[SPARK-39203][SQL] Rewrite table location to absolute URI based on database URI #36625
Conversation
65c1957 to
451e550
Compare
There was a problem hiding this comment.
table.storage.locationUri is the table location, not database location, isn't it?
There was a problem hiding this comment.
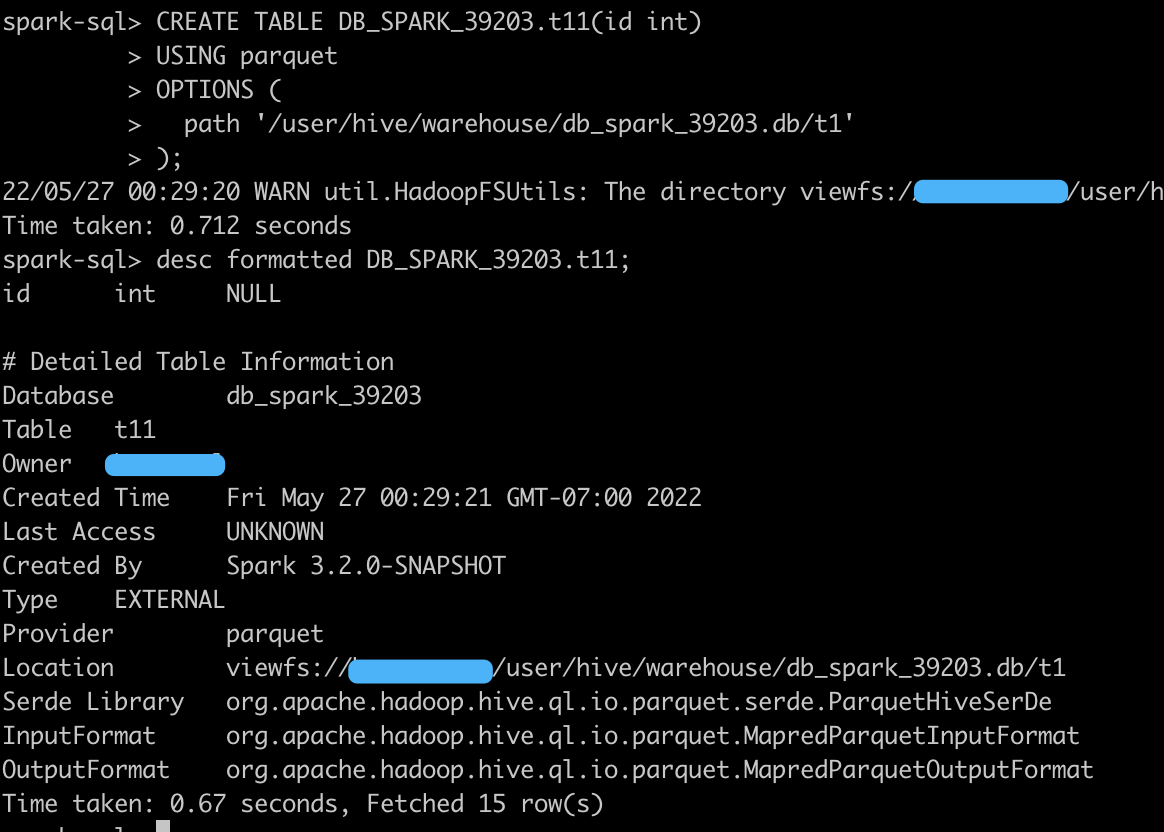
The table location uri has been rewritten by HiveClientImpl.convertHiveTableToCatalogTable.
For example:
table.storage.locationUri: Some(viewfs://clusterA/user/hive/warehouse/db_spark_39203.db/t1)
loc: /user/hive/warehouse/db_spark_39203.db/t1
There was a problem hiding this comment.
Sorry I don't understand. The previous code completely ignores table.storage.locationUri. Do you mean we still don't care about table.storage.locationUri, but only want to get its qualifier (scheme, host, port, etc.)?
There was a problem hiding this comment.
Yes. We only rewrite table.storage.locationUri once with HiveClientImpl.convertHiveTableToCatalogTable. Then use the rewritten uri to rewrite the other location uri: CaseInsensitiveMap(table.storage.properties).get("path"), the partition location.
There was a problem hiding this comment.
It seems to be that it's clearer to get database location in HiveExternalCatalog.restoreDataSourceTable and do not change HiveClientImpl at all.
There was a problem hiding this comment.
It can't handle all cases. For example rawTable's location is incorrect:
spark/sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveExternalCatalog.scala
Lines 1283 to 1289 in 4df8512
This makes fromHivePartition can't correct the partition location:
There was a problem hiding this comment.
for tables created by recent versions of Spark, this condition is always true?
