顾宇浩助教的实验攻略
在CSDN查看后续更新版本:https://blog.csdn.net/u014132143/article/details/129489861
实现一个C语言的编译器很难吗?其实未必!依我个人的观点,编译器的代码并没有什么特别复杂的算法,理解起来不会很困难,但是它的工作量着实不小。古语有言:“庖丁解牛”,完成这些工作量的关键是要把握它内部的结构和脉络,如果没有一个合理的程序架构,那么这些工作量就会不断发酵,最终耗尽你的精力和耐心。
这篇攻略不会过多地关注工具的使用细节,而是重在阐述代码设计和编写的最佳实践,帮助你产出正确、美观、易维护的代码完成这项实验。攻略主要针对实验2,但正像你即将看到的,其中的内容对实验1和实验3也会有所帮助。
这一节是整个攻略最重要的内容。
在实验1我们使用Flex编写了一个词法分析器,它输入字符串形式的源代码然后将解析到的词法单元按行打印出来,这是一个比较简单的任务,也不需要写太多的代码,很多同学就全写在一个Flex文件中就搞定了。实验2的内容是从实验1输出的词法单元流中识别出语法结构,然后把结构用JSON打印出来,同学们最容易犯的一个设计错误就是以为这里和之前一样,把发射JSON语法树的代码直接就塞到Bison的语法定义文件中——事实上,实验2的复杂程度要高得多,所以这最终会导致一堆乱糟糟的代码和看不到尽头的调试过程。
这里的最佳实践是:**引入一个表达抽象语义的、方便编程操作的中间数据结构,Bison解析器首先将输入的词法单元流转换到这个数据结构,然后再将这个数据结构转换到JSON打印出来以满足实验要求。**实际上这个中间数据结构就是一种程序的中间表示形式(Intermediate Representation, IR),现代编译器通常会使用多层中间表示,在不同的中间表示上执行变换操作。从编程的角度来说,其实编译器设计的主要内容并不在于算法,而是数据结构,有了合理的数据结构,很多时候算法是显而易见的。
程序的抽象语义通常使用图,而不足以使用树来表示,因此我们称之为抽象语义图(Abstract Semantic Graph, ASG)。文法中经常会出现形如“表达式 -> 整数字面量 | 变量引用 | 二元运算”的选择结构和“加法 -> 表达式 ("+" | "-" | "*" | "/") 表达式”的递归结构,一些高级编程语言(比如OCaml)支持联合类型和递归类型,可以很好地表达它们,虽然C/C++中没有这些特性,但我们可以使用结构体和指针实现等价的效果:
struct Obj {
virtual ~Obj() = default;
};
struct Decl : public Obj { // 表达一个符号声明(变量、参数等)
std::string name; // 符号名
Type type; // 符号类型(这里省略了 struct Type 的定义)
};
struct Expr : public Obj {
Type type; // C语言的每个表达式都有类型
};
struct IntegerLiteral : public Expr {
std::int64_t val; // 整数字面量的值
}
struct DeclRefExpr : public Expr {
Decl* decl; // 指向引用的声明
};
struct BinaryExpr : public Expr {
enum { kAdd, kSub, kMul, kDiv } op; // 操作符
Expr *lft, *rht; // 指向左右操作数
};相信你一看到上面的代码,就能感觉到它确实高度精炼地表达了语言中真正有意义的那部分,而且正如前面提到的,这些结构体也非常容易编程操作。在你设计好ASG之后,这些结构体的定义不光可以用于完成实验2,也会成为在实验3中发射LLVM IR的起点,如果设计得当,在ASG的这一层IR上,你就已经可以很方便地实现常量传播、公共子表达式消除等许多优化算法了。
上面的代码中有两点需要重点注意:
-
所有类型都继承(直接或间接)自
Obj类型,且Obj的析构函数为虚;这样我们就可以用一个统一的类型
Obj*来引用所有类型的语义结构,而令析构函数为虚是为了让所有的类型都具备运行时类型识别(RTTI)的能力以分辨出具体的结点类型(通过dynamic_cast),以及用于对象的管理和回收。 -
可以引入一些中间子类(如
Expr),从而利用继承机制来更精确地表达选择结构。可以提供一些静态类型检查的辅助,这不是必须的,如果没有这些中间子类,那么对其它结点的引用可以都使用
