Alteryx tool to output Semi-Structuted data to Snowflake. This includes:
- JSON
- XML
- PARQUET
- AVRO
- ORC
The tools allows for:
- Creating tables (drop if already exists) and appending data
- Truncate data in exisiting table and appending
- Append data to an existing table
Tables are created accoding to the Snowflake Documentation using the VARIANT data type. An exmpale of this SQL is shown below.
create or replace table mytable (column_name VARIANT)All the input files MUST be of the same type. The connector checks the file extentions of all the files and will stop with an error is there is more than one file extension found.
The files must also have a file extention of type json, xml, parquet, avro, orc. Any other files will stop the connector with an error.
It is up to you to only load files with the same schema, the connector will NOT check the schemas are the same and will load them regardless.
- Quote all fields (they will be case sensitive in Snowflake)
- Suspend the warehouse immediately after running (this will cause Snowflake to wait until current operations are finished first)
Download the yxi file and double click to install in Alteryx.

The tool will be installed in the Connectors category.
The tool installs the official Snowflake Connector library. If you have already installed another Snowflake SDK tool from me then it will share the same Python libraries as the other connectors.
This can be either via Snowflake or Okta. If you select Okta authentication this must be set up on the server according to the Snowflake Instructions.

The tool must be fed a list of full paths to the files you wish to upload. The easiest way to do this is to use a Directory tool to read the files and then map the FullPath field to the tool.
The files will then be loaded to the chosen table.

| The connector will use the column name containing the file paths as the column name in the Snowflake table so if you are not creating a new table this must of course match with the column name in Snowflake |
Configure the tool using the setting for you Snowflake instance. Note that the account is the string to the left of snowflakecomputing.com in your URL.
If you do not select a temporary path then the tool will use the default Alteryx temp path. Using this path the tool will create subfolders based on the current UNIX time.
| To automatically suspend the warehouse after running your user must have OPERATE permisions on the warehouse |
If you don't select the preserve case option then the fields will be created as provided by the upstream tool. These fields will be checked for validity and if found to be invalid they will automatically be quested so thet become case sensitive in Snowflake. This setting also applies to table names.
The tool will create log files for each run in the temp folder supplied. These logs contain detailed information on the Snowflake connection and can be used in case of unexected errors.
The tool has no output.
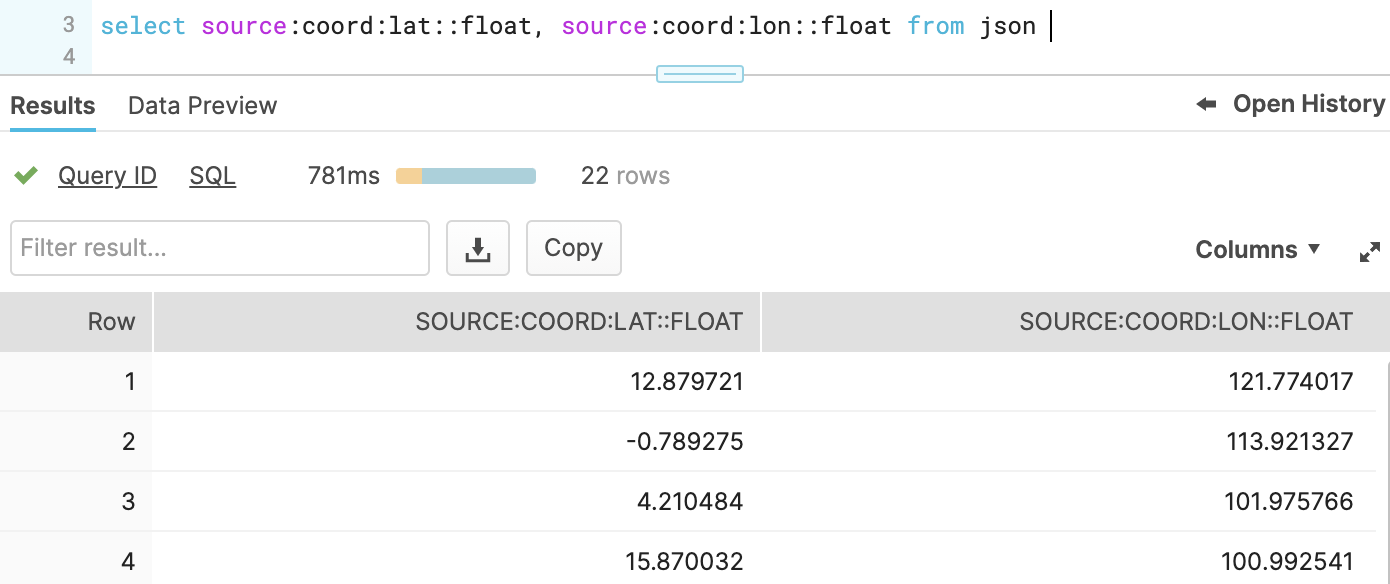
The JSON (or XML,...) data in Snowflake will look like this:

It can be quesried directly in Snowflake using the following syntax for JSON: