[SPARK-34289][SQL] Parquet vectorized reader support column index #31393
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
|
Test build #134645 has started for PR 31393 at commit |
|
Kubernetes integration test starting |
|
Refer to this link for build results (access rights to CI server needed): |
|
Refer to this link for build results (access rights to CI server needed): |
Member
Author
|
Benchmark and benchmark result: /*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.sql.execution.benchmark
import java.io.File
import scala.util.Random
import org.apache.parquet.hadoop.ParquetInputFormat
import org.apache.spark.SparkConf
import org.apache.spark.benchmark.Benchmark
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions.{monotonically_increasing_id, timestamp_seconds}
import org.apache.spark.sql.internal.SQLConf
import org.apache.spark.sql.internal.SQLConf.ParquetOutputTimestampType
import org.apache.spark.sql.types.{ByteType, Decimal, DecimalType}
/**
* Benchmark to measure read performance with Parquet column index.
* To run this benchmark:
* {{{
* 1. without sbt: bin/spark-submit --class <this class> <spark sql test jar>
* 2. build/sbt "sql/test:runMain <this class>"
* 3. generate result: SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain <this class>"
* Results will be written to "benchmarks/ParquetFilterPushdownBenchmark-results.txt".
* }}}
*/
object ParquetColumnIndexBenchmark extends SqlBasedBenchmark {
override def getSparkSession: SparkSession = {
val conf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
// Since `spark.master` always exists, overrides this value
.set("spark.master", "local[1]")
.setIfMissing("spark.driver.memory", "3g")
.setIfMissing("spark.executor.memory", "3g")
.setIfMissing("orc.compression", "snappy")
.setIfMissing("spark.sql.parquet.compression.codec", "snappy")
SparkSession.builder().config(conf).getOrCreate()
}
private val numRows = 1024 * 1024 * 15
private val width = 5
private val mid = numRows / 2
def withTempTable(tableNames: String*)(f: => Unit): Unit = {
try f finally tableNames.foreach(spark.catalog.dropTempView)
}
private def prepareTable(
dir: File, numRows: Int, width: Int, useStringForValue: Boolean): Unit = {
import spark.implicits._
val selectExpr = (1 to width).map(i => s"CAST(value AS STRING) c$i")
val valueCol = if (useStringForValue) {
monotonically_increasing_id().cast("string")
} else {
monotonically_increasing_id()
}
val df = spark.range(numRows).map(_ => Random.nextLong).selectExpr(selectExpr: _*)
.withColumn("value", valueCol)
.sort("value")
saveAsTable(df, dir)
}
private def prepareStringDictTable(
dir: File, numRows: Int, numDistinctValues: Int, width: Int): Unit = {
val selectExpr = (0 to width).map {
case 0 => s"CAST(id % $numDistinctValues AS STRING) AS value"
case i => s"CAST(rand() AS STRING) c$i"
}
val df = spark.range(numRows).selectExpr(selectExpr: _*).sort("value")
saveAsTable(df, dir, true)
}
private def saveAsTable(df: DataFrame, dir: File, useDictionary: Boolean = false): Unit = {
val parquetPath = dir.getCanonicalPath + "/parquet"
df.write.mode("overwrite").parquet(parquetPath)
spark.read.parquet(parquetPath).createOrReplaceTempView("parquetTable")
}
def filterPushDownBenchmark(
values: Int,
title: String,
whereExpr: String,
selectExpr: String = "*"): Unit = {
val benchmark = new Benchmark(title, values, minNumIters = 5, output = output)
Seq(false, true).foreach { columnIndexEnabled =>
val name = s"Parquet Vectorized ${if (columnIndexEnabled) s"(columnIndex)" else ""}"
benchmark.addCase(name) { _ =>
withSQLConf(ParquetInputFormat.COLUMN_INDEX_FILTERING_ENABLED -> s"$columnIndexEnabled") {
spark.sql(s"SELECT $selectExpr FROM parquetTable WHERE $whereExpr").noop()
}
}
}
benchmark.run()
}
