Change new concat #11800
Change new concat #11800
Conversation
|
I got some promising improvements with this change (same setup as in #11341 (comment)): |
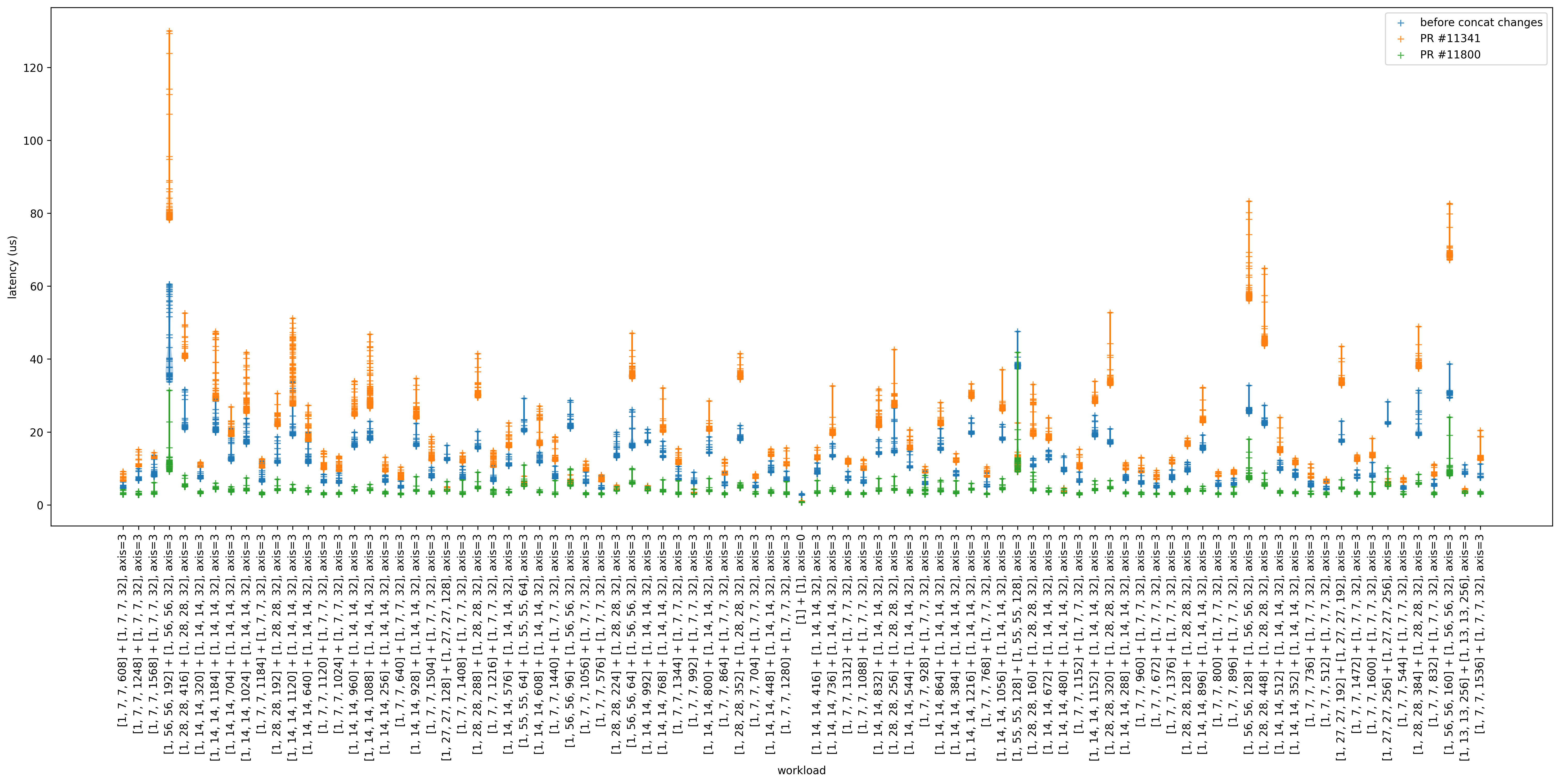
|
@shtinsa I think |
|
Hello @masahi yes, I saw the const_matrix solution and it works on IR level, but IMHO it looks like as workaround. I suppose it is necessary to extend the codegen part to support |
|
we discussed the effect of this PR on the codebase at the TVM Community Meeting this morning. @SebastianBoblest notes that this PR caused a significant change in the output in their code (see community meeting recording), and wonders:
@SebastianBoblest notes that it's hard to write a test against the generated code because level
@kparzysz-quic : what don't we like about this particular code snippet:
@kparzysz-quic: small change should not make a large change downstream. difficult to answer because complexity of compiler can cause cascading differences.
@driazati : one way we can address this is to make the generated code part of the test and require folks to update the test.
to follow-up here, we should probably work up a small RFC or discuss post to describe the proposed additional tooling. |
|
I watched the stream and it looks like the problem related incorrect fusing of GRU/Attention output. @SebastianBoblest could you please provide test scenario to reproduce the issue? |
Hi, I will try to create a minimal script for this next week. Thanks for still looking into this! |
Hi I created a minimal example for an lstm. |
|
Hello, thanks a lot! |
* changed x86/concat to use lists of ints instead of te.tensor.Tensor for loop extents and array offsets * typos fixed * removed unused import * fixed micro model test * fixed micro model test
|
Hello @SebastianBoblest, sorry for the delayed answer, and I would like to clarify the issue from the sample above. According to the c codegen output I see that new functionality provides following code snippets: Where where the first and second loops are fused and the T_squeeze_let buffer removed from the global space? |
Hi @shtinsa, |
This is a proposed change to the new topi x86 concat implementation in #11341. It uses simple lists of int instead of
te.tensor.Tensorfor the array offsets and loop variable extents. I have only looked at the generated C code and made sure that the relevant unit tests pass.New version:
Old version:
@DzAvril @shtinsa @MichaelJKlaiber @UlrikHjort-Bosch @vdkhoi @masahi