[SPARK-43263][BUILD] Upgrade FasterXML jackson to 2.15.0
#40933
Conversation
|
CC @pjfanning |
|
if you use jackson 2.14.2 - you can just upgrade snakeyaml to 2.x (there is a fix in jackson 2.14.2 that makes it easier to upgrade snakeyaml dependency) jackson 2.15.0 has extra changes that you need to worry about - see https://issues.apache.org/jira/browse/SPARK-42854 |
|
Looks good, just resolve the conflict and we can check tests again |
|
@srowen CVE-2022-1471 is a snakeyaml CVE and you can upgrade snakeyaml explicitly without upgrading jackson. Jackson 2.15 applies limits on the JSON inputs it parses. It is probably not a good idea to use Jackson 2.15 without supporting overrides for these limits. See SPARK-42854. |
|
Ah OK, @bjornjorgensen how about just doing snakeyaml here as an intermediate step? |
|
Snakeyaml 1.32 introduced an approx 5mb default limit on input yaml. Spark trunk already has this change but it might be worth considering making this limit configurable using spark configs. The snakeyaml class to look for is called LoaderOptions. |
|
It seems to have added 4 constraints, but May be we should add corresponding configurable items to This may handle most scenarios, but there are still some places in Spark that call If there is a problem with what I said, please correct me @pjfanning , thanks |
|
And will these new constraints make JSON parsing slower? |
|
@LuciferYang your analysis summarises the situation well |
there is no evidence of a significant performance drop |
|
@bjornjorgensen can you engage with the comments? A few of us have basically asked for this PR to be modified or redone but not to proceed as it is.
|
|
@pjfanning yes, sorry |
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/JSONOptions.scala
Outdated
Show resolved
Hide resolved
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/JSONOptions.scala
Outdated
Show resolved
Hide resolved
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/JSONOptions.scala
Show resolved
Hide resolved
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/JSONOptions.scala
Outdated
Show resolved
Hide resolved
|
Please fix the compilation error first @bjornjorgensen thanks |
|
I found https://github.com/scala/scala/milestone/99 |
@LuciferYang Core Scala libs don't have a dependency on Jackson. This upgrade seems to affect a module called |
|
anyway this is my "hello world" in Scala. |
|
|
||
| import JSONOptions._ | ||
|
|
||
| private val maxNestingDepth: Int = parameters |
There was a problem hiding this comment.
don't make any changes yet - but @LuciferYang, are there are guidelines about to handle cases where the parameter values are not convertible to ints (.toInt fails) and where the values evaluate to negative values (which will cause an IllegalArgumentException when setting up StreamReadConstraints
There was a problem hiding this comment.
I think this is fine. It's a niche set of configs that very few would set. If they set a bad value, a raw error is even OK.
Well, upgrading SnakeYAML might work as a temporary solution, but for Spark's long-term benefit, I believe it's best to upgrade Jackson now. This will make future upgrades of Jackson much easier. Additionally, Snyk has opened two PRs to upgrade |
 srowen
left a comment
srowen
left a comment
There was a problem hiding this comment.
I think this is OK for master, as we have a safety valve for the only issue we can think of in jackson 2.15 usage, and aren't complicating anything unnecessarily by exposing those. Like, I don't think we should doc these yet.
|
|
||
| import JSONOptions._ | ||
|
|
||
| private val maxNestingDepth: Int = parameters |
There was a problem hiding this comment.
I think this is fine. It's a niche set of configs that very few would set. If they set a bad value, a raw error is even OK.
|
we can upgrade it to Or chatGPT will have this Cache frequently used values to reduce the number of map lookups. For example, in the JSONOptions class, you can create lazy vals for the frequently accessed parameters: In the safeStringToInt method, you can use scala.util.Try to handle the conversion from String to Int: Consider using getOrElse with a default value directly instead of map followed by getOrElse for some parameters: but it seams to be to mach.. |
|
I think it's overkill to put too much processing into this arg parsing |
 LuciferYang
left a comment
LuciferYang
left a comment
There was a problem hiding this comment.