private def runIntBenchmark(numRows: Int, width: Int, mid: Int): Unit = {
Seq("value IS NULL", s"$mid < value AND value < $mid").foreach { whereExpr =>
val title = s"Select 0 int row ($whereExpr)".replace("value AND value", "value")
filterPushDownBenchmark(numRows, title, whereExpr)
}
Seq(
s"value = $mid",
s"value <=> $mid",
s"$mid <= value AND value <= $mid",
s"${mid - 1} < value AND value < ${mid + 1}"
).foreach { whereExpr =>
val title = s"Select 1 int row ($whereExpr)".replace("value AND value", "value")
filterPushDownBenchmark(numRows, title, whereExpr)
}
val selectExpr = (1 to width).map(i => s"MAX(c$i)").mkString("", ",", ", MAX(value)")
Seq(10, 50, 90).foreach { percent =>
filterPushDownBenchmark(
numRows,
s"Select $percent% int rows (value < ${numRows * percent / 100})",
s"value < ${numRows * percent / 100}",
selectExpr
)
}
Seq("value IS NOT NULL", "value > -1", "value != -1").foreach { whereExpr =>
filterPushDownBenchmark(
numRows,
s"Select all int rows ($whereExpr)",
whereExpr,
selectExpr)
}
}
private def runStringBenchmark(
numRows: Int, width: Int, searchValue: Int, colType: String): Unit = {
Seq("value IS NULL", s"'$searchValue' < value AND value < '$searchValue'")
.foreach { whereExpr =>
val title = s"Select 0 $colType row ($whereExpr)".replace("value AND value", "value")
filterPushDownBenchmark(numRows, title, whereExpr)
}
Seq(
s"value = '$searchValue'",
s"value <=> '$searchValue'",
s"'$searchValue' <= value AND value <= '$searchValue'"
).foreach { whereExpr =>
val title = s"Select 1 $colType row ($whereExpr)".replace("value AND value", "value")
filterPushDownBenchmark(numRows, title, whereExpr)
}
val selectExpr = (1 to width).map(i => s"MAX(c$i)").mkString("", ",", ", MAX(value)")
Seq("value IS NOT NULL").foreach { whereExpr =>
filterPushDownBenchmark(
numRows,
s"Select all $colType rows ($whereExpr)",
whereExpr,
selectExpr)
}
}
override def runBenchmarkSuite(mainArgs: Array[String]): Unit = {
runBenchmark("Pushdown for many distinct value case") {
withTempPath { dir =>
withTempTable("parquetTable") {
Seq(true, false).foreach { useStringForValue =>
prepareTable(dir, numRows, width, useStringForValue)
if (useStringForValue) {
runStringBenchmark(numRows, width, mid, "string")
} else {
runIntBenchmark(numRows, width, mid)
}
}
}
}
}
runBenchmark("Pushdown for few distinct value case (use dictionary encoding)") {
withTempPath { dir =>
val numDistinctValues = 200
withTempTable("parquetTable") {
prepareStringDictTable(dir, numRows, numDistinctValues, width)
runStringBenchmark(numRows, width, numDistinctValues / 2, "distinct string")
}
}
}
runBenchmark("Pushdown benchmark for StringStartsWith") {
withTempPath { dir =>
withTempTable("parquetTable") {
prepareTable(dir, numRows, width, true)
Seq(
"value like '10%'",
"value like '1000%'",
s"value like '${mid.toString.substring(0, mid.toString.length - 1)}%'"
).foreach { whereExpr =>
val title = s"StringStartsWith filter: ($whereExpr)"
filterPushDownBenchmark(numRows, title, whereExpr)
}
}
}
}
runBenchmark(s"Pushdown benchmark for ${DecimalType.simpleString}") {
withTempPath { dir =>
Seq(
s"decimal(${Decimal.MAX_INT_DIGITS}, 2)",
s"decimal(${Decimal.MAX_LONG_DIGITS}, 2)",
s"decimal(${DecimalType.MAX_PRECISION}, 2)"
).foreach { dt =>
val columns = (1 to width).map(i => s"CAST(id AS string) c$i")
val valueCol = if (dt.equalsIgnoreCase(s"decimal(${Decimal.MAX_INT_DIGITS}, 2)")) {
monotonically_increasing_id() % 9999999
} else {
monotonically_increasing_id()
}
val df = spark.range(numRows)
.selectExpr(columns: _*).withColumn("value", valueCol.cast(dt))
withTempTable("parquetTable") {
saveAsTable(df, dir)
Seq(s"value = $mid").foreach { whereExpr =>
val title = s"Select 1 $dt row ($whereExpr)".replace("value AND value", "value")
filterPushDownBenchmark(numRows, title, whereExpr)
}
val selectExpr = (1 to width).map(i => s"MAX(c$i)").mkString("", ",", ", MAX(value)")
Seq(10, 50, 90).foreach { percent =>
filterPushDownBenchmark(
numRows,
s"Select $percent% $dt rows (value < ${numRows * percent / 100})",
s"value < ${numRows * percent / 100}",
selectExpr
)
}
}
}
}
}
runBenchmark("Pushdown benchmark for InSet -> InFilters") {
withTempPath { dir =>
withTempTable("parquetTable") {
prepareTable(dir, numRows, width, false)
Seq(5, 10, 50, 100).foreach { count =>
Seq(10, 50, 90).foreach { distribution =>
val filter =
Range(0, count).map(r => scala.util.Random.nextInt(numRows * distribution / 100))
val whereExpr = s"value in(${filter.mkString(",")})"
val title = s"InSet -> InFilters (values count: $count, distribution: $distribution)"
filterPushDownBenchmark(numRows, title, whereExpr)
}
}
}
}
}
runBenchmark(s"Pushdown benchmark for ${ByteType.simpleString}") {
withTempPath { dir =>
val columns = (1 to width).map(i => s"CAST(id AS string) c$i")
val df = spark.range(numRows).selectExpr(columns: _*)
.withColumn("value", (monotonically_increasing_id() % Byte.MaxValue).cast(ByteType))
.orderBy("value")
withTempTable("parquetTable") {
saveAsTable(df, dir)
Seq(s"value = CAST(${Byte.MaxValue / 2} AS ${ByteType.simpleString})")
.foreach { whereExpr =>
val title = s"Select 1 ${ByteType.simpleString} row ($whereExpr)"
.replace("value AND value", "value")
filterPushDownBenchmark(numRows, title, whereExpr)
}
val selectExpr = (1 to width).map(i => s"MAX(c$i)").mkString("", ",", ", MAX(value)")
Seq(10, 50, 90).foreach { percent =>
filterPushDownBenchmark(
numRows,
s"Select $percent% ${ByteType.simpleString} rows " +
s"(value < CAST(${Byte.MaxValue * percent / 100} AS ${ByteType.simpleString}))",
s"value < CAST(${Byte.MaxValue * percent / 100} AS ${ByteType.simpleString})",
selectExpr
)
}
}
}
}
runBenchmark(s"Pushdown benchmark for Timestamp") {
withTempPath { dir =>
withSQLConf(SQLConf.PARQUET_FILTER_PUSHDOWN_TIMESTAMP_ENABLED.key -> true.toString) {
ParquetOutputTimestampType.values.toSeq.map(_.toString).foreach { fileType =>
withSQLConf(SQLConf.PARQUET_OUTPUT_TIMESTAMP_TYPE.key -> fileType) {
val columns = (1 to width).map(i => s"CAST(id AS string) c$i")
val df = spark.range(numRows).selectExpr(columns: _*)
.withColumn("value", timestamp_seconds(monotonically_increasing_id()))
withTempTable("parquetTable") {
saveAsTable(df, dir)
Seq(s"value = timestamp_seconds($mid)").foreach { whereExpr =>
val title = s"Select 1 timestamp stored as $fileType row ($whereExpr)"
.replace("value AND value", "value")
filterPushDownBenchmark(numRows, title, whereExpr)
}
val selectExpr = (1 to width)
.map(i => s"MAX(c$i)").mkString("", ",", ", MAX(value)")
Seq(10, 50, 90).foreach { percent =>
filterPushDownBenchmark(
numRows,
s"Select $percent% timestamp stored as $fileType rows " +
s"(value < timestamp_seconds(${numRows * percent / 100}))",
s"value < timestamp_seconds(${numRows * percent / 100})",
selectExpr
)
}
}
}
}
}
}
}
runBenchmark(s"Pushdown benchmark with many filters") {
val numRows = 1
val width = 500
withTempPath { dir =>
val columns = (1 to width).map(i => s"id c$i")
val df = spark.range(1).selectExpr(columns: _*)
withTempTable("parquetTable") {
saveAsTable(df, dir)
Seq(1, 250, 500).foreach { numFilter =>
val whereExpr = (1 to numFilter).map(i => s"c$i = 0").mkString(" and ")
// Note: InferFiltersFromConstraints will add more filters to this given filters
filterPushDownBenchmark(numRows, s"Select 1 row with $numFilter filters", whereExpr)
}
}
}
}
}
}
|
Member
dongjoon-hyun
approved these changes
Jan 29, 2021
Member
 dongjoon-hyun
left a comment
dongjoon-hyun
left a comment
There was a problem hiding this comment.
+1, LGTM. Thank you, @wangyum .
Merged to master for Apache Spark 3.2.0.
cc @rdblue and @gatorsmile
a0x8o
added a commit
to a0x8o/spark
that referenced
this pull request
Jan 29, 2021
### What changes were proposed in this pull request? This pr make parquet vectorized reader support [column index](https://issues.apache.org/jira/browse/PARQUET-1201). ### Why are the changes needed? Improve filter performance. for example: `id = 1`, we only need to read `page-0` in `block 1`: ``` block 1: null count min max page-0 0 0 99 page-1 0 100 199 page-2 0 200 299 page-3 0 300 399 page-4 0 400 449 block 2: null count min max page-0 0 450 549 page-1 0 550 649 page-2 0 650 749 page-3 0 750 849 page-4 0 850 899 ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Unit test and benchmark: apache/spark#31393 (comment) Closes #31393 from wangyum/SPARK-34289. Authored-by: Yuming Wang <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]>
|
Nice work! |
Member
Author
|
Benchmark with production data: CREATE TABLE test11.benchmark_column_index_2 using parquet
CLUSTERED BY (FDBK_RCVR_USER_ID) SORTED BY (FDBK_GIVER_USER_ID) into 2000 buckets
AS
(SELECT * FROM test11.origin_data);
SELECT col... FROM test11.benchmark_column_index_2 WHERE FDBK_GIVER_USER_ID = 992647107 AND ...
|
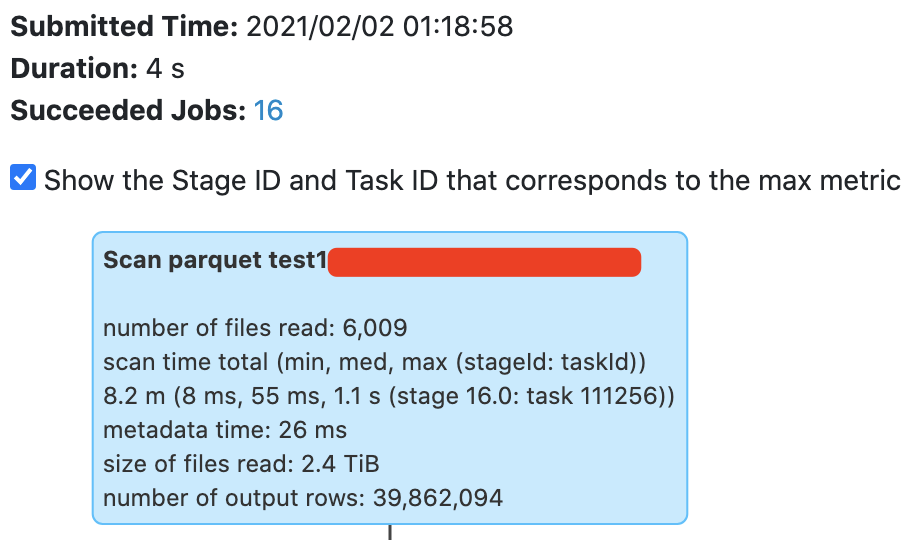
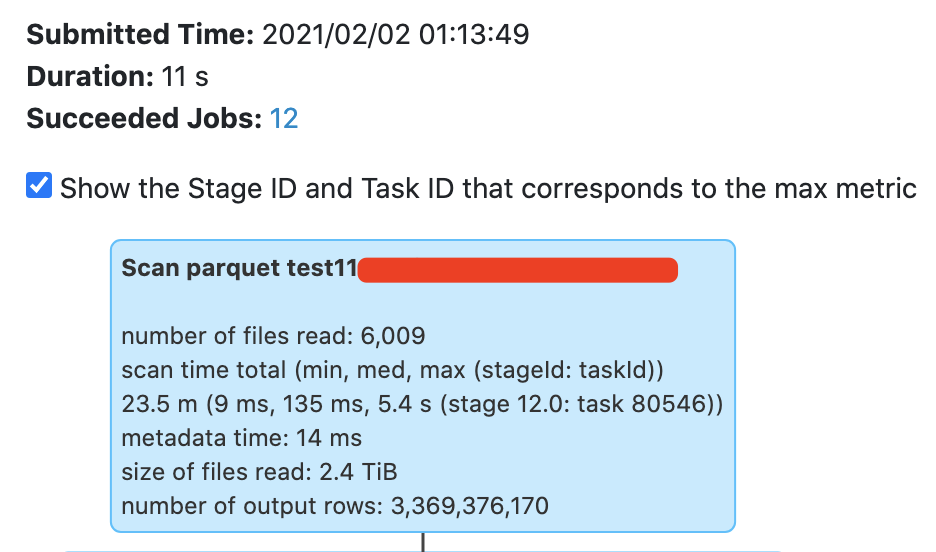
skestle
pushed a commit
to skestle/spark
that referenced
this pull request
Feb 3, 2021
### What changes were proposed in this pull request? This pr make parquet vectorized reader support [column index](https://issues.apache.org/jira/browse/PARQUET-1201). ### Why are the changes needed? Improve filter performance. for example: `id = 1`, we only need to read `page-0` in `block 1`: ``` block 1: null count min max page-0 0 0 99 page-1 0 100 199 page-2 0 200 299 page-3 0 300 399 page-4 0 400 449 block 2: null count min max page-0 0 450 549 page-1 0 550 649 page-2 0 650 749 page-3 0 750 849 page-4 0 850 899 ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Unit test and benchmark: apache#31393 (comment) Closes apache#31393 from wangyum/SPARK-34289. Authored-by: Yuming Wang <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]>
