[SPARK-33935][SQL] Fix CBO cost function #30965
Conversation
|
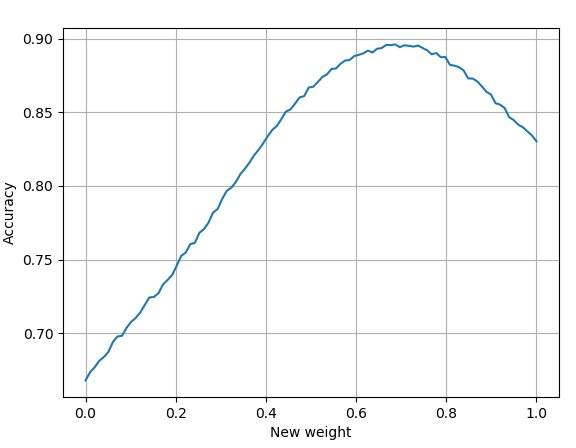
A bit more information: The unstability of CBO has been noted before (#29638) and I think, that this is the main reason for this. There is also #29871, that tackles another reason for the unstability. That one should only impact, when the costs are equal, this here can impact more plans (see the example in the description) An important thing to note is that this could change the the behavior of the |
|
@LuciferYang and @maropu |
|
Test build #133502 has finished for PR 30965 at commit
|
|
Kubernetes integration test starting |
|
Kubernetes integration test status success |
|
cc: @wzhfy |
|
I've checked the update and it seems fine. Could you add some tests based on the example in the PR description? |
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/CostBasedJoinReorder.scala
Outdated
Show resolved
Hide resolved
Ahh, good point. Adding this I also realised, that I had the inequality check in the wrong order - this greatly reduced the amount of plan changes. |
|
Kubernetes integration test starting |
|
Test build #133539 has finished for PR 30965 at commit
|
|
Kubernetes integration test status success |
|
Kubernetes integration test starting |
|
Kubernetes integration test status failure |
|
Test build #133534 has finished for PR 30965 at commit
|
|
Test build #133536 has finished for PR 30965 at commit
|
| assert(plan1.betterThan(plan2, conf)) | ||
| assert(!plan2.betterThan(plan1, conf)) |
There was a problem hiding this comment.
Thanks for adding this. This fix looks fine to me. cc: @cloud-fan @HyukjinKwon
|
retest this please |
|
@tanelk Can you help to run UTs in |
|
Kubernetes integration test starting |
|
Kubernetes integration test status success |
|
Test build #133621 has finished for PR 30965 at commit
|
### What changes were proposed in this pull request?
Changed the cost function in CBO to match documentation.
### Why are the changes needed?
The parameter `spark.sql.cbo.joinReorder.card.weight` is documented as:
```
The weight of cardinality (number of rows) for plan cost comparison in join reorder: rows * weight + size * (1 - weight).
```
The implementation in `JoinReorderDP.betterThan` does not match this documentaiton:
```
def betterThan(other: JoinPlan, conf: SQLConf): Boolean = {
if (other.planCost.card == 0 || other.planCost.size == 0) {
false
} else {
val relativeRows = BigDecimal(this.planCost.card) / BigDecimal(other.planCost.card)
val relativeSize = BigDecimal(this.planCost.size) / BigDecimal(other.planCost.size)
relativeRows * conf.joinReorderCardWeight +
relativeSize * (1 - conf.joinReorderCardWeight) < 1
}
}
```
This different implementation has an unfortunate consequence:
given two plans A and B, both A betterThan B and B betterThan A might give the same results. This happes when one has many rows with small sizes and other has few rows with large sizes.
A example values, that have this fenomen with the default weight value (0.7):
A.card = 500, B.card = 300
A.size = 30, B.size = 80
Both A betterThan B and B betterThan A would have score above 1 and would return false.
This happens with several of the TPCDS queries.
The new implementation does not have this behavior.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
New and existing UTs
Closes #30965 from tanelk/SPARK-33935_cbo_cost_function.
