[SPARK-41683][CORE] Fix issue of getting incorrect property numActiveStages in jobs API#39190
[SPARK-41683][CORE] Fix issue of getting incorrect property numActiveStages in jobs API#39190kuwii wants to merge 3 commits intoapache:masterfrom
Conversation
|
Related Change: #22209 |
|
Can one of the admins verify this patch? |
|
+CC @thejdeep |
|
Kindly ping @ankuriitg @vanzin @mridulm @thejdeep |
|
Hi. this impacts Jobs API so this is a user facing change right? |
@VindhyaG Thanks for the comment. I've updated the PR description. |
|
Hi @srowen, could you please help to take a look at this PR? Thanks. |
|
It makes sense to me. I don't know a lot about this code, so hesitate to review it. Does this only affect display metrics? I'm just wondering why it hadn't caused a problem before. Maybe it's always been a cosmetic issue, that only arises when a job is cancelled with pending stages or something? |
|
Or maybe more to the point, do you have a concrete example of how this arises in Spark? |
|
@srowen We found this issue in some of Spark applications. Here's the event log of an example, which can be loaded through history server: In |
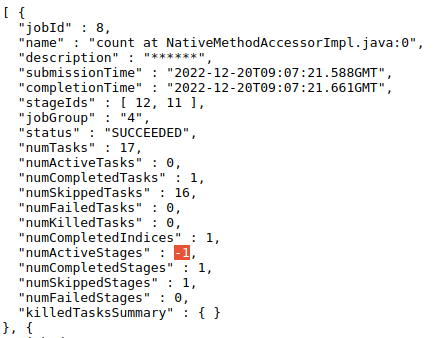
|
Yeah but do you know how it happens, or have a theory? Just want to see if the change seems to match with some theory of how it arises. Or does this change definitely change the output above? |
|
I'm not familiar with how Spark creates and runs jobs and stages for a query, but I think it may be related to this case. I can reproduce this locally using Spark on Yarn mode with this code: from pyspark import SparkConf, SparkContext
from pyspark.sql import SQLContext
from pyspark.sql.functions import countDistinct, col, count, when
import time
conf = SparkConf().setAppName('test')
sc = SparkContext(conf = conf)
spark = SQLContext(sc).sparkSession
spark.range(1, 100).count()The execution for
Because of some logic, stage 1 will always be skipped, not even submitted.
This is the case that is mentioned in the PR's description. And because the incorrect logic of updating
|
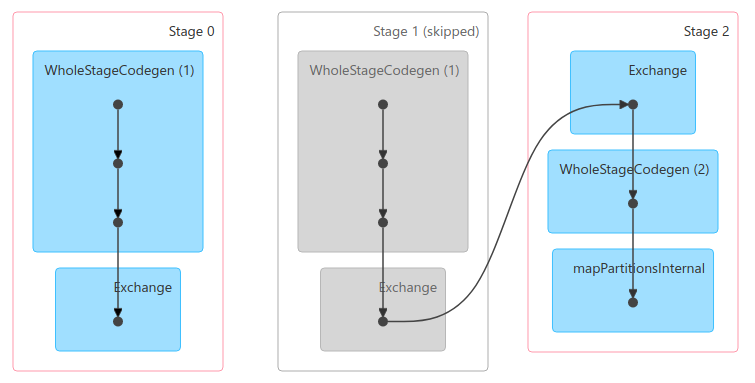
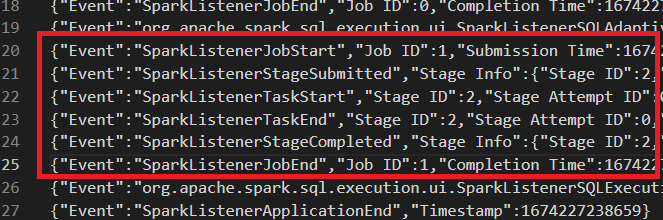
|
FWIW, this part was last changed in https://issues.apache.org/jira/browse/SPARK-24415 to fix a different bug (CC @ankuriitg ) It might be worth re-running the simple example there to see if this retains the 'fix', but, evidently the tests added in that old change still pass here. While I'm always wary of touching this core code and I myself don't know it well, this seems fairly convincing. |
|
Tried the example code in the JIRA, and it is not affected by this change. Tasks showed in the stage are the same before and after this change.
Also,
I've checked comments about these lines in that PR. Code here is for handling stages metrics when
|


|
Merged to master |
What changes were proposed in this pull request?
onJobEndmethod ofAppStatusListener, removing the logic of reducingjob.activeStagesfor each pending stage.numActiveStagesof jobs data is correct.Why are the changes needed?
For property
activeStagesofLiveJob, it is updated when:activeStages = 0activeStages += 1activeStages -= 1activeStages -= 1for each pending stagesAccording to the implementation of
AppStatusListenerandLiveStage:activeStages.activeStagesincreased by1.So for pending stages, they won't affect
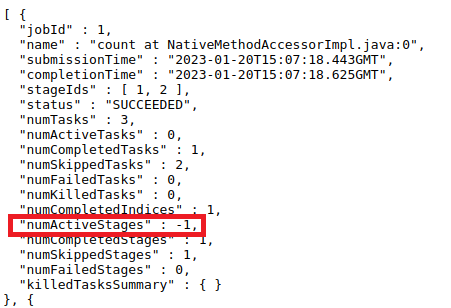
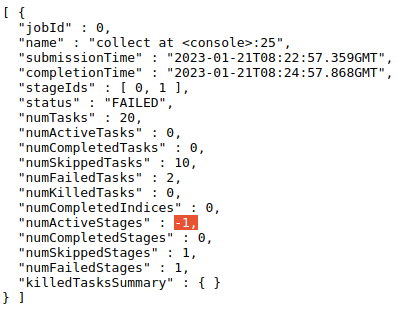
activeStages. Therefore, when job is ended,activeStagesshouldn't be decreased by1for each pending stage.Here's an example:
In this case, when job 0 ends, its
numActiveStageswill be-2, which is obviously incorrect.Does this PR introduce any user-facing change?
For jobs API, property
activeStageswill be different if a job has pending stages when it ends. In these cases, previously the number is incorrect. This PR fixes it.How was this patch tested?
This PR adds a UT of the example mentioned above, to make sure
numActiveStagesshould be0instead of-2.