Obj*的指针,但这就不能防止我们把一个Decl*赋值给BinaryExpr的lft和rht,虽然可以通过RTTI识别出错误,但实际上这种情况基本不会发射,因此这种灵活性其实是多余的。
指针在这里给了我们无与伦比的灵活性,这种灵活性可以大大减少之后的代码量,但是也给我们带来了一个问题:内存泄漏。从完成实验的角度,你完全可以new完不delete它,这并不会影响你通过测试样例,但这并不意味着我们应该放任这个问题的发生。
也许你在这里会去尝试使用std::unique_ptr或std::shared_ptr来管理Obj的生命周期,然而这不是一个有效的做法,因为就像之前说的,程序的语义通常要用图来表达,而不是简单树,因此几乎必然存在循环引用的问题(比如函数的递归调用),这时也许你又想到可以使用std::weak_ptr破除循环引用——然而这注定是一次没有结果的探索,这些花哨的智能指针并不适合这个场景,在这里最原始的指针就是最好用的。
最佳实践是:**使用一个单独的管理器接管所有对象的所有权,当我们在堆上创建任何对象时,使用资源获取即初始化(RAII)将指针交给管理器,然后让管理器析构时释放其管理的所有对象。**我们只需要保证管理器的生命周期比所有管理的对象都长,就可以避免指针悬挂。
我们可以非常容易地使用std::unique_ptr和std::vector实现一个最基本的管理器:
class Mgr : public std::vector<std::unique_ptr<Obj>> {};
Mgr gMgr; // 全局的管理器对象在上面的代码中,我出于简单起见直接创建了一个全局的管理器对象用于本次实验,这样可以它就可以获得最长的生命周期(尽管这样已经和内存泄漏没有什么区别了)。然后我们在创建每个对象时,只需要注意在new的时候将返回指针加入gMgr就行了:
Decl* compile_decl(...) {
auto decl = new Decl();
gMgr.push_back(decl);
// ...
return decl;
}每次申请对象都要写两行代码显得非常啰嗦,我们可以给Mgr添加一个make方法封装RAII操作:
class Mgr : public std::vector<std::unique_ptr<Obj>>
{
public:
// 第三个参数用于静态检查参数是否正确,也可以省略。
template<typename T,
typename... Args,
typename = std::enable_if_t<std::is_constructible_v<T, Args...>>>
T* make(Args... args)
{
auto ptr = std::make_unique<T>(args...);
auto obj = ptr.get();
emplace_back(std::move(ptr));
return obj;
}
};然后再创建对象时只要一个简洁的函数调用就能搞定了:
Decl* compile_decl(...) {
auto decl = gMgr.make<Decl>();
// ...
return decl;
}这种模式目前并没有一个公认的名称,不过我个人喜欢叫它“管理器模式”。如果你愿意,你甚至可以在此基础上多写一些代码进一步实现标记清扫垃圾回收,以在后续的处理过程中提前清理掉那些没有被引用的对象——不过这并不会为你在本实验中增加任何得分。
在学习了这么多编译原理的课程知识后,相信你已经了解了“语法解析树”和“抽象语法树”的概念,这里我们把它们进行对比一下,使用的例子是一个很短的全局变量声明:int a[2] = {0, 1}, *b = a + 1;。
-
语法解析树(Parse Tree)
语法解析树包含语法解析过程中的所有非终结符号和终结符号,一个递归下降语法分析器的运行过程可以视为是对语法解析树的深度优先遍历。语法解析树通常是非常复杂和庞大的,因此一般并不会真的生成出来,例如上面的例子如果真的生成一个语法解析树,那他可能是这个样子:
Loadingflowchart TB declaration_1 --> typeSpecifier_1 & initDeclaratorList_1 typeSpecifier_1 --> _17["'int'"] initDeclaratorList_1 --> initDeclarator_1 & _1["','"] & initDeclaratorList_2 initDeclarator_1 --> declarator_1 & _2["'='"] & initializer_1 initDeclaratorList_2 --> initDeclarator_2 & _11["ε"] declarator_1 --> directDeclarator_1 initializer_1 --> _6["'{'"] & initializerList_1 & _7["'}'"] initDeclarator_2 --> declarator_2 & _12["'='"] & initializer_4 directDeclarator_1 --> directDeclarator_2 & _4["'['"] & expression_1 & _5["']'"] initializerList_1 --> initializer_2 & _9["','"] & initializerList_2 declarator_2 --> _13["*"] & directDeclarator_3 initializer_4 --> expression_2 directDeclarator_2 --> _14["'a'"] expression_1 .-> integerLiteral_1 initializer_2 --> expression_3 initializerList_2 --> initializer_3 & _10["ε"] directDeclarator_3 --> _16["'b'"] expression_2 .-> additiveExpression_1 integerLiteral_1 --> _19["'2'"] expression_3 .-> integerLiteral_2 initializer_3 --> expression_4 additiveExpression_1 .-> expression_5 additiveExpression_1 --> _20["'+'"] additiveExpression_1 .-> expression_6 integerLiteral_2 --> _21["'0'"] expression_4 .-> integerLiteral_3 expression_5 .-> _23['a'] expression_6 .-> integerLiteral_4 integerLiteral_3 --> _22["'1'"] integerLiteral_4 --> _24["'1'"]希望这张图能够让你感受到语法解析树的复杂和庞大。而实际上,上图其实已经简化了表达式相关语法规则(虚线表示),后面为我们会看到,因为运算符优先级的存在,每个表达式结点实际上都会产生出一个长长的分支链。
-
抽象语法树(Abstract Syntax Tree)
抽象语法树通过去掉了那些只起到结构标识作用的结点、压缩树的层级等方式大大简化了语法解析树的结构。上面的例子对应的抽象语法树可能是:
Loadingflowchart TB declaration_1 --".typeSpecifier"--> _1["int"] declaration_1 --".initDeclaratorList[0]"--> initDeclarator_1 declaration_1 --".initDeclaratorList[1]"--> initDeclarator_2 initDeclarator_1 --".declarator"--> arrayDeclarator initDeclarator_1 --".initializer"--> initializerList_1 initDeclarator_2 --".declarator"--> pointerDeclarator initDeclarator_2 --".initializer"--> binaryExpressin_1 arrayDeclarator --".declarator"--> _2["Identifier\n'a'"] arrayDeclarator --".size"--> _3["integerLiteral\n2"] initializerList_1 --"[0]"--> _5["integerLiteral\n1"] initializerList_1 --"[1]"--> _6["integerLiteral\n2"] pointerDeclarator --".declarator"--> _4["Identifier\n'b'"] binaryExpressin_1 --".left"--> _7["Identifier\n'a'"] binaryExpressin_1 --".operator"--> + binaryExpressin_1 --".right"--> _8["integerLiteral\n1"]