Authored-by: [email protected] <[email protected]>
Signed-off-by: Takeshi Yamamuro <[email protected]>
(cherry picked from commit f252a93)
Signed-off-by: Takeshi Yamamuro <[email protected]>
|
Thanks! Merged to master/3.1. |
Could you check this? Have this fix resolved the previous issue, too? |
|
@tanelk Could you open a PR to fix it for branch-3.0/2.4? |
The I assume you want the results of |
Awesome! |
|
@tanelk Hi, sorry to see this so late. IIRC the reason to use a relative value for rowCount and size, is to normalize them to a similar scale while comparing cost. Otherwise, one (size) may overwhelm the other (rowCount), then the weight and cost function become meaningless. To resolve the stability issue, can we have a What do you think? |
|
@wzhfy and @cloud-fan I'm not a fan of adding up the relative costs. A simple example, where the weight is 0.5: Perhaps this would be a best of both worlds: |
| ColumnarToRow | ||
| InputAdapter | ||
| Scan parquet default.store_sales [ss_sold_date_sk,ss_item_sk,ss_customer_sk,ss_store_sk,ss_ext_sales_price] | ||
| BroadcastHashJoin [ss_item_sk,i_item_sk] |
There was a problem hiding this comment.
I think q19 exposes a problem. Previously this BroadcastHashJoin is run before the SortMergeJoin, which reduces the input data of shuffle, because this BroadcastHashJoin has a filter on the right side and likely makes this join very selective.
@tanelk , if the idea from @wzhfy doesn't look good to you, can you try with some other ideas and see if we can fix this issue?
There was a problem hiding this comment.
I'll experiment with it a bit, but it might take a while.
There was a problem hiding this comment.
Thanks for looking into it!
There was a problem hiding this comment.
This actually caused a significant regression at q19 in TPC-DS benchmark (performed internally). Can we just revert it for now, and do it with actual performance numbers? I think that's safer and easier for everybody here. Seems like at least the plan change here was overlooked and the performance of this had to be clarified.
There was a problem hiding this comment.
branch-2.4 has the same regression? This PR was back-ported into branch-2.4, too. cc: @viirya
There was a problem hiding this comment.
+1 for @HyukjinKwon's suggestion. Especially for branch-2.4, I think it is better to avoid unexpected performance change.
There was a problem hiding this comment.
I discussed with @cloud-fan offline. Shall we merge #32014 into master, branch-3.1 and branch-3.0 to fix the regression, and revert this one from branch-2.4? Spark 2.4 release is very soon and might be best to stay safe, and technically this was more like an improvement.
There was a problem hiding this comment.
Agree with it. I prefer to make stable for branch-2.4.
There was a problem hiding this comment.
yea let's revert it from 2.4 to be safe
This reverts commit 3e6a6b7 per the discussion at #30965 (comment). Closes #32020 from viirya/revert-SPARK-33935. Authored-by: Liang-Chi Hsieh <[email protected]> Signed-off-by: HyukjinKwon <[email protected]>
### What changes were proposed in this pull request? Changed the cost comparison function of the CBO to use the ratios of row counts and sizes in bytes. ### Why are the changes needed? In #30965 we changed to CBO cost comparison function so it would be "symetric": `A.betterThan(B)` now implies, that `!B.betterThan(A)`. With that we caused a performance regressions in some queries - TPCDS q19 for example. The original cost comparison function used the ratios `relativeRows = A.rowCount / B.rowCount` and `relativeSize = A.size / B.size`. The changed function compared "absolute" cost values `costA = w*A.rowCount + (1-w)*A.size` and `costB = w*B.rowCount + (1-w)*B.size`. Given the input from wzhfy we decided to go back to the relative values, because otherwise one (size) may overwhelm the other (rowCount). But this time we avoid adding up the ratios. Originally `A.betterThan(B) => w*relativeRows + (1-w)*relativeSize < 1` was used. Besides being "non-symteric", this also can exhibit one overwhelming other. For `w=0.5` If `A` size (bytes) is at least 2x larger than `B`, then no matter how many times more rows does the `B` plan have, `B` will allways be considered to be better - `0.5*2 + 0.5*0.00000000000001 > 1`. When working with ratios, then it would be better to multiply them. The proposed cost comparison function is: `A.betterThan(B) => relativeRows^w * relativeSize^(1-w) < 1`. ### Does this PR introduce _any_ user-facing change? Comparison of the changed TPCDS v1.4 query execution times at sf=10: | absolute | multiplicative | | additive | -- | -- | -- | -- | -- | -- q12 | 145 | 137 | -5.52% | 141 | -2.76% q13 | 264 | 271 | 2.65% | 271 | 2.65% q17 | 4521 | 4243 | -6.15% | 4348 | -3.83% q18 | 758 | 466 | -38.52% | 480 | -36.68% q19 | 38503 | 2167 | -94.37% | 2176 | -94.35% q20 | 119 | 120 | 0.84% | 126 | 5.88% q24a | 16429 | 16838 | 2.49% | 17103 | 4.10% q24b | 16592 | 16999 | 2.45% | 17268 | 4.07% q25 | 3558 | 3556 | -0.06% | 3675 | 3.29% q33 | 362 | 361 | -0.28% | 380 | 4.97% q52 | 1020 | 1032 | 1.18% | 1052 | 3.14% q55 | 927 | 938 | 1.19% | 961 | 3.67% q72 | 24169 | 13377 | -44.65% | 24306 | 0.57% q81 | 1285 | 1185 | -7.78% | 1168 | -9.11% q91 | 324 | 336 | 3.70% | 337 | 4.01% q98 | 126 | 129 | 2.38% | 131 | 3.97% All times are in ms, the change is compared to the situation in the master branch (absolute). The proposed cost function (multiplicative) significantlly improves the performance on q18, q19 and q72. The original cost function (additive) has similar improvements at q18 and q19. All other chagnes are within the error bars and I would ignore them - perhaps q81 has also improved. ### How was this patch tested? PlanStabilitySuite Closes #32014 from tanelk/SPARK-34922_cbo_better_cost_function. Lead-authored-by: Tanel Kiis <[email protected]> Co-authored-by: [email protected] <[email protected]> Signed-off-by: Takeshi Yamamuro <[email protected]>
…e CBO ### What changes were proposed in this pull request? Changed the cost comparison function of the CBO to use the ratios of row counts and sizes in bytes. ### Why are the changes needed? In #30965 we changed to CBO cost comparison function so it would be "symetric": `A.betterThan(B)` now implies, that `!B.betterThan(A)`. With that we caused a performance regressions in some queries - TPCDS q19 for example. The original cost comparison function used the ratios `relativeRows = A.rowCount / B.rowCount` and `relativeSize = A.size / B.size`. The changed function compared "absolute" cost values `costA = w*A.rowCount + (1-w)*A.size` and `costB = w*B.rowCount + (1-w)*B.size`. Given the input from wzhfy we decided to go back to the relative values, because otherwise one (size) may overwhelm the other (rowCount). But this time we avoid adding up the ratios. Originally `A.betterThan(B) => w*relativeRows + (1-w)*relativeSize < 1` was used. Besides being "non-symteric", this also can exhibit one overwhelming other. For `w=0.5` If `A` size (bytes) is at least 2x larger than `B`, then no matter how many times more rows does the `B` plan have, `B` will allways be considered to be better - `0.5*2 + 0.5*0.00000000000001 > 1`. When working with ratios, then it would be better to multiply them. The proposed cost comparison function is: `A.betterThan(B) => relativeRows^w * relativeSize^(1-w) < 1`. ### Does this PR introduce _any_ user-facing change? Comparison