[SPARK-28527][SQL][TEST] Re-run all the tests in SQLQueryTestSuite via Thrift Server #25373
Conversation
|
Test build #108749 has finished for PR 25373 at commit
|
|
retest this please |
|
Test build #108752 has finished for PR 25373 at commit
|
|
Test build #108760 has finished for PR 25373 at commit
|
|
Added 112 tests for Thrift Server: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/108760/testReport/org.apache.spark.sql.hive.thriftserver/ |
|
Can we add the new test suite using their own forked JVMs? I found it is slow. 15 minutes! |
|
Test build #108826 has finished for PR 25373 at commit
|
 juliuszsompolski
left a comment
juliuszsompolski
left a comment
There was a problem hiding this comment.
@gatorsmile - I assume that starting a new session/connection for every test is intentional for test isolation? It's likely responsible for a big part of the cost of this suite (and original SQLSuite), but I reckon it's necessary to not have it flaky.
|
|
||
| private var hiveServer2: HiveThriftServer2 = _ | ||
|
|
||
| override def beforeEach(): Unit = { |
There was a problem hiding this comment.
How long does it take to start thriftserver?
Would it be possible to start it once in beforeAll?
There was a problem hiding this comment.
The first time is very slow:
[info] ThriftServerQueryTestSuite:
[info] - group-by.sql !!! IGNORED !!!
Start ThriftServer time: 5599
[info] - natural-join.sql (8 seconds, 404 milliseconds)
Start ThriftServer time: 44
[info] - csv-functions.sql (1 second, 30 milliseconds)
Start ThriftServer time: 34
[info] - except.sql (8 seconds, 354 milliseconds)
Start ThriftServer time: 38
[info] - string-functions.sql (1 second, 281 milliseconds)
Start ThriftServer time: 39
[info] - describe-table-column.sql (2 seconds, 434 milliseconds)
Start ThriftServer time: 81
[info] - random.sql (621 milliseconds)
Start ThriftServer time: 30
[info] - tablesample-negative.sql (485 milliseconds)
Start ThriftServer time: 30
[info] - window.sql (25 seconds, 601 milliseconds)
Start ThriftServer time: 32
[info] - join-empty-relation.sql (632 milliseconds)
Start ThriftServer time: 35
[info] - null-propagation.sql (310 milliseconds)
Start ThriftServer time: 33
[info] - operators.sql (1 second, 683 milliseconds)
Start ThriftServer time: 33
[info] - change-column.sql (504 milliseconds)
Start ThriftServer time: 33
[info] - count.sql (2 seconds, 125 milliseconds)
[info] - decimalArithmeticOperations.sql !!! IGNORED !!!
Start ThriftServer time: 31
[info] - group-analytics.sql (16 seconds, 295 milliseconds)
Start ThriftServer time: 34
[info] - inline-table.sql (430 milliseconds)
Start ThriftServer time: 29
[info] - comparator.sql (240 milliseconds)
Start ThriftServer time: 27
There was a problem hiding this comment.
It still takes 16 minutes after move startThriftServer from beforeEach to beforeAll.
startThriftServer at beforeAll:
https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109036/testReport/org.apache.spark.sql.hive.thriftserver/
startThriftServer at beforeEach:
https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/108826/testReport/org.apache.spark.sql.hive.thriftserver/
| hiveServer2 = HiveThriftServer2.startWithContext(sqlContext) | ||
| } | ||
|
|
||
| private def withJdbcStatement(fs: (Statement => Unit)*) { |
There was a problem hiding this comment.
Could we keep the connection open, to not have to start a sessopm amd reload the test data into temp views each time?
We could open the connection with conn = DriverManager.getConnection(jdbcUri, user, "") in beforeAll, load the test data there, and then have withJDBCStatement just create new statements, finally closing the connection in afterAll.
However, it seems that opening new connection/session may be by design here, for test isolation. Then we'll have to leave it as is, but I think we should still be able to avoid starting the ThriftServer beforeEach.
There was a problem hiding this comment.