There was a problem hiding this comment.
spark-sql>
> CREATE TABLE DB_SPARK_39203.t7(id int) using parquet;
Time taken: 0.43 seconds
spark-sql>
> CREATE TABLE DB_SPARK_39203.t8(id int)
> stored as parquet
> LOCATION '/user/hive/warehouse/db_spark_39203.db/t1';
Time taken: 0.265 seconds
spark-sql>
> CREATE EXTERNAL TABLE DB_SPARK_39203.t9(id int)
> stored as parquet
> LOCATION '/user/hive/warehouse/db_spark_39203.db/t1';
Time taken: 0.278 seconds
spark-sql> desc formatted DB_SPARK_39203.t7;
id int NULL
# Detailed Table Information
Database db_spark_39203
Table t7
Owner ####
Created Time Fri May 27 00:31:09 GMT-07:00 2022
Last Access UNKNOWN
Created By Spark 3.2.0-SNAPSHOT
Type MANAGED
Provider parquet
Location viewfs://####/user/hive/warehouse/db_spark_39203.db/t7
Serde Library org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe
InputFormat org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat
OutputFormat org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat
Time taken: 0.152 seconds, Fetched 15 row(s)
spark-sql> desc formatted DB_SPARK_39203.t8;
id int NULL
# Detailed Table Information
Database db_spark_39203
Table t8
Owner ####
Created Time Fri May 27 00:31:09 GMT-07:00 2022
Last Access UNKNOWN
Created By Spark 3.2.0-SNAPSHOT
Type EXTERNAL
Provider hive
Table Properties [transient_lastDdlTime=1653636669]
Location viewfs://####/user/hive/warehouse/db_spark_39203.db/t1
Serde Library org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe
InputFormat org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat
OutputFormat org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat
Storage Properties [serialization.format=1]
Partition Provider Catalog
Time taken: 0.224 seconds, Fetched 18 row(s)
spark-sql> desc formatted DB_SPARK_39203.t9;
id int NULL
# Detailed Table Information
Database db_spark_39203
Table t9
Owner ####
Created Time Fri May 27 00:31:10 GMT-07:00 2022
Last Access UNKNOWN
Created By Spark 3.2.0-SNAPSHOT
Type EXTERNAL
Provider hive
Table Properties [transient_lastDdlTime=1653636670]
Location viewfs://####/user/hive/warehouse/db_spark_39203.db/t1
Serde Library org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe
InputFormat org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat
OutputFormat org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat
Storage Properties [serialization.format=1]
Partition Provider Catalog
Time taken: 0.142 seconds, Fetched 18 row(s)
There was a problem hiding this comment.
shoudn't this be CatalogUtils.stringToURI(client.getDatabase(h.getDbName).getLocationUri)?
There was a problem hiding this comment.
nit:
if (!uri.isAbsolute && parentUri.isDefined) {
new URI...
} else {
uri
}
There was a problem hiding this comment.
I think the name parentUri is a bit misleading. It's more like an absoluteUri which we need to inherit its schema, host, port, etc.
There was a problem hiding this comment.
Renamed it to absoluteUri.
[info] - 0.12: getPartitionNames(catalogTable) (74 milliseconds) [info] org.apache.spark.sql.hive.client.HiveClientSuites *** ABORTED *** (13 seconds, 434 milliseconds) [info] java.lang.NoSuchMethodError: org.apache.hadoop.hive.ql.metadata.Table.getDataLocation()Lorg/apache/hadoop/fs/Path; [info] at org.apache.spark.sql.hive.client.HiveClientImpl.$anonfun$getPartitions$3(HiveClientImpl.scala:765)
| storage = CatalogStorageFormat( | ||
| locationUri = shim.getDataLocation(h).map(CatalogUtils.stringToURI), | ||
| locationUri = shim.getDataLocation(h).map { loc => | ||
| val tableUri = stringToURI(loc) |
There was a problem hiding this comment.
can we add some code comments to explain this backward compatibility story?
| val absoluteUri = shim.getDataLocation(hiveTable).map(stringToURI).filter(!_.isAbsolute) | ||
| .map(_ => stringToURI(client.getDatabase(hiveTable.getDbName).getLocationUri)) | ||
| val parts = shim.getPartitions(client, hiveTable, partSpec.asJava) | ||
| .map(fromHivePartition(_, absoluteUri)) |
There was a problem hiding this comment.
does this mean we always calculate the absoluteUri even if the partition uri is absolute?
There was a problem hiding this comment.
No. the absoluteUri is None if table location is absolute uri.
| val storageWithLocation = { | ||
| val tableLocation = getLocationFromStorageProps(table) | ||
| val tableLocation = getLocationFromStorageProps(table).map { path => | ||
| toAbsoluteURI(CatalogUtils.stringToURI(path), table.storage.locationUri) |
There was a problem hiding this comment.
ditto, let's explain the backward compatibility story with code comments.
