[SPARK-28577][YARN]Resource capability requested for each executor add offHeapMemorySize #25309
There are no files selected for viewing
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -131,6 +131,8 @@ private[yarn] class YarnAllocator( | |
|
|
||
| // Executor memory in MiB. | ||
| protected val executorMemory = sparkConf.get(EXECUTOR_MEMORY).toInt | ||
| // Executor offHeap memory in MiB. | ||
| protected val executorOffHeapMemory = YarnSparkHadoopUtil.executorOffHeapMemorySizeAsMb(sparkConf) | ||
| // Additional memory overhead. | ||
| protected val memoryOverhead: Int = sparkConf.get(EXECUTOR_MEMORY_OVERHEAD).getOrElse( | ||
| math.max((MEMORY_OVERHEAD_FACTOR * executorMemory).toInt, MEMORY_OVERHEAD_MIN)).toInt | ||
|
|
@@ -149,7 +151,7 @@ private[yarn] class YarnAllocator( | |
| // Resource capability requested for each executor | ||
| private[yarn] val resource: Resource = { | ||
| val resource = Resource.newInstance( | ||
| executorMemory + executorOffHeapMemory + memoryOverhead + pysparkWorkerMemory, executorCores) | ||
|
Contributor
There was a problem hiding this comment. According line 258 to 260 in
Contributor
Author
There was a problem hiding this comment. Described in the document is
Contributor
There was a problem hiding this comment. Yes, this makes me confused.
Member
There was a problem hiding this comment. Isn't this what
Contributor
Author
There was a problem hiding this comment. @srowen |
||
| ResourceRequestHelper.setResourceRequests(executorResourceRequests, resource) | ||
| logDebug(s"Created resource capability: $resource") | ||
| resource | ||
|
|
||
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -26,9 +26,8 @@ import org.apache.hadoop.yarn.api.records.{ApplicationAccessType, ContainerId, P | |
| import org.apache.hadoop.yarn.util.ConverterUtils | ||
|
|
||
| import org.apache.spark.{SecurityManager, SparkConf} | ||
| import org.apache.spark.internal.config._ | ||
| import org.apache.spark.launcher.YarnCommandBuilderUtils | ||
| import org.apache.spark.util.Utils | ||
|
|
||
| object YarnSparkHadoopUtil { | ||
|
|
@@ -184,4 +183,17 @@ object YarnSparkHadoopUtil { | |
| ConverterUtils.toContainerId(containerIdString) | ||
| } | ||
|
|
||
| /** | ||
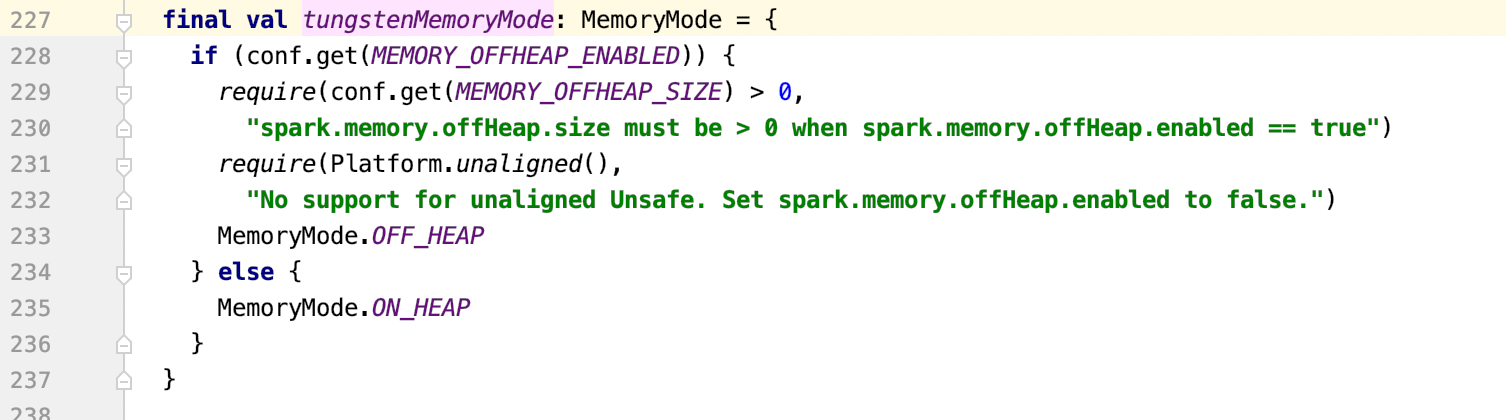
| * Convert MEMORY_OFFHEAP_SIZE to MB Unit, return 0 if MEMORY_OFFHEAP_ENABLED is false. | ||
| */ | ||
| def executorOffHeapMemorySizeAsMb(sparkConf: SparkConf): Int = { | ||
| if (sparkConf.get(MEMORY_OFFHEAP_ENABLED)) { | ||
| val sizeInMB = Utils.memoryStringToMb(sparkConf.get(MEMORY_OFFHEAP_SIZE).toString) | ||
| require(sizeInMB > 0, | ||
| s"${MEMORY_OFFHEAP_SIZE.key} must be > 0 when ${MEMORY_OFFHEAP_ENABLED.key} == true") | ||
|
Contributor
There was a problem hiding this comment. Please check if
Contributor
Author
There was a problem hiding this comment. A little conflict with the if
Contributor
There was a problem hiding this comment. Then I think we should change the code here.
Contributor
Author
There was a problem hiding this comment. 0 is defaultValue, change to ?
Contributor
Author
There was a problem hiding this comment. Maybe we should give a suitable defaultValue ,like 1073741824(1g)?
Contributor
Author
There was a problem hiding this comment. @jerryshao Do we need to change 0 to a suitable defaultValue?
Contributor
There was a problem hiding this comment. I see, then I would suggest not to change it. Seems there's no good value which could cover most of the scenarios, so good to leave as it is.
Contributor
There was a problem hiding this comment. its odd that check is >= 0 in the config, seems like we should change but can you file a separate jira for that?
Contributor
Author
There was a problem hiding this comment. OK~ I will add a new jira to discuss this issue. |
||
| sizeInMB | ||
| } else { | ||
| 0 | ||
| } | ||
| } | ||
| } | ||
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
maybe we should remove
interned strings, it use heap space after Java8