If move loadTestData to beforeAll. Some tests will fail:
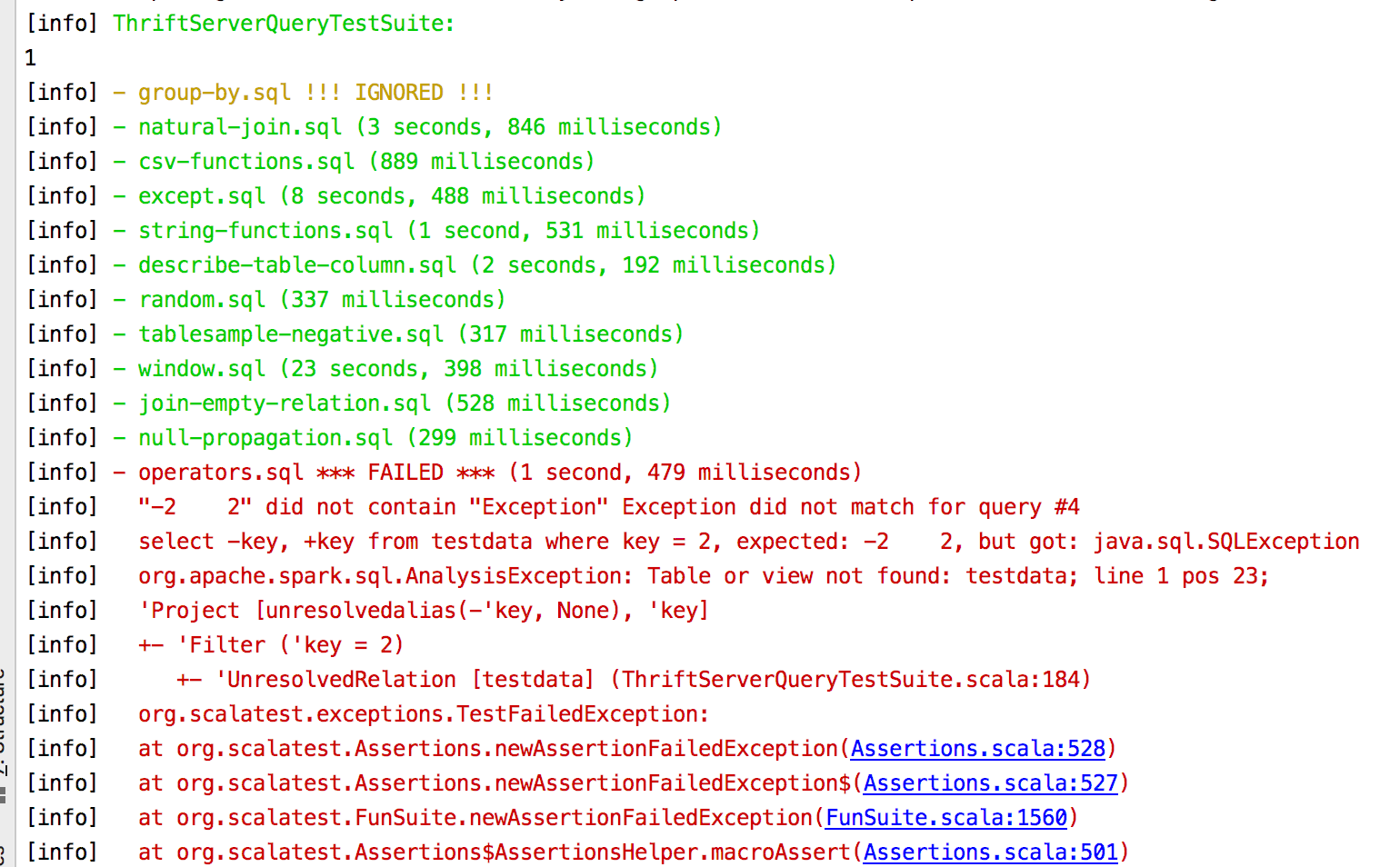
|
Test build #109036 has finished for PR 25373 at commit
|
juliuszsompolski
left a comment
There was a problem hiding this comment.
LGTM! Thanks. This really improves coverage and has flushed multiple issues already. Let's get it in :-).