of the changed TPCDS v1.4 query execution times at sf=10: | absolute | multiplicative | | additive | -- | -- | -- | -- | -- | -- q12 | 145 | 137 | -5.52% | 141 | -2.76% q13 | 264 | 271 | 2.65% | 271 | 2.65% q17 | 4521 | 4243 | -6.15% | 4348 | -3.83% q18 | 758 | 466 | -38.52% | 480 | -36.68% q19 | 38503 | 2167 | -94.37% | 2176 | -94.35% q20 | 119 | 120 | 0.84% | 126 | 5.88% q24a | 16429 | 16838 | 2.49% | 17103 | 4.10% q24b | 16592 | 16999 | 2.45% | 17268 | 4.07% q25 | 3558 | 3556 | -0.06% | 3675 | 3.29% q33 | 362 | 361 | -0.28% | 380 | 4.97% q52 | 1020 | 1032 | 1.18% | 1052 | 3.14% q55 | 927 | 938 | 1.19% | 961 | 3.67% q72 | 24169 | 13377 | -44.65% | 24306 | 0.57% q81 | 1285 | 1185 | -7.78% | 1168 | -9.11% q91 | 324 | 336 | 3.70% | 337 | 4.01% q98 | 126 | 129 | 2.38% | 131 | 3.97% All times are in ms, the change is compared to the situation in the master branch (absolute). The proposed cost function (multiplicative) significantlly improves the performance on q18, q19 and q72. The original cost function (additive) has similar improvements at q18 and q19. All other chagnes are within the error bars and I would ignore them - perhaps q81 has also improved. ### How was this patch tested? PlanStabilitySuite Closes #32075 from tanelk/SPARK-34922_cbo_better_cost_function_3.1. Lead-authored-by: Tanel Kiis <[email protected]> Co-authored-by: [email protected] <[email protected]> Signed-off-by: Takeshi Yamamuro <[email protected]>
…e CBO ### What changes were proposed in this pull request? Changed the cost comparison function of the CBO to use the ratios of row counts and sizes in bytes. ### Why are the changes needed? In #30965 we changed to CBO cost comparison function so it would be "symetric": `A.betterThan(B)` now implies, that `!B.betterThan(A)`. With that we caused a performance regressions in some queries - TPCDS q19 for example. The original cost comparison function used the ratios `relativeRows = A.rowCount / B.rowCount` and `relativeSize = A.size / B.size`. The changed function compared "absolute" cost values `costA = w*A.rowCount + (1-w)*A.size` and `costB = w*B.rowCount + (1-w)*B.size`. Given the input from wzhfy we decided to go back to the relative values, because otherwise one (size) may overwhelm the other (rowCount). But this time we avoid adding up the ratios. Originally `A.betterThan(B) => w*relativeRows + (1-w)*relativeSize < 1` was used. Besides being "non-symteric", this also can exhibit one overwhelming other. For `w=0.5` If `A` size (bytes) is at least 2x larger than `B`, then no matter how many times more rows does the `B` plan have, `B` will allways be considered to be better - `0.5*2 + 0.5*0.00000000000001 > 1`. When working with ratios, then it would be better to multiply them. The proposed cost comparison function is: `A.betterThan(B) => relativeRows^w * relativeSize^(1-w) < 1`. ### Does this PR introduce _any_ user-facing change? Comparison of the changed TPCDS v1.4 query execution times at sf=10: | absolute | multiplicative | | additive | -- | -- | -- | -- | -- | -- q12 | 145 | 137 | -5.52% | 141 | -2.76% q13 | 264 | 271 | 2.65% | 271 | 2.65% q17 | 4521 | 4243 | -6.15% | 4348 | -3.83% q18 | 758 | 466 | -38.52% | 480 | -36.68% q19 | 38503 | 2167 | -94.37% | 2176 | -94.35% q20 | 119 | 120 | 0.84% | 126 | 5.88% q24a | 16429 | 16838 | 2.49% | 17103 | 4.10% q24b | 16592 | 16999 | 2.45% | 17268 | 4.07% q25 | 3558 | 3556 | -0.06% | 3675 | 3.29% q33 | 362 | 361 | -0.28% | 380 | 4.97% q52 | 1020 | 1032 | 1.18% | 1052 | 3.14% q55 | 927 | 938 | 1.19% | 961 | 3.67% q72 | 24169 | 13377 | -44.65% | 24306 | 0.57% q81 | 1285 | 1185 | -7.78% | 1168 | -9.11% q91 | 324 | 336 | 3.70% | 337 | 4.01% q98 | 126 | 129 | 2.38% | 131 | 3.97% All times are