很显然AST比语法解析树简单得多,如果你用过ANTLR、Boost.Spirit等语法解析器框架的话,就会知道这种语法解析器的输出结果往往都是这种形式。
-
抽象语义图(Abstract Semantic Graph)
单论名字的用法而言,大家并不是那么严格地区分“ASG”和“AST”,很多人把他的IR数据结构称为AST,尽管这些数据结构的引用关系在事实上是图而并非树。不过,相比于那些语法解析器框架,我们上面定义的C++结构体们与之还是有很大差别的,这主要体现在语义结点的相互引用上:
Loadingflowchart TB declarations --"[0]"--> declaration_1 declarations --"[1]"--> declaration_2 declaration_1 --".name"--> _13["'a'"] declaration_1 --".typeSpec"--> _1["int"] declaration_1 --".declarator"--> arrayDeclarator_1 declaration_1 --".initializer"--> initializerList_1 declaration_2 --".name"--> _14["'b'"] declaration_2 --".typeSpec"--> _12["int"] declaration_2 --".declarator"--> pointerDeclarator declaration_2 --".initializer"--> binaryExpressin_1 arrayDeclarator_1 --".declarator"--> _2[" "] arrayDeclarator_1 --".size"--> _3["integerLiteral\n2"] initializerList_1 --"[0]"--> _5["integerLiteral\n1"] initializerList_1 --"[1]"--> _6["integerLiteral\n2"] pointerDeclarator --".declarator"--> _4[" "] binaryExpressin_1 --".left"--> declReference_1 binaryExpressin_1 --".operator"--> + binaryExpressin_1 --".right"--> _8["integerLiteral\n1"] declReference_1 .-> declaration_1
相比于AST中存储的是变量名,我们在
declReference_1中直接存储指向变量声明的那个语义结点指针,这将会给后面的分析和变换的代码编写带来极大的便利。
Flex和Bison是实验框架默认的解析器生成工具,接下来我会介绍使用它们的最佳实践,由于Flex比较简单,主要是介绍Bison。
首先要明白的一点是,Flex和Bison的代码不是C和C++源代码,严格地说它们是专用于生成词法解析器和语法解析器的领域特定语言(DSL),一般的静态代码分析器通常不能很好地在上面工作,你的IDE也不能很好地助力你编写这些代码,因此最佳实践是:除非必要,否则尽可能不要将代码写在.l和.y文件里,让这两个文件保持尽可能地简单,除了生成词法和语法解析器外,不要有多余的功能。
Flex和Bison的代码文件在整体结构上都是被两个%%分成了三个部分:前言、主体、后记。理想情况下,后记完全可以留白,而前言中除了包含头文件指令不要写任何其它C/C++代码,所以,将你原本写在前言的C/C++代码都分离到两个另外的.h(.hpp)和.c(.cpp)文件中。如果你非要将代码.l和.y文件中,你应该在前言区只写函数和全局变量的声明,然后将定义写在后记中。
其次要明白的是,Flex和Bison是两个历史非常久远的工具了,许多现代的编程范式在其上都不适用,而且它们的用法是生成C代码,而不是C++,只是在后来逐步扩充了对其它功能的支持。所以,就本实验而言,如果你不想陷入对Flex和Bison琐碎的配置选项和技术细节的纠缠中,那么就应该小心地编写代码,尽量不要超出经典用法的场景。
Flex和Bison生成的代码分处于两个C源代码文件,它们各自单独编译,然后通过外部链接机制最终链接为一个整体。
