[SPARK-43267][JDBC] Handle postgres unknown user-defined column as string in array#40953
Closed
Hisoka-X wants to merge 3 commits intoapache:masterfrom
Closed
[SPARK-43267][JDBC] Handle postgres unknown user-defined column as string in array#40953Hisoka-X wants to merge 3 commits intoapache:masterfrom
Hisoka-X wants to merge 3 commits intoapache:masterfrom
Conversation
Member
Author
|
@cloud-fan @MaxGekk @hvanhovell Hi, PTAL. Thanks! |
Contributor
ulysses-you
reviewed
Jun 1, 2023
yaooqinn
approved these changes
Jun 2, 2023
Member
|
thanks, merged to master |
czxm
pushed a commit
to czxm/spark
that referenced
this pull request
Jun 12, 2023
…ring in array
### What changes were proposed in this pull request?
Spark SQL now doesn’t support creating data frame from a Postgres table that contains user-defined array column.
This PR support it as string.
### Why are the changes needed?
Support handle user-defined array column in SPARK SQL with Postgres
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
1. Add new test.
2. Tested in local.
```sql
CREATE DOMAIN not_null_text
AS TEXT
DEFAULT '';
create table films
(
code char(5 char) not null
constraint firstkey
primary key,
title varchar(40 char) not null,
did bigint not null,
date_prod date,
kind varchar(10 char),
tz timestamp with time zone,
int_arr integer[],
column_name not_null_text[],
column_name2 not_null_text
);
INSERT INTO public.films (code, title, did, date_prod, kind, tz, int_arr, column_name, column_name2) VALUES (e'2
', 'fdas', 1, '2023-04-07 16:05:48', '2', null, null, null, null);
INSERT INTO public.films (code, title, did, date_prod, kind, tz, int_arr, column_name, column_name2) VALUES (e'4
', 'fdsa', 1, '2023-04-07 16:05:48', '4', null, null, null, null);
INSERT INTO public.films (code, title, did, date_prod, kind, tz, int_arr, column_name, column_name2) VALUES ('1 ', 'dafsdf', 1, '2023-04-04 14:43:51', '1', '2023-04-25 18:53:17.467000 +00:00', '{1,2,3}', '{1,fds,fdsa}', 'fdasfasdf');
```
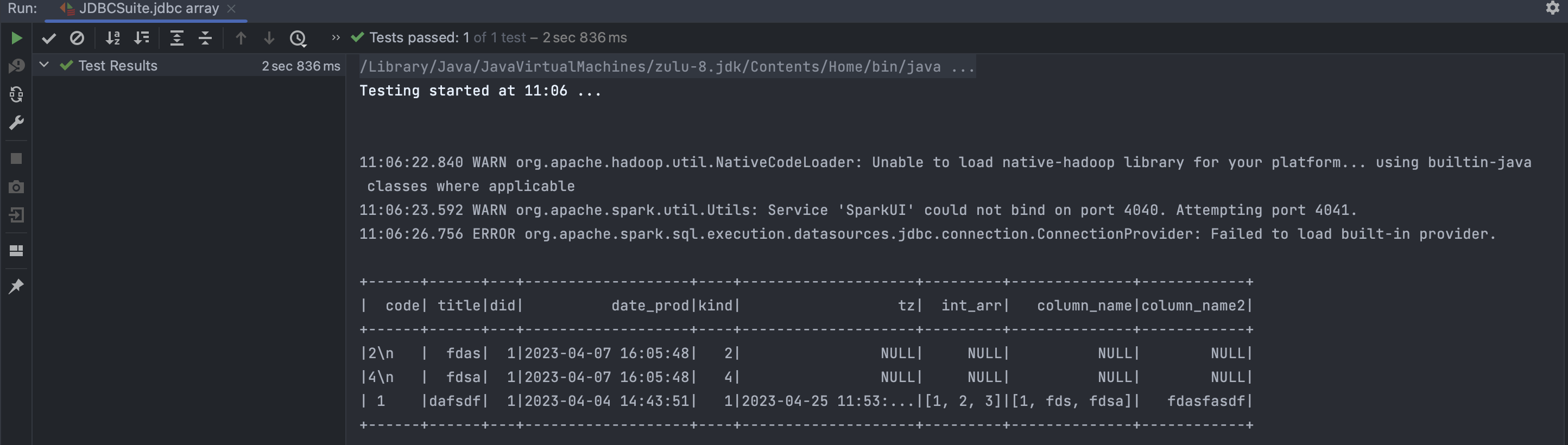
Test Case
```scala
test("jdbc array") {
val connectionProperties = new Properties()
connectionProperties.put("user", "system")
connectionProperties.put("password", "system")
spark.read.jdbc(
url = "jdbc:postgresql://localhost:54321/test?useSSL=false&serverTimezone=UTC" +
"&useUnicode=true&characterEncoding=utf-8",
table = "TEST.public.films",
connectionProperties
).show()
}
```
Result
<img width="1444" alt="image" src="https://user-images.githubusercontent.com/32387433/234458027-e67e410b-c417-400d-be7e-431768afc0ef.png">
Closes apache#40953 from Hisoka-X/SPARK-43267_pg_array.
Lead-authored-by: Jia Fan <fanjiaeminem@qq.com>
Co-authored-by: Hisoka <fanjiaeminem@qq.com>
Signed-off-by: Kent Yao <yao@apache.org>
{kind=link}
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
4 participants
Add this suggestion to a batch that can be applied as a single commit.This suggestion is invalid because no changes were made to the code.Suggestions cannot be applied while the pull request is closed.Suggestions cannot be applied while viewing a subset of changes.Only one suggestion per line can be applied in a batch.Add this suggestion to a batch that can be applied as a single commit.Applying suggestions on deleted lines is not supported.You must change the existing code in this line in order to create a valid suggestion.Outdated suggestions cannot be applied.This suggestion has been applied or marked resolved.Suggestions cannot be applied from pending reviews.Suggestions cannot be applied on multi-line comments.Suggestions cannot be applied while the pull request is queued to merge.Suggestion cannot be applied right now. Please check back later.
What changes were proposed in this pull request?
Spark SQL now doesn’t support creating data frame from a Postgres table that contains user-defined array column.
This PR support it as string.
Why are the changes needed?
Support handle user-defined array column in SPARK SQL with Postgres
Does this PR introduce any user-facing change?
No
How was this patch tested?
Test Case
Result
