[SPARK-32455][ML][Follow-Up] LogisticRegressionModel prediction optimization - fix incorrect initialization #30013
Conversation
use lazy array
|
test in commit 27eab00: results: scala> lorm.getThreshold scala> lorm.predict(vec) The // this PR |
|
Kubernetes integration test starting |
|
Test build #129677 has finished for PR 30013 at commit
|
|
Kubernetes integration test status success |
|
In #29255, the values of |
|
@huaxingao In #29255, if threshold is set in binary lor Estimator, then in the Model, the values of
Yes, I think we need to figure out why the testsuites failed to catch this, and update them if necessary. |
|
@huaxingao I find that in suite |
| val binaryModel = blr.fit(smallBinaryDataset) | ||
|
|
||
| binaryModel.setThreshold(1.0) | ||
| testTransformer[(Double, Vector)](smallBinaryDataset.toDF(), binaryModel, "prediction") { |
There was a problem hiding this comment.
master fails in this modified case:
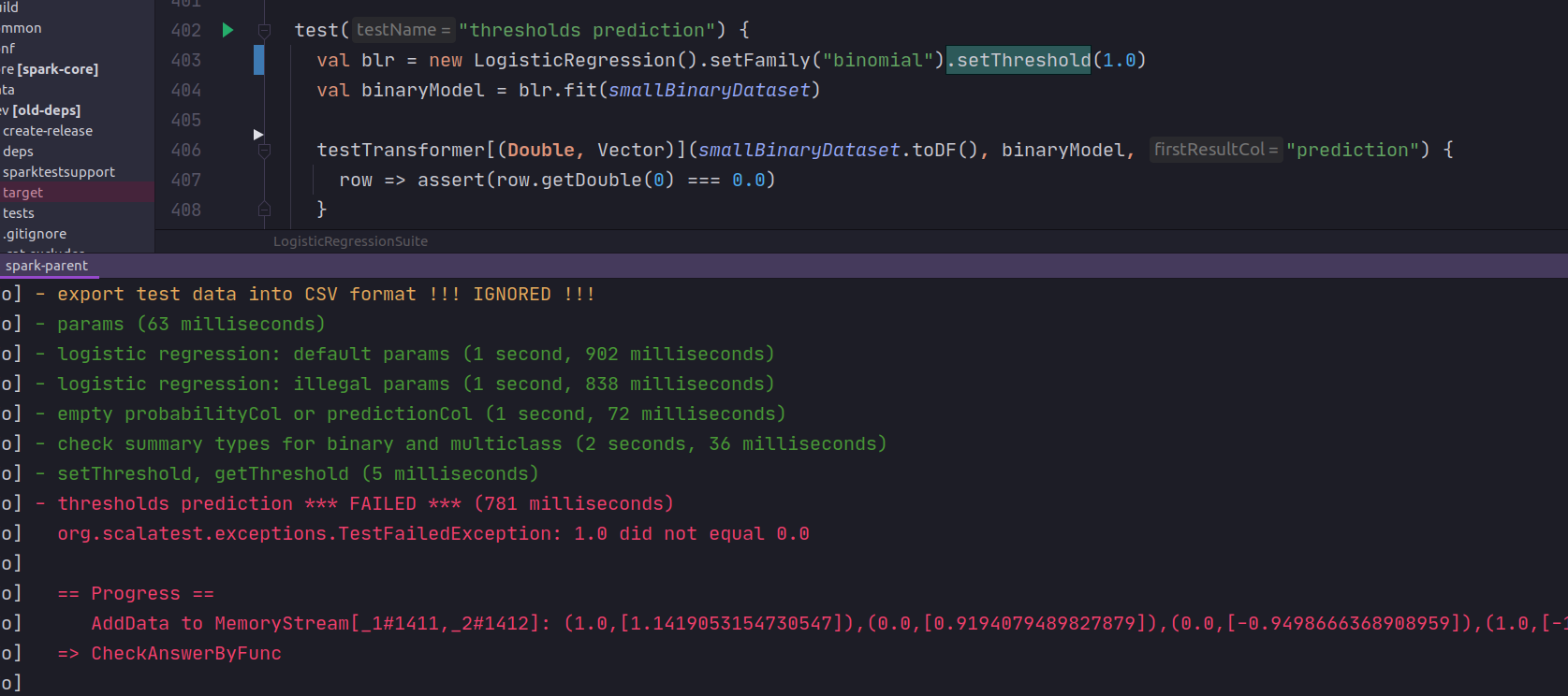
|
Kubernetes integration test starting |
|
Test build #129718 has finished for PR 30013 at commit
|
|
Kubernetes integration test status success |
|
Merged to master, thanks all! |
What changes were proposed in this pull request?
use
lazy arrayinstead ofvarfor auxiliary variables in binary lorWhy are the changes needed?
In #29255, I made a mistake:
the
private var _thresholdand_rawThresholdare initialized by defaut values ofthreshold, that is beacuse:1, param
thresholdis set default value at first;2,
_thresholdand_rawThresholdare initialized based on the default value;3, param
thresholdis updated by the value from estimator, bycopyValuesmethod:We can update
_thresholdand_rawThresholdinsetThresholdandsetThresholds, but we can not update them inset/copyValuesso their values are kept until methodssetThresholdandsetThresholdsare called.Does this PR introduce any user-facing change?
No
How was this patch tested?
test in repl