in ms, the change is compared to the situation in the master branch (absolute). The proposed cost function (multiplicative) significantlly improves the performance on q18, q19 and q72. The original cost function (additive) has similar improvements at q18 and q19. All other chagnes are within the error bars and I would ignore them - perhaps q81 has also improved. ### How was this patch tested? PlanStabilitySuite Closes #32076 from tanelk/SPARK-34922_cbo_better_cost_function_3.0. Lead-authored-by: Tanel Kiis <[email protected]> Co-authored-by: [email protected] <[email protected]> Signed-off-by: Takeshi Yamamuro <[email protected]>
…e CBO ### What changes were proposed in this pull request? Changed the cost comparison function of the CBO to use the ratios of row counts and sizes in bytes. ### Why are the changes needed? In apache#30965 we changed to CBO cost comparison function so it would be "symetric": `A.betterThan(B)` now implies, that `!B.betterThan(A)`. With that we caused a performance regressions in some queries - TPCDS q19 for example. The original cost comparison function used the ratios `relativeRows = A.rowCount / B.rowCount` and `relativeSize = A.size / B.size`. The changed function compared "absolute" cost values `costA = w*A.rowCount + (1-w)*A.size` and `costB = w*B.rowCount + (1-w)*B.size`. Given the input from wzhfy we decided to go back to the relative values, because otherwise one (size) may overwhelm the other (rowCount). But this time we avoid adding up the ratios. Originally `A.betterThan(B) => w*relativeRows + (1-w)*relativeSize < 1` was used. Besides being "non-symteric", this also can exhibit one overwhelming other. For `w=0.5` If `A` size (bytes) is at least 2x larger than `B`, then no matter how many times more rows does the `B` plan have, `B` will allways be considered to be better - `0.5*2 + 0.5*0.00000000000001 > 1`. When working with ratios, then it would be better to multiply them. The proposed cost comparison function is: `A.betterThan(B) => relativeRows^w * relativeSize^(1-w) < 1`. ### Does this PR introduce _any_ user-facing change? Comparison of the changed TPCDS v1.4 query execution times at sf=10: | absolute | multiplicative | | additive | -- | -- | -- | -- | -- | -- q12 | 145 | 137 | -5.52% | 141 | -2.76% q13 | 264 | 271 | 2.65% | 271 | 2.65% q17 | 4521 | 4243 | -6.15% | 4348 | -3.83% q18 | 758 | 466 | -38.52% | 480 | -36.68% q19 | 38503 | 2167 | -94.37% | 2176 | -94.35% q20 | 119 | 120 | 0.84% | 126 | 5.88% q24a | 16429 | 16838 | 2.49% | 17103 | 4.10% q24b | 16592 | 16999 | 2.45% | 17268 | 4.07% q25 | 3558 | 3556 | -0.06% | 3675 | 3.29% q33 | 362 | 361 | -0.28% | 380 | 4.97% q52 | 1020 | 1032 | 1.18% | 1052 | 3.14% q55 | 927 | 938 | 1.19% | 961 | 3.67% q72 | 24169 | 13377 | -44.65% | 24306 | 0.57% q81 | 1285 | 1185 | -7.78% | 1168 | -9.11% q91 | 324 | 336 | 3.70% | 337 | 4.01% q98 | 126 | 129 | 2.38% | 131 | 3.97% All times are in ms, the change is compared to the situation in the master branch (absolute). The proposed cost function (multiplicative) significantlly improves the performance on q18, q19 and q72. The original cost function (additive) has similar improvements at q18 and q19. All other chagnes are within the error bars and I would ignore them - perhaps q81 has also improved. ### How was this patch tested? PlanStabilitySuite Closes apache#32075 from tanelk/SPARK-34922_cbo_better_cost_function_3.1. Lead-authored-by: Tanel Kiis <[email protected]> Co-authored-by: [email protected] <[email protected]> Signed-off-by: Takeshi Yamamuro <[email protected]>