|
Merged to master. |
### What changes were proposed in this pull request? This fixes a corner-case regression caused by #36625. Users may have existing views that have invalid locations due to historical reasons. The location is actually useless for a view, but after #36625 , they start to fail to read the view as qualifying the location fails. We should just skip qualifying view locations. ### Why are the changes needed? avoid regression ### Does this PR introduce _any_ user-facing change? Spark can read view with invalid location again. ### How was this patch tested? manually test. View with an invalid location is kind of "broken" and can't be dropped (HMS fails to drop it), so we can't write a UT for it. Closes #38321 from cloud-fan/follow. Authored-by: Wenchen Fan <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]>
### What changes were proposed in this pull request? This fixes a corner-case regression caused by apache#36625. Users may have existing views that have invalid locations due to historical reasons. The location is actually useless for a view, but after apache#36625 , they start to fail to read the view as qualifying the location fails. We should just skip qualifying view locations. ### Why are the changes needed? avoid regression ### Does this PR introduce _any_ user-facing change? Spark can read view with invalid location again. ### How was this patch tested? manually test. View with an invalid location is kind of "broken" and can't be dropped (HMS fails to drop it), so we can't write a UT for it. Closes apache#38321 from cloud-fan/follow. Authored-by: Wenchen Fan <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]>
…d on database URI ### What changes were proposed in this pull request? This reverts #36625 and its followup #38321 . ### Why are the changes needed? External table location can be arbitrary and has no connection with the database location. It can be wrong to qualify the external table location based on the database location. If a table written by old Spark versions does not have a qualified location, there is no way to restore it as the information is already lost. People can manually fix the table locations assuming they are under the same HDFS cluster with the database location, by themselves. ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? N/A Closes #40871 from cloud-fan/minor. Authored-by: Wenchen Fan <[email protected]> Signed-off-by: Hyukjin Kwon <[email protected]>
…d on database URI ### What changes were proposed in this pull request? This reverts #36625 and its followup #38321 . ### Why are the changes needed? External table location can be arbitrary and has no connection with the database location. It can be wrong to qualify the external table location based on the database location. If a table written by old Spark versions does not have a qualified location, there is no way to restore it as the information is already lost. People can manually fix the table locations assuming they are under the same HDFS cluster with the database location, by themselves. ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? N/A Closes #40871 from cloud-fan/minor. Authored-by: Wenchen Fan <[email protected]> Signed-off-by: Hyukjin Kwon <[email protected]> (cherry picked from commit afd9e2c) Signed-off-by: Hyukjin Kwon <[email protected]>
…d on database URI ### What changes were proposed in this pull request? This reverts apache#36625 and its followup apache#38321 . ### Why are the changes needed? External table location can be arbitrary and has no connection with the database location. It can be wrong to qualify the external table location based on the database location. If a table written by old Spark versions does not have a qualified location, there is no way to restore it as the information is already lost. People can manually fix the table locations assuming they are under the same HDFS cluster with the database location, by themselves. ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? N/A Closes apache#40871 from cloud-fan/minor. Authored-by: Wenchen Fan <[email protected]> Signed-off-by: Hyukjin Kwon <[email protected]> (cherry picked from commit afd9e2c) Signed-off-by: Hyukjin Kwon <[email protected]>
…d on database URI ### What changes were proposed in this pull request? This reverts apache#36625 and its followup apache#38321 . ### Why are the changes needed? External table location can be arbitrary and has no connection with the database location. It can be wrong to qualify the external table location based on the database location. If a table written by old Spark versions does not have a qualified location, there is no way to restore it as the information is already lost. People can manually fix the table locations assuming they are under the same HDFS cluster with the database location, by themselves. ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? N/A Closes apache#40871 from cloud-fan/minor. Authored-by: Wenchen Fan <[email protected]> Signed-off-by: Hyukjin Kwon <[email protected]> (cherry picked from commit afd9e2c) Signed-off-by: Hyukjin Kwon <[email protected]>
…d on database URI ### What changes were proposed in this pull request? This reverts apache#36625 and its followup apache#38321 . ### Why are the changes needed? External table location can be arbitrary and has no connection with the database location. It can be wrong to qualify the external table location based on the database location. If a table written by old Spark versions does not have a qualified location, there is no way to restore it as the information is already lost. People can manually fix the table locations assuming they are under the same HDFS cluster with the database location, by themselves. ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? N/A Closes apache#40871 from cloud-fan/minor. Authored-by: Wenchen Fan <[email protected]> Signed-off-by: Hyukjin Kwon <[email protected]> (cherry picked from commit afd9e2c) Signed-off-by: Hyukjin Kwon <[email protected]>
What changes were proposed in this pull request?
Rewrite table location to absolute location based on database location. For example:
The current table location is:
viewfs://clusterA/user/hive/warehouse/db_spark_39203.db/t1.Why are the changes needed?
The old Spark version(before SPARK-19257) will not use absolute path when using the following SQL create table:
This issue makes Spark can't read tables across cluster. For example:
Hive, Spark 2.1 and HDFS 1 on cluster A.
Spark 3.0 and HDFS 2 on cluster B.
The other create table command and latest spark do not have this issue:
Does this PR introduce any user-facing change?
No.
How was this patch tested?
Unit test and production test: we have been using this patch for over two years.