[SPARK-28609][DOC] Fix broken styles/links and make up-to-date#25345
[SPARK-28609][DOC] Fix broken styles/links and make up-to-date#25345dongjoon-hyun wants to merge 1 commit intoapache:masterfrom dongjoon-hyun:SPARK-28609
Conversation
| Useful for allowing Spark to resolve artifacts from behind a firewall e.g. via an in-house | ||
| artifact server like Artifactory. Details on the settings file format can be | ||
| found at http://ant.apache.org/ivy/history/latest-milestone/settings.html | ||
| found at <a href="http://ant.apache.org/ivy/history/latest-milestone/settings.html">Settings Files</a> |
There was a problem hiding this comment.
Hyperlink is better than the text. Note that Settings Files is the title of that page.
| Internally, by default, Structured Streaming queries are processed using a *micro-batch processing* engine, which processes data streams as a series of small batch jobs thereby achieving end-to-end latencies as low as 100 milliseconds and exactly-once fault-tolerance guarantees. However, since Spark 2.3, we have introduced a new low-latency processing mode called **Continuous Processing**, which can achieve end-to-end latencies as low as 1 millisecond with at-least-once guarantees. Without changing the Dataset/DataFrame operations in your queries, you will be able to choose the mode based on your application requirements. | ||
|
|
||
| In this guide, we are going to walk you through the programming model and the APIs. We are going to explain the concepts mostly using the default micro-batch processing model, and then [later](#continuous-processing-experimental) discuss Continuous Processing model. First, let's start with a simple example of a Structured Streaming query - a streaming word count. | ||
| In this guide, we are going to walk you through the programming model and the APIs. We are going to explain the concepts mostly using the default micro-batch processing model, and then [later](#continuous-processing) discuss Continuous Processing model. First, let's start with a simple example of a Structured Streaming query - a streaming word count. |
There was a problem hiding this comment.
This fixes the broken link. Previously, it points like the following instead of that section.
| - Joins can be cascaded, that is, you can do `df1.join(df2, ...).join(df3, ...).join(df4, ....)`. | ||
|
|
||
| - As of Spark 2.3, you can use joins only when the query is in Append output mode. Other output modes are not yet supported. | ||
| - As of Spark 2.4, you can use joins only when the query is in Append output mode. Other output modes are not yet supported. |
There was a problem hiding this comment.
For now, it's 2.4 because this patch will be backported to branch-2.4. We will update this later when we prepare 3.0.0.
| For that situation you must specify the processing logic in an object. | ||
|
|
||
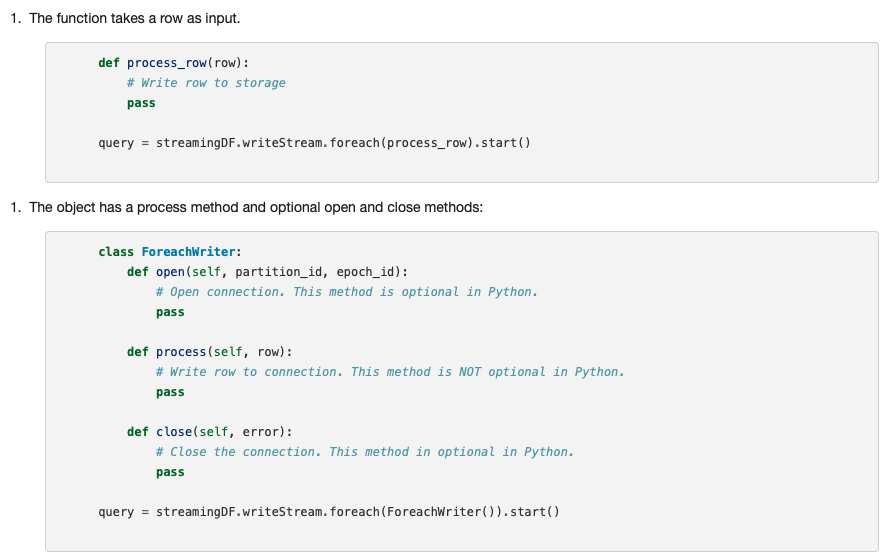
| 1. The function takes a row as input. | ||
| - First, the function takes a row as input. |
There was a problem hiding this comment.
The following is the current screenshot of our 2.4.3 page. The enumeration doesn't work well with template. Also, the python example has redundant leading spaces inconsistently from the other Python examples.
| .format("rate") | ||
| .option("rowsPerSecond", "10") | ||
| .option("") | ||
|
|
There was a problem hiding this comment.
This seems to be incomplete leftover. We had better remove this because the other language tabs don't have this. After removing this, we will have Kafka examples consistently across all languages.
| <tr><td> <code>k8s://HOST:PORT</code> </td><td> Connect to a <a href="running-on-kubernetes.html">Kubernetes</a> cluster in | ||
| <code>cluster</code> mode. Client mode is currently unsupported and will be supported in future releases. | ||
| The <code>HOST</code> and <code>PORT</code> refer to the [Kubernetes API Server](https://kubernetes.io/docs/reference/generated/kube-apiserver/). | ||
| The <code>HOST</code> and <code>PORT</code> refer to the <a href="https://kubernetes.io/docs/reference/generated/kube-apiserver/">Kubernetes API Server</a>. |
There was a problem hiding this comment.
Inside table, we need to use a tag like line 183.
|
Test build #108598 has finished for PR 25345 at commit
|
|
Thank you for review and approval, @HyukjinKwon . |
This PR aims to fix the broken styles/links and make the doc up-to-date for Apache Spark 2.4.4 and 3.0.0 release. - `building-spark.md`  - `configuration.md`  - `sql-pyspark-pandas-with-arrow.md`  - `streaming-programming-guide.md`  - `structured-streaming-programming-guide.md` (1/2)  - `structured-streaming-programming-guide.md` (2/2)  - `submitting-applications.md`  Manual. Build the doc. ``` SKIP_API=1 jekyll build ``` Closes #25345 from dongjoon-hyun/SPARK-28609. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 4856c0e) Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
This PR aims to fix the broken styles/links and make the doc up-to-date for Apache Spark 2.4.4 and 3.0.0 release. - `building-spark.md`  - `configuration.md`  - `sql-pyspark-pandas-with-arrow.md`  - `streaming-programming-guide.md`  - `structured-streaming-programming-guide.md` (1/2)  - `structured-streaming-programming-guide.md` (2/2)  - `submitting-applications.md`  Manual. Build the doc. ``` SKIP_API=1 jekyll build ``` Closes apache#25345 from dongjoon-hyun/SPARK-28609. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 4856c0e) Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
This PR aims to fix the broken styles/links and make the doc up-to-date for Apache Spark 2.4.4 and 3.0.0 release. - `building-spark.md`  - `configuration.md`  - `sql-pyspark-pandas-with-arrow.md`  - `streaming-programming-guide.md`  - `structured-streaming-programming-guide.md` (1/2)  - `structured-streaming-programming-guide.md` (2/2)  - `submitting-applications.md`  Manual. Build the doc. ``` SKIP_API=1 jekyll build ``` Closes apache#25345 from dongjoon-hyun/SPARK-28609. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 4856c0e) Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
What changes were proposed in this pull request?
This PR aims to fix the broken styles/links and make the doc up-to-date for Apache Spark 2.4.4 and 3.0.0 release.
building-spark.mdconfiguration.mdsql-pyspark-pandas-with-arrow.mdstreaming-programming-guide.mdstructured-streaming-programming-guide.md(1/2)structured-streaming-programming-guide.md(2/2)submitting-applications.mdHow was this patch tested?
Manual. Build the doc.