Flex和Bison默认用法的场景是传统的命令行指令式程序,生成使用全局变量的不可重入代码,并且Flex固定地从<stdio.h>输入输出数据。两者的关系以Bison为主,Flex只是辅助的可选项:Bison从代码文件生成一个int yyparse();函数,其内部调用两个需要我们补充定义的函数int yylex();、void yyerror(const char *)来读取词法单元流和报告错误,Flex就是用于生成那个yylex函数。
在联合使用时,我们应该首先编写Bison语法定义(.y),通过前言区的%token定义有哪几种词法单元,然后在Flex代码中包含生成的头文件,再编写词法单元的解析规则,这和我们实验1到实验2的顺序是相反的。知道这些之后,我们就得到了基本的文件骨架:
-
parser.y%code requires { int yylex(); void yyerror(const char *); } %% %%为了让Bison生成的代码能够通过编译环节,必须在其中加入
yylex和yyerror的声明。此处可以使用
%{ ... %}代替%code requires { ... },它们的区别是后者的代码会输出到头文件中,而前者只是输出到源文件中,因此%code requires更合适,详见Bison文档。 -
lexer.l%{ #include "parser.tab.h" %} %% %%其中头文件名
"parser.tab.h"是Bison的默认名字,你应该填你实际指定的文件名。这样生成的词法解析器代码默认会调用一个外部定义函数yywrap,如果你没定义就会导致链接通不过,对于本实验而言这个函数是没用的,因此实验1中的模板代码在前言区加入了一行%option noyywrap。
这里是一个最小的具体例子,用于解析正负数字:
-
parser.y%code top { int yylex (void); void yyerror (char const *); } %token NUMBER %token ADD %token SUB %% start: NUMBER | ADD NUMBER | SUB NUMBER; %% -
lexer.l%{ #include "parser.tab.h" %} %option noyywrap %% [0-9]+ { return NUMBER; } "+" { return ADD; } "-" { return SUB; } %%
为了更好地展示Flex和Bison的联合使用,这里是我写的一个计算加减乘除表达式的具体例子:https://github.com/yhgu2000/flex-bison-calc-example
你已经在理论课上了解到,每个语法解析树的结点都会和一些“属性”关联起来,不同结点有哪些属性一般都是不一样的,反映到代码里就是不同非终结符和终结符的语义值类型是不一样的,比如一个整数字面量可能对应一个int,而一个字符串字面量可能对应一个char*,所以总的而言文法符号的语义类型是这些类型的“或”,也就是一个联合类型,对应C中的联合体union。但是,使用联合体是十分容易出错的,Bison考虑到了这一点,所以它提供了%union和$n机制代替我们直接编写和操作联合体。
在前言区,使用%union定义所有可能的语义值类型,然后在%nterm和%token中将文法符号和类型关联起来:
%union {
int num;
char* str;
}
%nterm <str> start
%token <num> NUMBER
%token <str> STRING
然后在主体部分直接使用$n就可以操作文法符号对应的语义值:
start: NUMBER STRING { $$ = $2 + $1; } ;
其中$$、$1、$2会被Bison自动拓展为类似于start.str、NUMBER.num、STRING.str的联合体成员引用,并且Bison会帮我们检查类型的使用是否正确。语义值最终的来源是词法解析器,在yylex函数(flex主体部分)中,使用全局变量yylval填入词法单元的语义值,不过这里就需要我们手动引用成员了:
[0-9]+ {
yylval.num = atol(yytext);
return NUMBER;
}
[a-zA-Z]+ {
char* str = malloc(strlen(yytext));
strcpy(str, yytext);
yylval.str = str;
return STRING;
}
如果有一些文法符号没有语义值(比如C语句的分号),那么%nterm和%token的类型标注<...>可以省略。