cc @gatorsmile
|
Thanks! Merged to master. |
|
Hi, Guys. This seems to add a new flaky test suite in
In general, cc @wangyum, @srowen , @HyukjinKwon . I'm monitoring the next Jenkins run. If the next run fails consecutively, we had better revert this first and merge this later after testing with |
|
I found that this also breaks
Since this breaks all Maven profiles, I'll revert this. Sorry, @wangyum and @gatorsmile . Please make another PR and test with Maven Hadoop-2.7/Hadoop-3.2. |
|
+1 for reverting for now. |
|
The reason is that the path is different: sbt: |
|
PS there is more to the failure: It does sorta look like it can't list a directory because it's 'empty'? that is Comments in But then I don't know how Maven builds have ever worked for Weirder still is that it doesn't happen consistently? Well yeah I think we'd have to revert for now. |
|
@dongjoon-hyun @srowen @HyukjinKwon @wangyum |
|
Just guessing: can it be an issue that for SQLQueryTestSuite, these files were resources in the same project jar, while for ThriftServerQueryTestSuite it needs to pull them from a dependency? A guess based on https://stackoverflow.com/questions/5292283/use-a-dependencys-resources: maybe changing https://github.com/apache/spark/blob/master/sql/core/src/test/scala/org/apache/spark/sql/SQLQueryTestSuite.scala#L117 |
|
I doubt those two would be in different classloaders, but, I also don't know what the issue is. |
|
Could we skip this test when testing with maven? override def listTestCases(): Seq[TestCase] = {
- listFilesRecursively(new File(inputFilePath)).flatMap { file =>
- val resultFile = file.getAbsolutePath.replace(inputFilePath, goldenFilePath) + ".out"
- val absPath = file.getAbsolutePath
- val testCaseName = absPath.stripPrefix(inputFilePath).stripPrefix(File.separator)
+ // Maven can not get the correct baseResourcePath
+ if (baseResourcePath.exists()) {
+ listFilesRecursively(new File(inputFilePath)).flatMap { file =>
+ val resultFile = file.getAbsolutePath.replace(inputFilePath, goldenFilePath) + ".out"
+ val absPath = file.getAbsolutePath
+ val testCaseName = absPath.stripPrefix(inputFilePath).stripPrefix(File.separator)
- if (file.getAbsolutePath.startsWith(s"$inputFilePath${File.separator}udf")) {
- Seq.empty
- } else if (file.getAbsolutePath.startsWith(s"$inputFilePath${File.separator}pgSQL")) {
- PgSQLTestCase(testCaseName, absPath, resultFile) :: Nil
- } else {
- RegularTestCase(testCaseName, absPath, resultFile) :: Nil
+ if (file.getAbsolutePath.startsWith(s"$inputFilePath${File.separator}udf")) {
+ Seq.empty
+ } else if (file.getAbsolutePath.startsWith(s"$inputFilePath${File.separator}pgSQL")) {
+ PgSQLTestCase(testCaseName, absPath, resultFile) :: Nil
+ } else {
+ RegularTestCase(testCaseName, absPath, resultFile) :: Nil
+ }
}
+ } else {
+ Seq.empty[TestCase]
}
} |
|
Yeah, Maven is the 'build of reference' so I'd hesitate to have any SBT-only tests. I think we'd have to debug and fix it, though I expect this one is subtle and I couldn't figure it out in an hour |
…a Thrift Server ## What changes were proposed in this pull request? This PR build a test framework that directly re-run all the tests in `SQLQueryTestSuite` via Thrift Server. But it's a little different from `SQLQueryTestSuite`: 1. Can not support [UDF testing](https://github.com/apache/spark/blob/44e607e9213bdceab970606fb15292db2fe157c2/sql/core/src/test/scala/org/apache/spark/sql/SQLQueryTestSuite.scala#L293-L297). 2. Can not support `DESC` command and `SHOW` command because `SQLQueryTestSuite` [formatted the output](https://github.com/apache/spark/blob/1882912cca4921d3d8c8632b3bb34e69e8119791/sql/core/src/main/scala/org/apache/spark/sql/execution/HiveResult.scala#L38-L50.). When building this framework, found two bug: [SPARK-28624](https://issues.apache.org/jira/browse/SPARK-28624): `make_date` is inconsistent when reading from table [SPARK-28611](https://issues.apache.org/jira/browse/SPARK-28611): Histogram's height is different found two features that ThriftServer can not support: [SPARK-28636](https://issues.apache.org/jira/browse/SPARK-28636): ThriftServer can not support decimal type with negative scale [SPARK-28637](https://issues.apache.org/jira/browse/SPARK-28637): ThriftServer can not support interval type Also, found two inconsistent behavior: [SPARK-28620](https://issues.apache.org/jira/browse/SPARK-28620): Double type returned for float type in Beeline/JDBC [SPARK-28619](https://issues.apache.org/jira/browse/SPARK-28619): The golden result file is different when tested by `bin/spark-sql` ## How was this patch tested? N/A Closes apache#25373 from wangyum/SPARK-28527. Authored-by: Yuming Wang <[email protected]> Signed-off-by: gatorsmile <[email protected]>
|
Thanks for pinging me @juliuszsompolski. One possible solution might be just always users sql-tests from the source by Spark home which is set by default. Seems similar way is already used when Referring spark.home property or SPARK_HOME is a proper way to detect some paths too. I think it's not crazy to use this way. Let me open a PR |
What changes were proposed in this pull request?
This PR build a test framework that directly re-run all the tests in
SQLQueryTestSuitevia Thrift Server. But it's a little different fromSQLQueryTestSuite:DESCcommand andSHOWcommand becauseSQLQueryTestSuiteformatted the output.When building this framework, found two bug:
SPARK-28624:
make_dateis inconsistent when reading from tableSPARK-28611: Histogram's height is different
found two features that ThriftServer can not support:
SPARK-28636: ThriftServer can not support decimal type with negative scale
SPARK-28637: ThriftServer can not support interval type
Also, found two inconsistent behavior:
SPARK-28620: Double type returned for float type in Beeline/JDBC
SPARK-28619: The golden result file is different when tested by
bin/spark-sqlHow was this patch tested?
N/A