+1, LGTM ~
Agree with @srowen , it's ok now, don't make things too complicated
|
Merged to master |
|
Thank you all so much for your help and support for this update. |
|
Note that this breaks downstream projects that want to read json: spark.read.json("file.json")The reason is that spark-core depends on avro 1.11.1, which pulls in jackson-core 2.12.7: Project avro has upgraded to jackson 2.15.0 a few days ago: apache/avro@3b6c6cc I think for this upgrade in Spark to work, the avro dependency of spark-core has to be upgraded to their next release as well. My project depends on spark-core and spark-sql only. |
|
@EnricoMi I read and write JSON files using pyspark. I haven't seen any problems so far. |
|
I doubt I am talking about Java / Scala projects that depend on |
|
All wrappers would be affected if any are, as all of this goes through the JVM for JSON processing. |
|
Spark pulls in Jackson 2.15.0 for compile scope. Projects depending on Spark do not transitively depend on Jackson 2.15.0. Spark depends on Avro which depends on Jackson 2.12.7. Projects that depend on Spark transitively depend on Jackson 2.12.7. Maybe spark-core should depend on Jackson 2.15.0 with runtime scope, rather than compile scope. The following pom reproduces the issue: <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>uk.co.gresearch.spark</groupId>
<artifactId>spark-example_2.13</artifactId>
<version>1.0.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.13</artifactId>
<version>3.5.0-SNAPSHOT</version>
<scope>provided</scope>
</dependency>
</dependencies>
<repositories>
<!-- required to resolve Spark snapshot versions -->
<repository>
<id>apache snapshots</id>
<name>Apache Snapshots</name>
<url>https://repository.apache.org/snapshots/</url>
</repository>
</repositories>
</project>mvn dependency:tree |
|
They do transitively depend on Jackson, if it's compile scope. Lots of stuff would never work otherwise. You are correct that there is a conflict that Maven resolves, and its rules may not give the desired effect. However Spark does "all it can do" by directly depending on Jackson. The only thing I can think of is to also exclude the jackson dep from Avro explicitly in the Spark POM? |
But then we will have to write a lot of testes to test Avro with jackson version 2.15.0. Cant we open a issue in Avro and ask for a new version? There lasts release is from Aug 5, 2022. |
|
That was my initial suggested solution. Once Avro releases a new version, and Spark is compatible with that, the problem should be resolved by upgrading to that new Avro version. |
|
I'm a Jackson committer and 2.15.0 has some big changes in it. A number of changes have already been made based on some bugs and some tweaking of the changes (for a forthcoming v2.15.1 release). I would discourage anyone from making releases that are based on Jackson 2.15.0. |
|
I found a fix on my side, the order of dependencies in my pom is significant here:
|
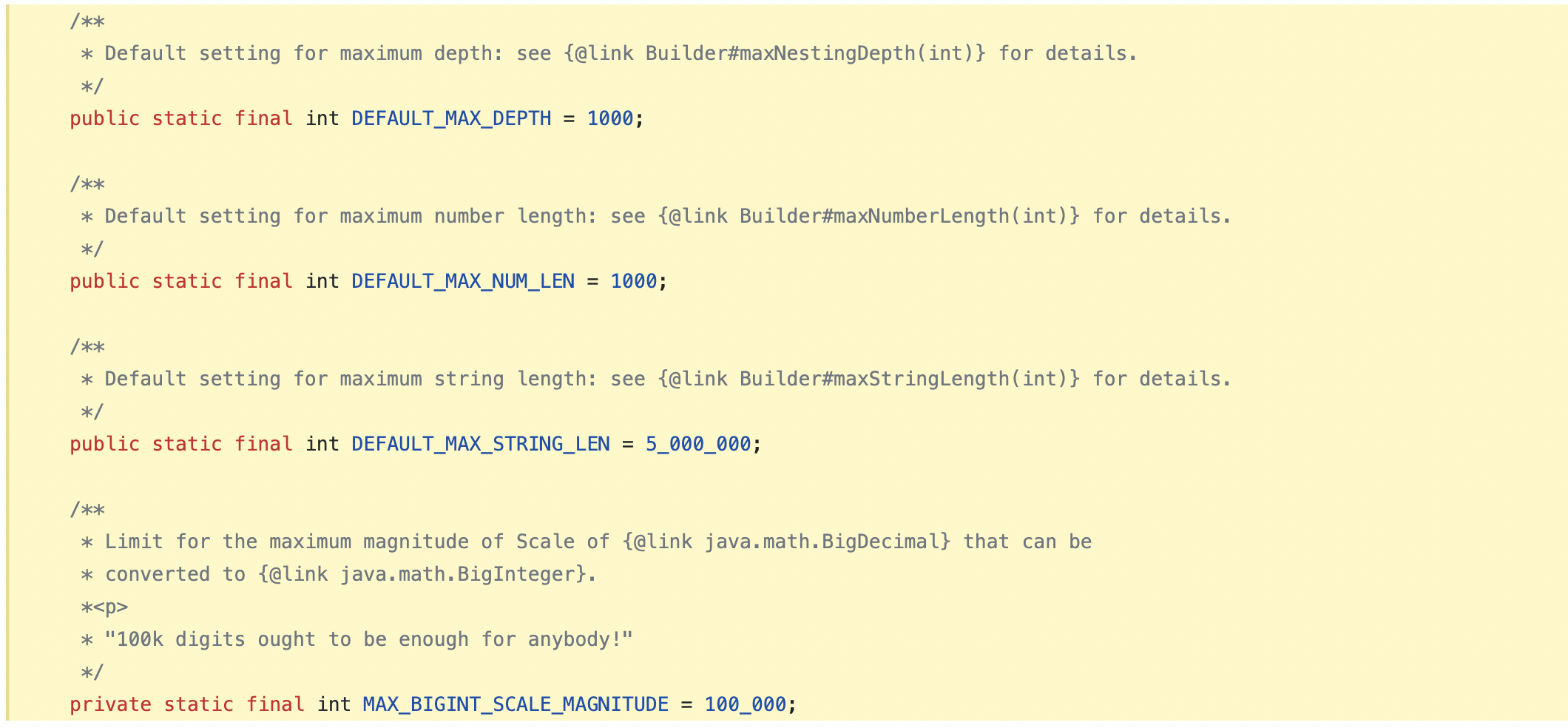
### What changes were proposed in this pull request? Upgrade FasterXML jackson from 2.14.2 to 2.15.0 ### Why are the changes needed? Upgrade Snakeyaml to 2.0 (resolves CVE-2022-1471 [CVE-2022-1471 at nist](https://nvd.nist.gov/vuln/detail/CVE-2022-1471) ### Does this PR introduce _any_ user-facing change? This PR introduces user-facing changes by implementing streaming read constraints in the JSONOptions class. The constraints limit the size of input constructs, improving security and efficiency when processing input data. Users working with JSON data larger than the following default settings may need to adjust the constraints accordingly: Maximum Number value length: 1000 characters (`DEFAULT_MAX_NUM_LEN`) Maximum String value length: 5,000,000 characters (`DEFAULT_MAX_STRING_LEN`) Maximum