前面我说过,Flex和Bison原先设计是生成C代码,可是我们的实验却假定同学们使用的是C++,所以在这里使用%union时需要特别注意,其所有成员必须是简旧数据类型(POD),如果你不知道什么是POD,简单地说就是不能有构造函数和析构函数,所以你不能在%union里使用std::string这样的C++类。
事实上你可以在C++的联合体中使用非POD,只是同时需要补充构造函数和析构函数的定义,而为此你又需要了解许多C++类和内存管理的底层细节。
如果你按照我前一节中的内容设计你的ASG,那么在这里就不是问题,因为前一节中就是直接使用指针引用ASG结构体的,而ASG结构体中是可以使用非POD的成员变量的,使用一个全局的管理器(gMgr),你就可以在Bison代码里创建这些ASG结构体,像这样:
/* ... */
%code requires {
#include "asg.hpp" // 为了%union中使用ASG结构体类型
}
%union {
Obj* obj;
Decl* decl;
Expr* expr;
}
%nterm <expr> expression
%token <expr>
/* ... other nterms */
%token <expr> NUMBER
%token ADD
/* ... other tokens */
%%
expression: NUMBER | binaryOp ;
binaryOp:
expression ADD expression {
auto p = gMgr.make<BinaryOp>();
p->op = BinaryOp::kAdd;
p->lft = $1, p->rht = $3;
$$ = p;
}
;
/* ... other rules */
%%
我向你保证这种模式完全足以完成整个实验,但是如果你非要用一些非POD的语义值类型,Bison也提供了一个Variant类型支持,这时就不能再用%union了,取而代之的是要在导言区写上一行%define api.value.type variant,然后在%nterm和%token的尖括号里直接写类型名(而非%union成员),具体的细节请直接阅读文档,这里不再赘述。
-
如何获取解析结果
解析结果存储在根产生式结点对应的联合体对象中,我们可以引入一个全局变量和一个顶级产生式来向
yyparse的调用者返回这个对象:%code requires { #include "asg.hpp" extern Obj* gRoot; } %union { Obj* obj; Decl* decl; Expr* expr; } /* ... */ %% start: expression { gRoot = $1; }; expression: NUMBER | binaryOp ; /* ... */ %% -
生成可重入的解析器
实际项目中经常要求代码的可重入性,而以上所说的Flex和Bison使用方式生成的是不可重入的代码。举例来说,因为生成的代码中使用了全局变量,所以如果使用多线程同时解析多个输入文件就会出现并发安全问题,通常会引发未定义行为。
针对这种情况,Bison提供了两种方案,第一种是给
yyparse等函数添加额外的参数,这主要用于C语言代码,第二种用于C++,是将代码放到一个类中以实现可重入性,Flex也是这样。但是这种情况下将Flex和Bison联合使用就不再是那么简单了,就像之前所说的,这两种超出经典的用法都会带来一些新的问题,就本实验而言,为这些问题耗费心思不会给你带来任何的收益,所以这里不再展开介绍。相关文档:
现在你已经设计好你的ASG了,也知道如何从文本中解析出ASG了,距离实验2的目标只差把你得到的ASG打印输出为JSON了,这一步该怎么做呢?一些对C++有所了解的人可能会想当然地使用虚函数和动态转发机制,他们写出的代码类似这样:
struct Obj {
virtual ~Obj() = default;
virtual json::value to_json() = 0;
};
struct Decl : public Obj {
virtual json::value to_json() override { /* ... */ }
}
struct Expr : public Obj {
virtual json::value to_json() override { /* ... */ }
}
/* ... */然而这种写法在这里是一个常见的设计错误,想象一下,如果我们还要把ASG打印为XML、YAML、TOML等其它格式,或者是接下来在实验3中发射LLVM IR,那么我们是不是就要在ASG的类定义中加入一堆毫不相干的成员?这显然违背了“高内聚”的设计原则,而事实上也确实会导致杂乱和难以维护的代码,所以,最佳实践是:将每种遍历操作的代码从ASG的定义中分离出来,保持ASG代码的简洁,如果将这些分离出的代码放到一个类中,那么这就是Visitor模式。