dongjoon-hyun
pushed a commit
that referenced
this pull request
Jun 30, 2021
…reader
### What changes were proposed in this pull request?
Make the current vectorized Parquet reader to work with column index introduced in Parquet 1.11. In particular, this PR makes the following changes:
1. in `ParquetReadState`, track row ranges returned via `PageReadStore.getRowIndexes` as well as the first row index for each page via `DataPage.getFirstRowIndex`.
1. introduced a new API `ParquetVectorUpdater.skipValues` which skips a batch of values from a Parquet value reader. As part of the process also renamed existing `updateBatch` to `readValues`, and `update` to `readValue` to keep the method names consistent.
1. in correspondence as above, also introduced new API `VectorizedValuesReader.skipXXX` for different data types, as well as the implementations. These are useful when the reader knows that the given batch of values can be skipped, for instance, due to the batch is not covered in the row ranges generated by column index filtering.
2. changed `VectorizedRleValuesReader` to handle column index filtering. This is done by comparing the range that is going to be read next within the current RLE/PACKED block (let's call this block range), against the current row range. There are three cases:
* if the block range is before the current row range, skip all the values in the block range
* if the block range is after the current row range, advance the row range and repeat the steps
* if the block range overlaps with the current row range, only read the values within the overlapping area and skip the rest.
### Why are the changes needed?
[Parquet Column Index](https://github.com/apache/parquet-format/blob/master/PageIndex.md) is a new feature in Parquet 1.11 which allows very efficient filtering on page level (some benchmark numbers can be found [here](https://blog.cloudera.com/speeding-up-select-queries-with-parquet-page-indexes/)), especially when data is sorted. The feature is largely implemented in parquet-mr (via classes such as `ColumnIndex` and `ColumnIndexFilter`). In Spark, the non-vectorized Parquet reader can automatically benefit from the feature after upgrading to Parquet 1.11.x, without any code change. However, the same is not true for vectorized Parquet reader since Spark chose to implement its own logic such as reading Parquet pages, handling definition levels, reading values into columnar batches, etc.
Previously, [SPARK-26345](https://issues.apache.org/jira/browse/SPARK-26345) / (#31393) updated Spark to only scan pages filtered by column index from parquet-mr side. This is done by calling `ParquetFileReader.readNextFilteredRowGroup` and `ParquetFileReader.getFilteredRecordCount` API. The implementation, however, only work for a few limited cases: in the scenario where there are multiple columns and their type width are different (e.g., `int` and `bigint`), it could return incorrect result. For this issue, please see SPARK-34859 for a detailed description.
In order to fix the above, Spark needs to leverage the API `PageReadStore.getRowIndexes` and `DataPage.getFirstRowIndex`. The former returns the indexes of all rows (note the difference between rows and values: for flat schema there is no difference between the two, but for nested schema they're different) after filtering within a Parquet row group. The latter returns the first row index within a single data page. With the combination of the two, one is able to know which rows/values should be filtered while scanning a Parquet page.
### Does this PR introduce _any_ user-facing change?
Yes. Now the vectorized Parquet reader should work correctly with column index.
### How was this patch tested?
Borrowed tests from #31998 and added a few more tests.
Closes #32753 from sunchao/SPARK-34859.
Lead-authored-by: Chao Sun <[email protected]>
Co-authored-by: Li Xian <[email protected]>
Signed-off-by: Dongjoon Hyun <[email protected]>
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
6 participants
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
What changes were proposed in this pull request?
This pr make parquet vectorized reader support column index.
Why are the changes needed?
Improve filter performance. for example:
id = 1, we only need to readpage-0inblock 1:Does this PR introduce any user-facing change?
No.
How was this patch tested?
Unit test and benchmark: #31393 (comment)