[SPARK-26714][CORE][WEBUI] Show 0 partition job in WebUI#23637
[SPARK-26714][CORE][WEBUI] Show 0 partition job in WebUI#23637deshanxiao wants to merge 9 commits intoapache:masterfrom deshanxiao:spark-26714
Conversation
|
It looks like:
|
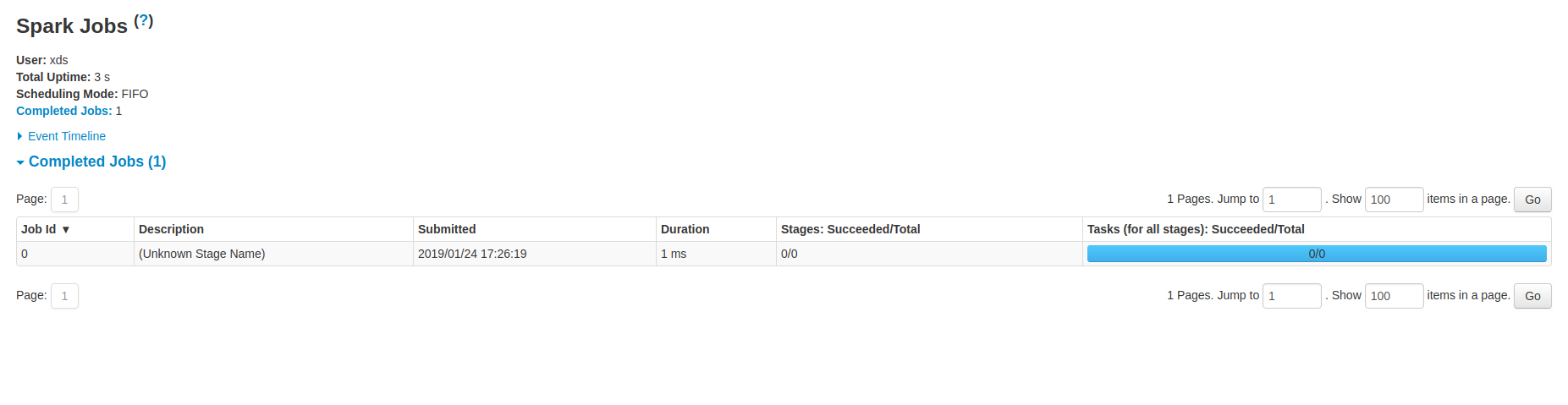
There was a problem hiding this comment.
In this case is there actually an attempt 0?
There was a problem hiding this comment.
Yes! The jobRow invokes the method to generate job page. Maybe I can use a if to handle the partition 0 job.
 srowen
left a comment
srowen
left a comment
There was a problem hiding this comment.
Hm, here's where I just don't know the code well enough to decide if that's the right place to return. I get that you're trying to account for the time taken to process the job, which waits on 0 tasks. Is that meaningful? conceptually it takes no time at all. It always succeeds too, right? can it even fail? it just seems a little weird to check this in two places, but might make sense, not sure.
|
Yes, it takes no time at all and It always succeeds. Maybe using the same time in |
srowen
left a comment
There was a problem hiding this comment.
Yeah I was more comfortable with the original change, as you have it now.
|
retest this please. |
|
|
||
| val jobId = nextJobId.getAndIncrement() | ||
| if (partitions.size == 0) { | ||
| val time = clock.getTimeMillis() |
There was a problem hiding this comment.
This is looking OK to me, though I wouldn't mind, say, @cloud-fan taking a quick look.
There was a problem hiding this comment.