常见的Visitor类写法是重载类的调用成员函数operator()(),以上面代码为例,提取出的ToJson类大概像这个样子:
struct ToJson {
json::value operator()(Decl*);
json::object operator()(Expr*);
/* ... */
private:
int _counter;
/* ... */
};在上面的代码中可以看到Visitor模式的优点:
- 对于不同的数据类型可以有不同的函数签名;
- 遍历过程中使用的额外数据和变量只会在存在于遍历过程中,而不是一直存储在ASG类上。
对于“表达式 -> 整数字面量 | 变量引用 | 二元运算”这样的选择结构,在对应的遍历方法中使用dynamic_cast:
json::value ToJson::operator()(Expr* obj) {
if (auto p = dynamic_cast<IntegerLiteral*>(obj))
return (*this)(p);
if (auto p = dynamic_cast<DeclRefExpr*>(obj))
return (*this)(p);
if (auto p = dynamic_cast<BinaryOp*>(obj))
return (*this)(p);
/* ... */
}在编译器这个场景,有些时候允许遍历器在结点中存储一些数据会更方便或者更高效,一个最简单做法是在Obj类中加上一个空类型的指针:
struct Obj {
void* _any;
virtual ~Obj() = default;
};然后在遍历器的代码中,将这个指针reinterpret_cast到所知的类型。或者也可以使用std::any以确保类型安全:
struct Obj {
std::any _any;
virtual ~Obj() = default;
};如果在运行中发现错误(比如dynamic_cast失败),我们的代码应该如何处理?常见的回答有以下几种模式:
- 假定不会出错,出错是未定义行为;
- 可能出错的函数返回一个错误码(通常是
int类型); - 使用一个全局的错误码变量(例如标准库的
errno); - 抛出C++异常;
- 返回一个
Result<T,E>或者Optional<T>对象。
可能你会不假思索地使用方式4,没错,抛出异常的确是符合C++编程风格的错误处理方式,但我需要提醒你的是,这个实验不考察你的错误处理,它的所有测试用例都是正确的、要求能通过编译的,并且在可见的将来也不会加入对错误处理的考察。也就是说,你在错误处理上花费的心血不会为你多加一分,所以这里你可以直接使用方式1,不过你应该给所有的意外情况都加上assert(false);或者abort();,这是为了在调试时及时发现实现上的错误,防止程序在出错时跑飞掉。
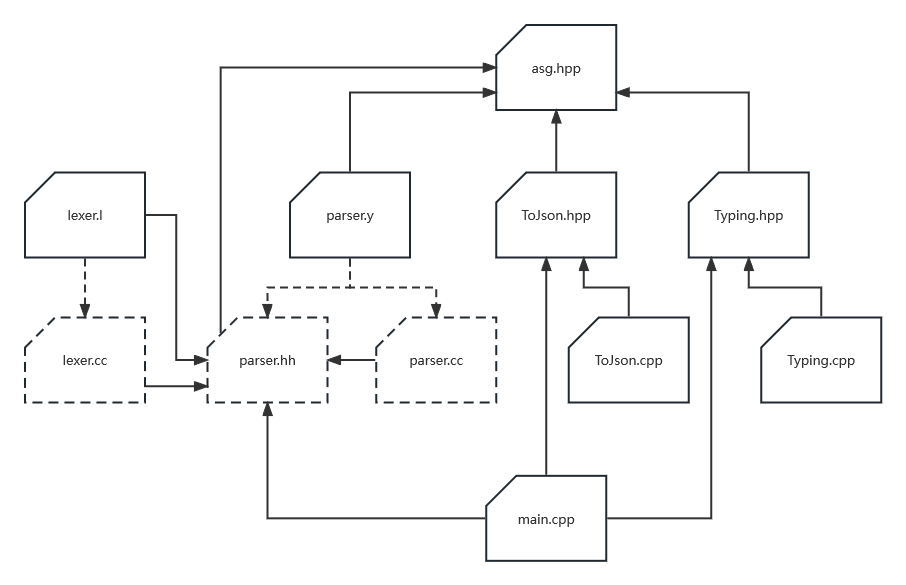
lexer.l和parser.y相关的文件肯定不必多说,我解释一下其它文件中的内容:
-
asg.hpp由于使用了Visitor模式,ASG的代码就只是一堆类和结构体的定义,因此不需要有源文件。
-
lexer.l和lexer.cc这两个文件是可选的。在本实验中,实验2程序实际接受的输入是已经完成词法分析环节的词法单元流,其中每行是一个词法单元,对于这种形式的输入,可以仍然使用Flex生成
yylex函数,但也可以直接手写,这时相比之下手写反而更为简单直接。 -
ToJson.hpp和ToJson.cpp定义和实现转换ASG为JSON的Visitor。
-
Typing.hpp和Typing.cpp如果你想和clang一样输出包含完整类型信息的语法树,那么就需要再写一个Visitor来做类型推导和检查。
事实上clang发射的JSON语法树有一些结点就是为类型系统服务的,因此如果你想通过实验2也许不得不实现这个Visitor。
-
main.cpp程序入口,将其它代码简单地结合起来。由于程序的主体代码都在其它地方,所以这个文件的代码通常不会太长,一般只有10~30行左右。
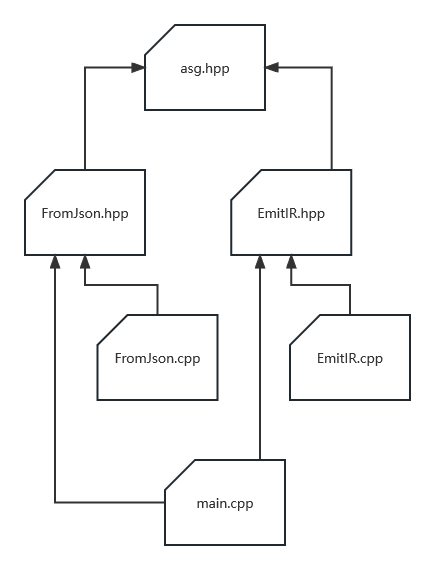
如图所示,实验3的代码结构反而要简单得多。如果你在实验2中设计得当,那么其中的asg.hpp完全可以一个字都不用改地复用,你也可以再复用实验二中的Typing.hpp和Typing.cpp,对输入的JSON再做一次类型检查。对于其它的文件:
-
FromJson.hpp和FromJson.cpp解析JSON构造ASG,这是一个JSON数据类型的Visitor。
-
EmitIR.hpp和EmitIR.cpp定义和实现一个ASG的Visitor,调用LLVM的API,将ASG发射到LLVM IR。这部分代码的主要难点在熟悉LLVM API的用法,而并非算法本身,就和前面说的一样,如果你厘清了编译器的结构,那么这些代码其实就只不过相当于“把话换一种方式说出来”而已,没有什么难以理解的。
ToJson和FromJson是出于实验评测的要求才必须有的,在你通过所有实验(包括实验4)后,你完全可以跳过JSON的这个中间环节,直接从文本形式的源代码生成最终的可执行二进制文件,这时你项目的整体代码架构就会和上图展示的一样。
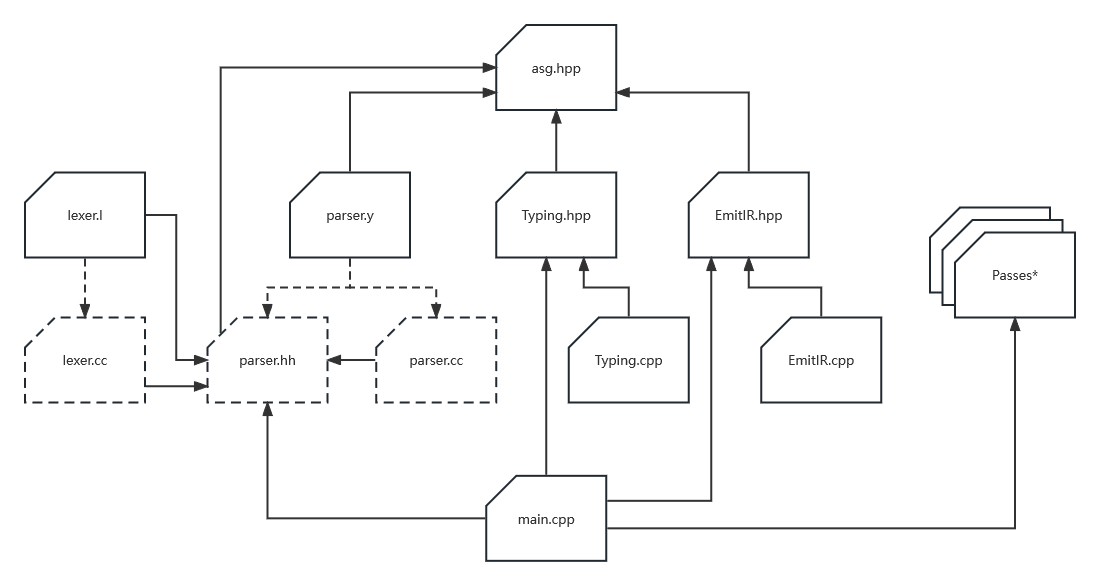
其中Passes*就是你写的各种优化趟,它具体的写法是由LLVM框架的设计决定的;这里的main.cpp仍然是将其它代码简单地结合起来而已,不过为了输出二进制文件,你可能需要查阅更多的LLVM文档,这部分代码的编写就没有在我们的实验中涉及了。
最后,我在这里给出一些文法规则设计层面的提示,相比于写实验代码,这些提示和理论课的内容更接近,也许它们可以避免你落入陷阱。
我们知道C和很多语言的标识符词法规则都是[a-zA-z_][a-zA-z_0-9]*,而绝大部分保留字也是符合这个词法规则的,比如if、while,因此这里就多出了一个设计选项:我们可以在词法分析环节将保留字一并处理为标识符,然后在之后的语法解析环节再做区分,这种设计选项好不好呢?
应该说,大部分情况下,你都应该尽量避免这么做,因为将这些逻辑越早地实现,你就可以越少写一些代码。然而,实际也会有不得不这么做的时候,这往往是因为语言在之后的演进中引入了新的关键字,比如Python的case。
表达式语法是一个经典且重要的文法设计案例,这些文法规则淋漓尽致地体现了上下文无关文法的特征,并且几乎在所有编程语言都有用到,和表达式语法相关的问题有两个:优先级和结合性,Bison为表达式的优先级和结合性特意提供了一套机制,但是仍然有必要掌握使用上下文无关文法描述优先级和结合性的方法,因为其它的语法解析框架不一定有这些机制。
对比一下,下面两种文法规则分别生成左结合和右结合的语法树:
- 左结合:
表达式序列 -> 表达式 | 表达式序列 ("+" | "-") 表达式 - 右结合:
表达式序列 -> 表达式 | 表达式 ("+" | "-") 表达式序列
而不同的优先级可以通过为每层引入一个非终结符实现:
表达式 -> 加减
加减 -> 乘除 | 乘除 ("+" | "-") 乘除
乘除 -> 原子 | 原子 ("*" | "/") 原子
原子 -> 数字 | "(" 表达式 ")"
这种方式的一个缺点是在每个表达式在解析时都会产生很深的调用栈,这可能带来性能和内存使用方面的问题,不过这确实是一种常见的实现方式。
这也是为什么第一节中的示例语法解析树我要省略表达式相关结点。
C的类型表达式语法是为大家广为诟病的设计缺陷,在你做这个实验时你会更深刻地感受到这一点。处理它的棘手之处主要有两点:
-
C的类型语法是包裹起来的,而非是展开的,声明语句的符号名在最里面;
比如这样的变量声明语句:
int a, *b, (*c)(int c, int d);。 -
C的类型表达式是从内到外的,而非和它的表达式一样是从外到内的。
比如,
int a[2][3];的语义结构是这样:Loadingflowchart TB Decl --> int["'int'"] & Array1 & a["'a'"] Array1 --> Array2 Array1 --.size--> 2 Array2 --.size--> 3
而
a[2][3]的语义结构却是这样:Loadingflowchart TB IndexExpr1 --> IndexExpr2 & 3 IndexExpr2 --> a & 2
如果你真的总结不出来它的语法规则,你可以看一看ANTLR给出的答案:https://github.com/antlr/grammars-v4/blob/master/c/C.g4。
在C里产生这个问题的产生式是下面这两条:
语句 -> 选择 | ...
选择 -> "if" 语句 "else" 语句
直接在Bison里输入这两条语法就会报告一个移入归约冲突的警告。这是一个非常经典的问题,你可以参考《编译原理》(龙书)P133页,Bison文档中也有给出相关解决方案,因为过于经典我就不再这里赘述了。