在整个过程中你要安装 pycocotools,主要用到其中的IOU计算的库来评价模型的性能。但是这个安装并不简单,看了很多文章相对来说只有这篇文章最符合。(Windows下安装 pycocotools)
前言
为什么要说这个呢?因为如果你不是很有钱,或者公司有点抠买不起一张8G以上的显卡,不改动就训练这两个网络你基本上不可能成功。懂?财大气粗可以忽略……
因为本人就用的普通显卡(GTX1660,6G内存),训练Faster RCNN、Mask RCNN 这两个网络不要想着使用多GPU运行,我看了GitHub说了在windows上Faster RCNN、Mask RCNN暂时不支持多GPU运行。
幸运的是,在改动一些参数之后就可以完美运行。
Mask R-CNN是基于Faster R-CNN改造而来的。Faster R-CNN用于预测图像中潜在的目标框和分类得分.

而Mask R-CNN在此基础上加了一个额外的分支,用于预测每个实例的分割mask。
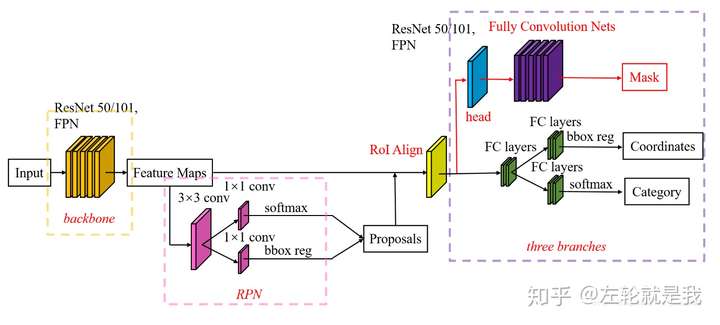
有两种方式来修改torchvision modelzoo中的模型,以达到预期的目的。第一种,采用预训练的模型,在修改网络最后一层后finetune。第二种,根据需要替换掉模型中的骨干网络,如将ResNet替换成MobileNet等。
假设你想从一个在COCO上预先训练过的模型开始,并想针对你的特定类对它进行微调。下面有一种可行的方法:
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
# 在COCO上加载经过预训练的预训练模型
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
#这个操作你是真的要有固定参数
for param in model.parameters():
param.requires_grad = False
# 将分类器替换为具有用户定义的 num_classes的新分类器
num_classes = 2 # 1 class (person) + background
# 获取分类器的输入参数的数量
in_features = model.roi_heads.box_predictor.cls_score.in_features
# 用新的头部替换预先训练好的头部
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)场景:替换掉模型的骨干网络。举例来说,默认的骨干网络(ResNet-50)对于某些应用来说可能参数过多不易部署,可以考虑将其替换成更轻量的网络(如MobileNet)。
import torchvision
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
# 加载用于分类的预先训练的模型并仅返回features
backbone = torchvision.models.mobilenet_v2(pretrained=True).features
# FasterRCNN需要知道骨干网中的输出通道数量。对于mobilenet_v2,它是1280,所以我们需要在这里添加它
backbone.out_channels = 1280
# 我们让RPN在每个空间位置生成5 x 3个Anchors(具有5种不同的大小和3种不同的宽高比)
# 我们有一个元组[元组[int]],因为每个特征映射可能具有不同的大小和宽高比
anchor_generator = AnchorGenerator(sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),))
# 定义一下我们将用于执行感兴趣区域裁剪的特征映射,以及重新缩放后裁剪的大小。
# 如果您的主干返回Tensor,则featmap_names应为[0]。
# 更一般地,主干应该返回OrderedDict [Tensor]
# 并且在featmap_names中,您可以选择要使用的功能映射。
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=[0],#featmap_names=['0']
output_size=7,
sampling_ratio=2)
# 将这些pieces放在FasterRCNN模型中
model = FasterRCNN(backbone,
num_classes=2,
rpn_anchor_generator=anchor_generator,
box_roi_pool=roi_pooler)import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from torchvision.models.detection.mask_rcnn import MaskRCNNPredictor
# load an instance segmentation model pre-trained on COCO
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=True)
for param in model.parameters():
param.requires_grad = False
num_classes = 3
# get the number of input features for the classifier
in_features = model.roi_heads.box_predictor.cls_score.in_features
# replace the pre-trained head with a new one
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
# now get the number of input features for the mask classifier
in_features_mask = model.roi_heads.mask_predictor.conv5_mask.in_channels
hidden_layer = 256
# and replace the mask predictor with a new one
model.roi_heads.mask_predictor = MaskRCNNPredictor(in_features_mask,
hidden_layer,
num_classes)import torchvision
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
# 加载用于分类的预先训练的模型并仅返回features
backbone = torchvision.models.mobilenet_v2(pretrained=True).features
# FasterRCNN需要知道骨干网中的输出通道数量。对于mobilenet_v2,它是1280,所以我们需要在这里添加它
backbone.out_channels = 1280
# 我们让RPN在每个空间位置生成5 x 3个Anchors(具有5种不同的大小和3种不同的宽高比)
# 我们有一个元组[元组[int]],因为每个特征映射可能具有不同的大小和宽高比
anchor_generator = AnchorGenerator(sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),))
# 定义一下我们将用于执行感兴趣区域裁剪的特征映射,以及重新缩放后裁剪的大小。
# 如果您的主干返回Tensor,则featmap_names应为[0]。
# 更一般地,主干应该返回OrderedDict [Tensor]
# 并且在featmap_names中,您可以选择要使用的功能映射。
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=[0],
output_size=7,
sampling_ratio=2)
mask_roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=[0],
output_size=14,
sampling_ratio=2)
model = MaskRCNN(backbone,
num_classes=2,
rpn_anchor_generator=anchor_generator,
box_roi_pool=roi_pooler,
mask_roi_pool=mask_roi_pooler)具体代码看我GitHub
训练过程总的来说没什么,平平无奇,但还是总结一下几个我遇到的坑。
- batch_size不宜过大,过大GPU吃不消
- num_workers设置为0,我也不知道我设置成其他数会报错
- 学习率lr不宜设置太小,可以循序渐进
- 不一定要使用lr_scheduler,可以一直保持一个固定的学习率(我的0.01)由于我内存不够我给他禁了,不过相应
engine.py的地方也得修改 - Mask RCNN 好像暂时不支持多GPU运行,(会的小伙伴下方请留言)
此外补充一个我在训练时发生的一个BUG:
TypeError: object of type <class 'numpy.float64'> cannot be safely interpreted as an integer.解决办法:
找到cocoeval.py文件,大概507行。 修改self.iouThrs = np.linspace(.5, 0.95, np.round((0.95 - .5) / .05) + 1, endpoint=True)为self.iouThrs = np.linspace(.5, 0.95, int(np.round((0.95 - .5) / .05) + 1), endpoint=True)修改self.recThrs = np.linspace(.0, 1.00, np.round((1.00 - .0) / .01) + 1, endpoint=True)为self.recThrs = np.linspace(.0, 1.00, int(np.round((1.00 - .0) / .01) + 1), endpoint=True)