[SPARK-32914][SQL] Avoid constructing dataType multiple times#29790
[SPARK-32914][SQL] Avoid constructing dataType multiple times#29790wangyum wants to merge 5 commits intoapache:masterfrom wangyum:SPARK-32914
Conversation
|
Test build #128834 has finished for PR 29790 at commit
|
|
Test build #128836 has finished for PR 29790 at commit
|
|
do we really need such an invasive change? If there is a specific expression that calls |
|
Or if an expression has a very complicated |
|
Test build #128864 has finished for PR 29790 at commit
|
|
Test build #128957 has finished for PR 29790 at commit
|
|
retest this please |
| extends SubqueryExpression(plan, children, exprId) with Unevaluable { | ||
| override def dataType: DataType = { | ||
|
|
||
| private lazy val internalDataType: DataType = { |
There was a problem hiding this comment.
does this need to be a lazy val? seems a very cheap method.
There was a problem hiding this comment.
I reverted this change because I did not find an expression to call this method many times.
| @transient private lazy val childDataType: MapType = child.dataType.asInstanceOf[MapType] | ||
|
|
||
| override def dataType: DataType = { | ||
| private lazy val internalDataType: DataType = { |
There was a problem hiding this comment.
is it expensive? it just creates a few objects.
There was a problem hiding this comment.
This is to improve this case:
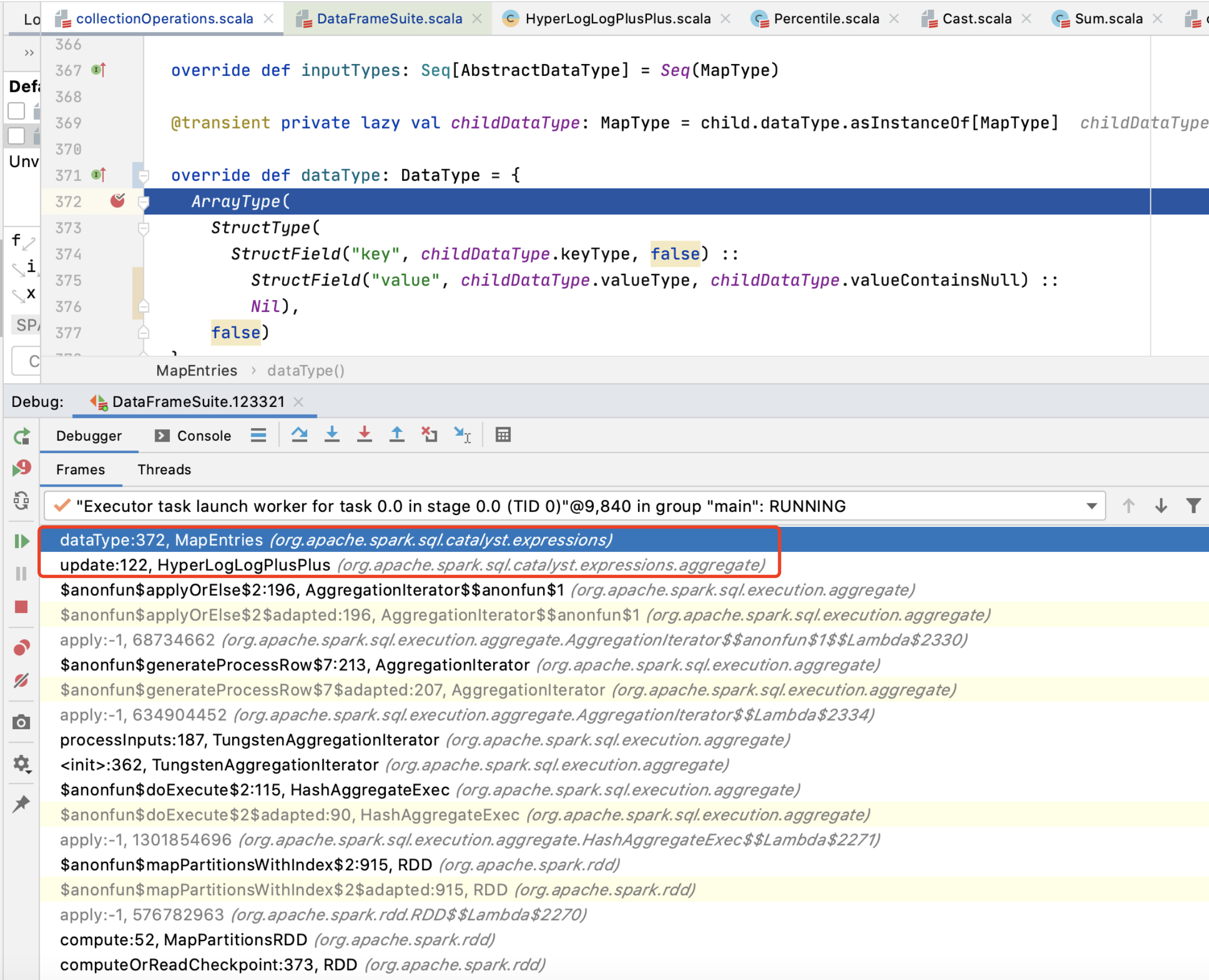
| Benchmark code | Before this PR(Milliseconds) | After this PR(Milliseconds) |
|---|---|---|
| spark.range(100000000L).selectExpr("approx_count_distinct(map_entries(map(1, id)))").collect() | 21787 | 15551 |
|
Test build #128970 has finished for PR 29790 at commit
|
|
Test build #128983 has finished for PR 29790 at commit
|
|
Test build #128985 has finished for PR 29790 at commit
|
|
Kubernetes integration test starting |
|
Kubernetes integration test status success |
|
Test build #129174 has finished for PR 29790 at commit
|
| @transient | ||
| lazy val inputTypesForMerging: Seq[DataType] = children.map(_.dataType) | ||
|
|
||
| private lazy val internalDataType: DataType = { |
There was a problem hiding this comment.
can we put it right before the line of override def dataType: DataType?
|
Kubernetes integration test starting |
|
Kubernetes integration test status success |
|
Test build #129238 has finished for PR 29790 at commit
|
|
Merged to master. |
What changes were proposed in this pull request?
Some expression's data type not a static value. It needs to be constructed a new object when calling
dataTypefunction. E.g.:CaseWhen.We should avoid constructing dataType multiple times because it may be used many times. E.g.:
HyperLogLogPlusPlus.update.Why are the changes needed?
Improve query performance. for example:
Profiling result:
Does this PR introduce any user-facing change?
No.
How was this patch tested?
Manual test and benchmark test: