[SPARK-24149][YARN][FOLLOW-UP] Only get the delegation tokens of the filesystem explicitly specified by the user #21734
Conversation
|
Test build #92736 has finished for PR 21734 at commit
|
|
Test build #92737 has finished for PR 21734 at commit
|
|
Test build #92742 has finished for PR 21734 at commit
|
|
@wangyum I am not sure about this. It seems an env issue to me. Anyway, if you want to access that namespace, you have to add it to the list of file system to access, so the problem is the same. If you don't access it, then it can just be removed from your config. What do you think? |
|
@mgaido91 Yes. it's a env issue. I think it is mainly compatible with the previous Spark. If it fails since SPARK-24149, we only can do is change the |
|
Shall we fix this issue in |
|
It will spend a lot of time to fetch tokens. I add some print at filesystems.foreach { fs =>
try {
logInfo("getting token for: " + fs)
logWarning("begin")
fs.addDelegationTokens(renewer, creds)
logWarning("end")
} catch {
case _: ConnectTimeoutException =>
logError(s"Failed to fetch Delegation Tokens.")
case e: Throwable =>
logError("Error while fetch Delegation Tokens.", e)
}
}This is the log file. |
|
There is a conflict here. I configured |
|
Test build #92785 has finished for PR 21734 at commit
|
|
a) |
|
Test build #92788 has finished for PR 21734 at commit
|
| val filesystemsToAccess = sparkConf.get(FILESYSTEMS_TO_ACCESS) | ||
| .map(new Path(_).getFileSystem(hadoopConf)) | ||
| .toSet | ||
| val isRequestAllDelegationTokens = filesystemsToAccess.isEmpty |
There was a problem hiding this comment.
this would mean that if you have your running application accessing different namespaces and you want to add a new namespace to connect to, if you just add the namespace you need the application can break as we are not getting anymore the tokens for the other namespaces.
I'd rather follow @jerryshao's comment about avoiding to crash if the renewal fails, this seems to fix your problem and it doesn't hurt other solutions.
There was a problem hiding this comment.
The fetch delegation token is inherently heavy. It took 22 seconds to get 5 tokens:
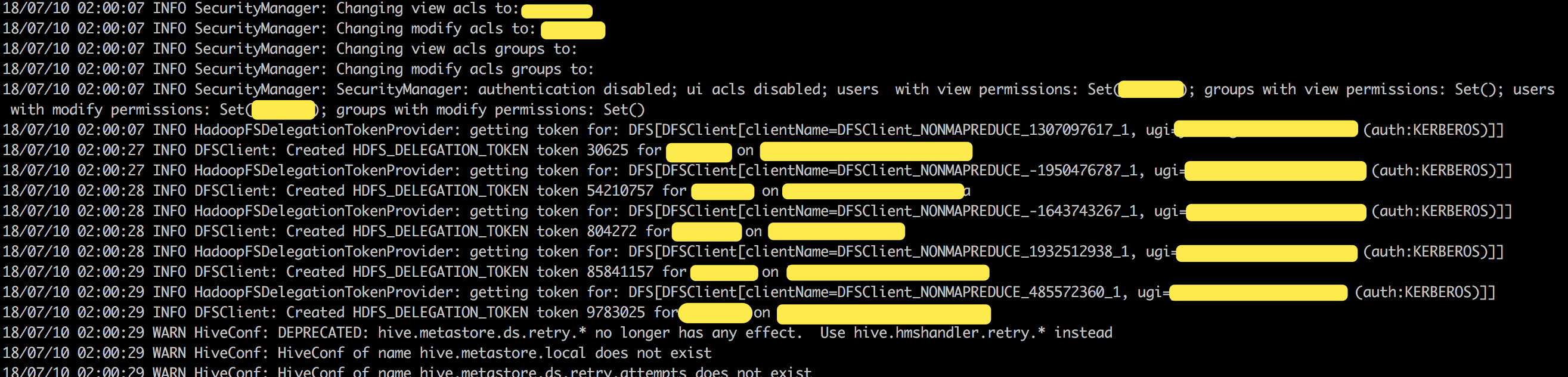
There was a problem hiding this comment.