@srowen Thank you! @cloud-fan Could you give me some suggestions?
|
LGTM, cc @gengliangwang |
|
After the changes, the UI is kind of confusing. Should we revise the wording "(Unknown Stage Name)"? |
|
@gengliangwang actually now it will use the job.name as description if present, yes. That screenshot was from the original version of the PR. |
|
Test build #4534 has finished for PR 23637 at commit
|
|
@gengliangwang @srowen Sorry, maybe I didn't make it clear. The job.name will be We can see the default job.name will be sent in: So, if necessary, we can set job.name in two methods:
But it will be more complex and get some compatibility problem. In the end, I change it to original. Mybe the UI is kind of confusing. This is acceptable because the job description in here places the last stage info originally. In this case, we have no stage. So showing "Unknown Stage Name" is acceptable I think. |
|
Here is the lastest PR screenshot:
|
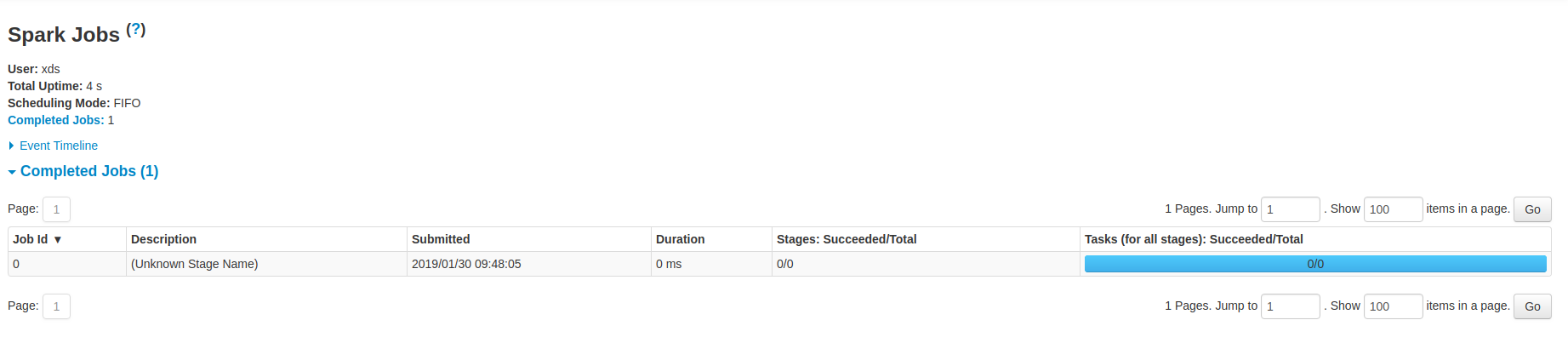
|
Oh I see. Well it's consistent with the current logic which uses job.name in all cases as a fallback. I think this is OK; I'm not sure what other placeholder string would be more meaningful. |
|
@srowen Yes, I argee with you. @gengliangwang Could you give me some suggestions? What placeholder string more meaningful do you think? |
|
Hi @deshanxiao , |
|
I get it. Thank you @gengliangwang! I think |
|
Retest please. |
|
ok to test |
|
Test build #101929 has finished for PR 23637 at commit
|
|
retest this please |
|
Test build #101943 has finished for PR 23637 at commit
|
|
Merged to master |
## What changes were proposed in this pull request?
When the job's partiton is zero, it will still get a jobid but not shown in ui. It's strange. This PR is to show this job in ui.
Example:
In bash:
mkdir -p /home/test/testdir
sc.textFile("/home/test/testdir")
Some logs:
```
19/01/24 17:26:19 INFO FileInputFormat: Total input paths to process : 0
19/01/24 17:26:19 INFO SparkContext: Starting job: collect at WordCount.scala:9
19/01/24 17:26:19 INFO DAGScheduler: Job 0 finished: collect at WordCount.scala:9, took 0.003735 s
```
## How was this patch tested?
UT
Closes apache#23637 from deshanxiao/spark-26714.
Authored-by: xiaodeshan <xiaodeshan@xiaomi.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
What changes were proposed in this pull request?
When the job's partiton is zero, it will still get a jobid but not shown in ui. It's strange. This PR is to show this job in ui.
Example:
In bash:
mkdir -p /home/test/testdir
sc.textFile("/home/test/testdir")
Some logs:
How was this patch tested?
UT