Resuse writes, initalize queues #363
Conversation
|
@benaadams When profiling, we see a fair amount of time spent resizing queues (though this is mostly in SocketOutput). Why did you close this PR? |
|
I didn't feel it was worthwhile to go round the Travis repeat loop for to try to get to pass; will rebase. |
d0123f3
to
e331b86
Compare
|
Rebased and added SocketOutput |
4746d28
to
36b71f8
Compare
|
Allocation reductions for 8k requests Before 32,023 objects; 2,032,968 bytes After 12,059 objects; 947,168 bytes 37% of the objects than before; 46% of the bytes of before |
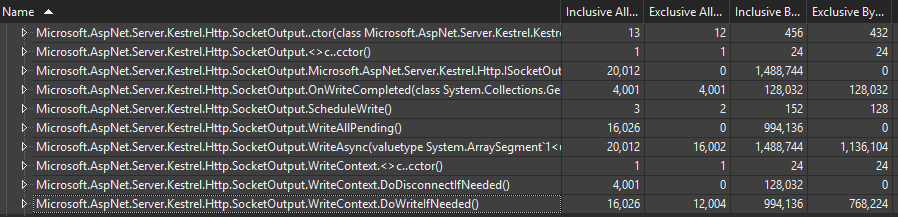
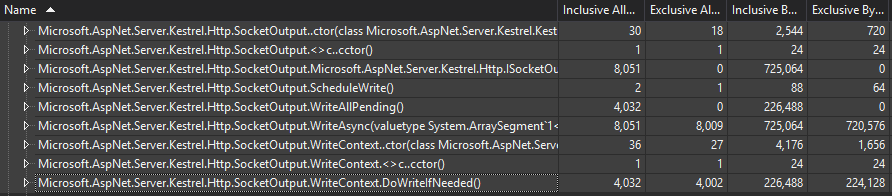
|
I think @CesarBS is pretty close to fixing our travis woes. I wouldn't bother going through the travis repeat loop until that gets in. Sorry that it's been such a pain for you. I should be able kick off reruns for all failing PRs myself once that's in. |
904ee08
to
9037939
Compare
|
Removed the allocs from |
|
And from UvWriteReq.Write |
|
Boom! Use |
f85f123
to
65221c8
Compare
65221c8
to
2a32d33
Compare
|
Rebased on 7e8a405 and measured. Basically the same. I really need to profile it to see if the size we're setting them to is high enough. |
|
Still spending some time in resizing it seems: |

|
@DamianEdwards that's quite a nice tool; what are you using? I'm have a hard time measuring GC with core; but 44.5% still; ouch! |
|
@benaadams I'm pretty sure that screenshot is from JetBrains DotTrace, not sure which version though. |
|
Yep, looks like and older version of dotTrace 😄 |
|
With 45% GC load though all bets are off on algorithmic improvements; need to get that overhead down first. |
|
Out of interest, which version of the GC were these tests run under? Server, Client, Background Server, Concurrent, etc? |
|
@DamianEdwards could you retest? Obv resizing the queues will add to GC pressure. Have increased the queues from and array of 16 pointers to an array of 64 pointers - shouldn't cause much difference in allocation expense i.e. objects allocated is the same and they are reused. |
Without waiting for next libuv pass Fix for potential regression in aspnet#363 due to bug fix.
|
Here are the numbers from wrk when running the plaintext benchmark with and without this change: Baseline: After merge: Nothing too significant RPS-wise. |
|
@halter73 Yeah, but look at latency...!
That's a massive improvement; as well as reduced variability. I'll take the x4 latency improvement with no detriment to RPS 👍 That's like being 1,000 km closer to your customers.. Can always increase bandwidth, can't increase the speed of light. |
f2e60cc
to
7236d4a
Compare
|
Rebased - tests pass; the App unhappy with |
|
@benaadams LogLevel.Verbose was recently renamed to LogLevel.Trace (aspnet/Announcements#124). Do you have the up-to-date logging packages? |
|
@muratg It fails both locally and on the CI server; https://ci.appveyor.com/project/aspnet-ci/kestrelhttpserver/build/1.0.867#L509. Also, the Travis build seems to be stuck; https://travis-ci.org/aspnet/KestrelHttpServer/pull_requests |
|
I guess the updated packages were not pushed to the feeds yet for some reason. cc: @pranavkm |
|
@muratg timing? Feeds updated 20 hours ago logging change went in 19 hours ago. |
|
We're going to need to get new numbers: #458 (comment) |
Without waiting for next libuv pass Fix for potential regression in aspnet#363 due to bug fix.
…rk' into default-work-queuesizes
7236d4a
to
4accd88
Compare
|
Merged #427 with this as it contains a regress fix. |
|
@benaadams What do you think of this idea of pooling UvWriteReqs instead of WriteContext? I started this change with the intention of continuing to pool WriteContexts, but have a shared pool per thread. I quickly realized this wouldn't be possible (without locking or a thread-safe data structure) since SocketOutput.WriteAsync is called from an arbitrary ThreadPool thread. So at the cost of one extra allocation (that of the WriteContext), we can now have a bigger pool shared by all connections managed by a given thread. I am thinking about opening a PR with this change, but since this is an alternative to pooling WriteContexts, I figured we could discuss it here first. |
|
@halter73 Well... minimising However... |
|
I'm not sure The |
|
On x64 the size of
88 bytes; for 4k requests (write+shutdown+disconnect) where they only have a single write its 1 MB The number of writes would be higher than the number of requests as there is generally more than 1 write per request. However, I agree with moving |
|
@halter73 which would be this on top of yours; look good? Added PR "SocketOutput Allocation Reductions" #466 with it. |
Without waiting for next libuv pass Fix for potential regression in aspnet#363 due to bug fix.
Without waiting for next libuv pass Fix for potential regression in aspnet#363 due to bug fix.
Reuse UvWriteReq on the socket rather than recreating for each write - pooled at per connection level.
Pre initialize the circular buffers; rather than resizing as work is added; with a copy on resize.
Saves 1.12 MB per 4k requests; see #363 (comment) for details.
Resolves #165 Pool UvWriteReq objects
Resolves #289 High Allocator DoWriteIfNeeded
Resolves #290 High Allocator SocketOutput.Write