Nesting depth: 1000 levels (`DEFAULT_MAX_DEPTH`) Additionally, the maximum magnitude of scale for BigDecimal to BigInteger conversion is set to 100,000 digits (`MAX_BIGINT_SCALE_MAGNITUDE`) and cannot be changed. Users can customize the constraints as needed by providing the corresponding options in the parameters object. If not explicitly specified, default settings will be applied. ### How was this patch tested? Pass GA Closes apache#40933 from bjornjorgensen/test_jacon. Authored-by: bjornjorgensen <[email protected]> Signed-off-by: Sean Owen <[email protected]>
### _Why are the changes needed?_ spark bump jackson from 2.14.2 to 2.15.0 in apache/spark#40933 to fix https://github.com/apache/kyuubi/actions/runs/4943800010/jobs/8838642303 ``` Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 1.0 failed 1 times, most recent failure: Lost task 0.0 in stage 1.0 (TID 1) (localhost executor driver): java.lang.NoClassDefFoundError: com/fasterxml/jackson/core/StreamReadConstraints at org.apache.spark.sql.catalyst.json.JSONOptions.buildJsonFactory(JSONOptions.scala:195) at org.apache.spark.sql.catalyst.json.JsonInferSchema.$anonfun$infer$1(JsonInferSchema.scala:83) at org.apache.spark.rdd.RDD.$anonfun$mapPartitions$2(RDD.scala:855) at org.apache.spark.rdd.RDD.$anonfun$mapPartitions$2$adapted(RDD.scala:855) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:364) at org.apache.spark.rdd.RDD.iterator(RDD.scala:328) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:92) at org.apache.spark.TaskContext.runTaskWithListeners(TaskContext.scala:161) at org.apache.spark.scheduler.Task.run(Task.scala:139) at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:554) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1514) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:557) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:750) Caused by: java.lang.ClassNotFoundException: com.fasterxml.jackson.core.StreamReadConstraints at java.net.URLClassLoader.findClass(URLClassLoader.java:387) at java.lang.ClassLoader.loadClass(ClassLoader.java:418) at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:352) at java.lang.ClassLoader.loadClass(ClassLoader.java:351) ... 16 more ``` ### _How was this patch tested?_ - [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible - [ ] Add screenshots for manual tests if appropriate - [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request Closes #4824 from cfmcgrady/jackson-2.15.0. Closes #4824 7a8a3de [Fu Chen] update dev/dependencyList 2d01b4b [Fu Chen] bump jackson Authored-by: Fu Chen <[email protected]> Signed-off-by: liangbowen <[email protected]>
What changes were proposed in this pull request?
Upgrade FasterXML jackson from 2.14.2 to 2.15.0
Why are the changes needed?
Upgrade Snakeyaml to 2.0 (resolves CVE-2022-1471 CVE-2022-1471 at nist
Does this PR introduce any user-facing change?
This PR introduces user-facing changes by implementing streaming read constraints in the JSONOptions class. The constraints limit the size of input constructs, improving security and efficiency when processing input data.
Users working with JSON data larger than the following default settings may need to adjust the constraints accordingly:
Maximum Number value length: 1000 characters (
DEFAULT_MAX_NUM_LEN)Maximum String value length: 5,000,000 characters (
DEFAULT_MAX_STRING_LEN)Maximum Nesting depth: 1000 levels (
DEFAULT_MAX_DEPTH)Additionally, the maximum magnitude of scale for BigDecimal to BigInteger conversion is set to 100,000 digits (
MAX_BIGINT_SCALE_MAGNITUDE) and cannot be changed.Users can customize the constraints as needed by providing the corresponding options in the parameters object. If not explicitly specified, default settings will be applied.
How was this patch tested?
Pass GA