…e CBO ### What changes were proposed in this pull request? Changed the cost comparison function of the CBO to use the ratios of row counts and sizes in bytes. ### Why are the changes needed? In apache#30965 we changed to CBO cost comparison function so it would be "symetric": `A.betterThan(B)` now implies, that `!B.betterThan(A)`. With that we caused a performance regressions in some queries - TPCDS q19 for example. The original cost comparison function used the ratios `relativeRows = A.rowCount / B.rowCount` and `relativeSize = A.size / B.size`. The changed function compared "absolute" cost values `costA = w*A.rowCount + (1-w)*A.size` and `costB = w*B.rowCount + (1-w)*B.size`. Given the input from wzhfy we decided to go back to the relative values, because otherwise one (size) may overwhelm the other (rowCount). But this time we avoid adding up the ratios. Originally `A.betterThan(B) => w*relativeRows + (1-w)*relativeSize < 1` was used. Besides being "non-symteric", this also can exhibit one overwhelming other. For `w=0.5` If `A` size (bytes) is at least 2x larger than `B`, then no matter how many times more rows does the `B` plan have, `B` will allways be considered to be better - `0.5*2 + 0.5*0.00000000000001 > 1`. When working with ratios, then it would be better to multiply them. The proposed cost comparison function is: `A.betterThan(B) => relativeRows^w * relativeSize^(1-w) < 1`. ### Does this PR introduce _any_ user-facing change? Comparison of the changed TPCDS v1.4 query execution times at sf=10: | absolute | multiplicative | | additive | -- | -- | -- | -- | -- | -- q12 | 145 | 137 | -5.52% | 141 | -2.76% q13 | 264 | 271 | 2.65% | 271 | 2.65% q17 | 4521 | 4243 | -6.15% | 4348 | -3.83% q18 | 758 | 466 | -38.52% | 480 | -36.68% q19 | 38503 | 2167 | -94.37% | 2176 | -94.35% q20 | 119 | 120 | 0.84% | 126 | 5.88% q24a | 16429 | 16838 | 2.49% | 17103 | 4.10% q24b | 16592 | 16999 | 2.45% | 17268 | 4.07% q25 | 3558 | 3556 | -0.06% | 3675 | 3.29% q33 | 362 | 361 | -0.28% | 380 | 4.97% q52 | 1020 | 1032 | 1.18% | 1052 | 3.14% q55 | 927 | 938 | 1.19% | 961 | 3.67% q72 | 24169 | 13377 | -44.65% | 24306 | 0.57% q81 | 1285 | 1185 | -7.78% | 1168 | -9.11% q91 | 324 | 336 | 3.70% | 337 | 4.01% q98 | 126 | 129 | 2.38% | 131 | 3.97% All times are in ms, the change is compared to the situation in the master branch (absolute). The proposed cost function (multiplicative) significantlly improves the performance on q18, q19 and q72. The original cost function (additive) has similar improvements at q18 and q19. All other chagnes are within the error bars and I would ignore them - perhaps q81 has also improved. ### How was this patch tested? PlanStabilitySuite Closes apache#32075 from tanelk/SPARK-34922_cbo_better_cost_function_3.1. Lead-authored-by: Tanel Kiis <[email protected]> Co-authored-by: [email protected] <[email protected]> Signed-off-by: Takeshi Yamamuro <[email protected]>
What changes were proposed in this pull request?
Changed the cost function in CBO to match documentation.
Why are the changes needed?
The parameter
spark.sql.cbo.joinReorder.card.weightis documented as:The implementation in
JoinReorderDP.betterThandoes not match this documentaiton:This different implementation has an unfortunate consequence:
given two plans A and B, both A betterThan B and B betterThan A might give the same results. This happes when one has many rows with small sizes and other has few rows with large sizes.
A example values, that have this fenomen with the default weight value (0.7):
A.card = 500, B.card = 300
A.size = 30, B.size = 80
Both A betterThan B and B betterThan A would have score above 1 and would return false.
This happens with several of the TPCDS queries.
The new implementation does not have this behavior.
Does this PR introduce any user-facing change?
No
How was this patch tested?
New and existing UTs