Now the spark.yarn.access.hadoopFileSystems configuration is invalid, always get all tokens.
There was a problem hiding this comment.
Users should be able to configure their needed FileSystem for better performance at least.
There was a problem hiding this comment.
spark.yarn.access.hadoopFileSystems is not invalid, it is just needed to access external cluster, which is what it was created for. Moreover, if you use viewfs, the same operations are performed under the hood by Hadoop code. So this seems to be a more general performance/scalability issue on the number of namespaces we support.
There was a problem hiding this comment.
spark.yarn.access.hadoopFileSystems is not used as what you think. I don't think changing the semantics of spark.yarn.access.hadoopFileSystems is a correct way.
Basically your problem is that not all the nameservices are accessible in federated HDFS, currently the Hadoop token provider will throw an exception and ignore the following FSs. I think it would be better to try-catch and ignore bad cluster, that would be more meaningful compared to this fix.
If you don't want to get all tokens from all the nameservices, I think you should change the hdfs configuration for Spark. Spark assumes that all the nameservices is accessible. Also token acquisition is happened in application submission, it is not a big problem whether the fetch is slow or not.
There was a problem hiding this comment.
Then spark.yarn.access.hadoopFileSystems only can be used in filesystems that without HA.
Because HA filesystem must configure 2 namenodes info in hdfs-site.xml.
There was a problem hiding this comment.
cc @LantaoJin @suxingfate You should be familiar with this.
There was a problem hiding this comment.
@wangyum spark.yarn.access.hadoopFileSystems could be set with HA.
For example:
--conf spark.yarn.access.hadoopFileSystems hdfs://cluster1-ha,hdfs://cluster2-ha
in hdfs-site.xml
<property>
<name>dfs.nameservices</name>
<value>cluster1-ha,cluster2-ha</value>
</property>
<property>
<name>dfs.ha.namenodes.cluster1-ha</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.ha.namenodes.cluster2-ha</name>
<value>nn1,nn2</value>
</property>
|
I generally dislike adding new configs for things that can be solved without one. Saisai's suggestion seems good enough - catch the error and print a warning about the specific file system that won't be available. User app will fail if it tries to talk to that fs in any case. Maybe throw an exception if you weren't able to get any delegation tokens. |
|
Thanks @vanzin If there is a problem with a filesystem, it will take a long time to retry when get the delegation token. The new approach is:
|
|
Ok, since SPARK-24149 hasn't shipped in any release, it sounds ok to change the behavior of the config. I don't love it, but it seems consistent with the previous behavior. I'd rename |
|
Test build #95241 has finished for PR 21734 at commit
|
|
Merging to master. |
…filesystem explicitly specified by the user ## What changes were proposed in this pull request? Our HDFS cluster configured 5 nameservices: `nameservices1`, `nameservices2`, `nameservices3`, `nameservices-dev1` and `nameservices4`, but `nameservices-dev1` unstable. So sometimes an error occurred and causing the entire job failed since [SPARK-24149](https://issues.apache.org/jira/browse/SPARK-24149):  I think it's best to add a switch here. ## How was this patch tested? manual tests Closes apache#21734 from wangyum/SPARK-24149. Authored-by: Yuming Wang <[email protected]> Signed-off-by: Marcelo Vanzin <[email protected]>
{kind=link}
What changes were proposed in this pull request?
Our HDFS cluster configured 5 nameservices:
nameservices1,nameservices2,nameservices3,nameservices-dev1andnameservices4, butnameservices-dev1unstable. So sometimes an error occurred and causing the entire job failed since SPARK-24149:I think it's best to add a switch here.
How was this patch tested?
manual tests