[SPARK-41858][SQL] Fix ORC reader perf regression due to DEFAULT value feature #39362
There are no files selected for viewing
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -1679,7 +1679,8 @@ class InsertSuite extends DataSourceTest with SharedSparkSession { | |
| Config( | ||
| None), | ||
| Config( | ||
| Some(SQLConf.ORC_VECTORIZED_READER_ENABLED.key -> "false"), | ||
| insertNullsToStorage = false))), | ||
| TestCase( | ||
| dataSource = "parquet", | ||
| Seq( | ||
|
|
@@ -1943,7 +1944,11 @@ class InsertSuite extends DataSourceTest with SharedSparkSession { | |
| Row(Seq(Row(1, 2)), Seq(Map(false -> "def", true -> "jkl"))), | ||
| Seq(Map(true -> "xyz"))), | ||
| Row(2, | ||
| if (config.dataSource != "orc") { | ||
|
Contributor
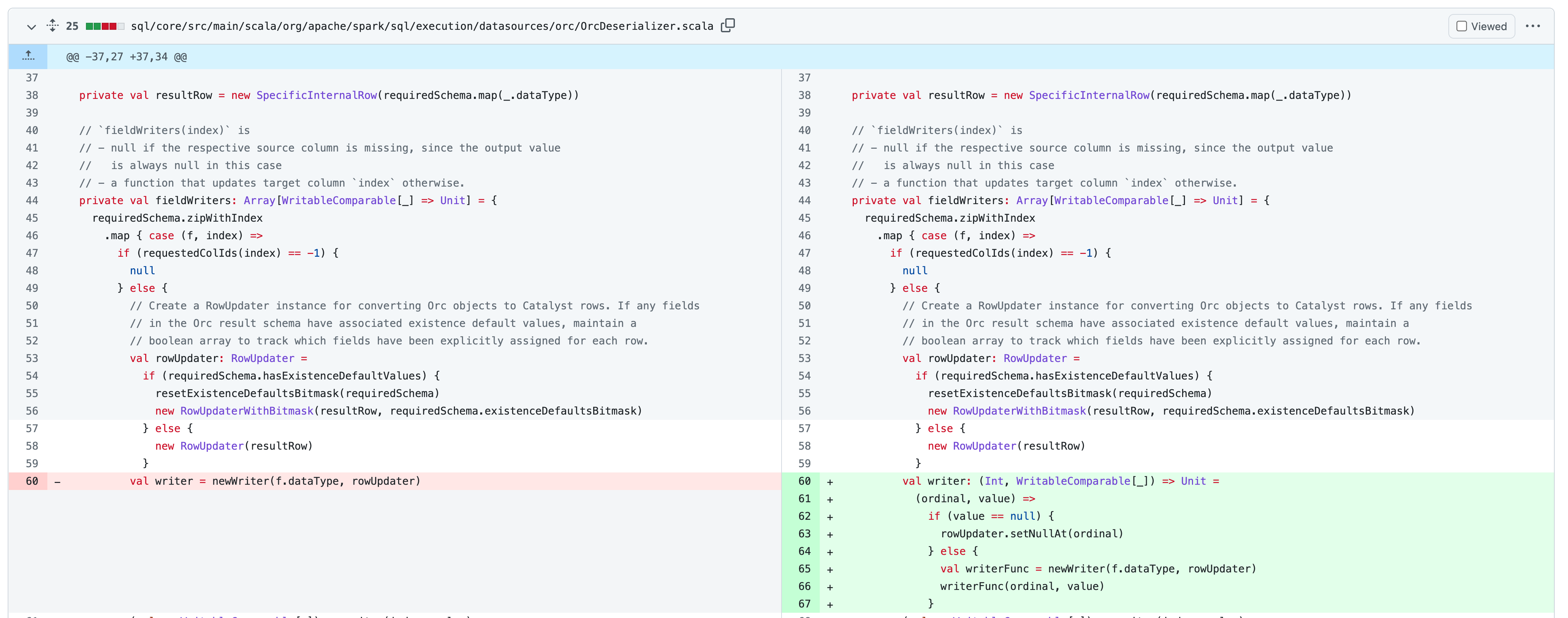
There was a problem hiding this comment. It looks like this PR breaks the DEFAULT value functionality for the Orc data source (as shown by this unit test). If anyone is using this functionality, this PR will make their results incorrect. It would be better if we can fix the performance regression without changing the behavior. Is there some profile to show why the performance regression takes place? For example, is it because this change to the writer function introduces a new level of function call?
Member
Author
There was a problem hiding this comment. Thank you for review, @dtenedor .
New feature is good as long as not breaking the old behavior.
Contributor
There was a problem hiding this comment.
Thanks @dongjoon-hyun for the benchmark! The Jira simply comprises the title
Agree on this. However, that bug fix was merged into Spark 3.3 on Jul. 28, 2022. Is it possible that users could have built pipelines since then using the new feature that would return incorrect results if we merged this PR?
Contributor
There was a problem hiding this comment. If someone can tell me how to run the benchmark, I can play around with a fix for the perf regression that also does not change the behavior. I suspect that it's due to the extra function call overhead that takes place each time a value is written, but not sure without a profile :)
Member
Author
There was a problem hiding this comment. Sorry, I copied a wrong link. Here is the exact link, @dtenedor .
Member
Author
There was a problem hiding this comment. Thanks, but I filed SPARK-41858 as the blocker of Apache Spark 3.4 because this really blocks Apache Spark 3.4 preparation from my side. If you don't mind, I'd prefer to merge this first and help you cleanly.
Contributor
There was a problem hiding this comment. @dongjoon-hyun that is OK, but we should probably not release Spark 3.4 with a correctness regression either. It is equally important as performance. If we create another Jira blocking the release of 3.4 that covers fixing the correctness bug, it is fine to merge this PR. At any rate, I am hoping to figure this out today. Then we should be unblocked 🤔
Member
Author
There was a problem hiding this comment. Thank you so much for your understanding. I'll file another blocker JIRA for that of course.
Contributor
There was a problem hiding this comment. LGTM, let's merge this then
Contributor
There was a problem hiding this comment. You can assign the new correctness Jira for me to fix. |
||
| null | ||
| } else { | ||
| Row(Seq(Row(1, 2)), Seq(Map(false -> "def", true -> "jkl"))) | ||
| }, | ||
| Seq(Map(true -> "xyz"))), | ||
| Row(3, | ||
| Row(Seq(Row(3, 4)), Seq(Map(false -> "mno", true -> "pqr"))), | ||
|
|
||
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
A little magical, let me do some investigate too