[SPARK-23811][Core] FetchFailed comes before Success of same task will cause child stage never succeed #20930
Conversation
|
The scenario can be reproduced by below test case added in /**
* This tests the case where origin task success after speculative task got FetchFailed
* before.
*/
test("[SPARK-23811] Fetch failed task should kill other attempt") {
// Create 3 RDDs with shuffle dependencies on each other: rddA <--- rddB <--- rddC
val rddA = new MyRDD(sc, 2, Nil)
val shuffleDepA = new ShuffleDependency(rddA, new HashPartitioner(2))
val shuffleIdA = shuffleDepA.shuffleId
val rddB = new MyRDD(sc, 2, List(shuffleDepA), tracker = mapOutputTracker)
val shuffleDepB = new ShuffleDependency(rddB, new HashPartitioner(2))
val rddC = new MyRDD(sc, 2, List(shuffleDepB), tracker = mapOutputTracker)
submit(rddC, Array(0, 1))
// Complete both tasks in rddA.
assert(taskSets(0).stageId === 0 && taskSets(0).stageAttemptId === 0)
complete(taskSets(0), Seq(
(Success, makeMapStatus("hostA", 2)),
(Success, makeMapStatus("hostB", 2))))
// The first task success
runEvent(makeCompletionEvent(
taskSets(1).tasks(0), Success, makeMapStatus("hostB", 2)))
// The second task's speculative attempt fails first, but task self still running.
// This may caused by ExecutorLost.
runEvent(makeCompletionEvent(
taskSets(1).tasks(1),
FetchFailed(makeBlockManagerId("hostA"), shuffleIdA, 0, 0, "ignored"),
null))
// Check currently missing partition
assert(mapOutputTracker.findMissingPartitions(shuffleDepB.shuffleId).get.size === 1)
val missingPartition = mapOutputTracker.findMissingPartitions(shuffleDepB.shuffleId).get(0)
// The second result task self success soon
runEvent(makeCompletionEvent(
taskSets(1).tasks(1), Success, makeMapStatus("hostB", 2)))
// No missing partitions here, this will cause child stage never succeed
assert(mapOutputTracker.findMissingPartitions(shuffleDepB.shuffleId).get.size === 0)
} |
|
Test build #88690 has finished for PR 20930 at commit
|
|
retest this please |
|
Test build #88697 has finished for PR 20930 at commit
|
|
what happened to |
|
|
|
What happened to |
|
The first case, the stage is marked as failed, but not be resubmitted yet. |
|
then why is it a problem? The stage should be resubmitted soon, |
|
Yeah, the stage resubmitted, but there's no missing task for this stage and actually no task will be resubmitted. This mainly because the |
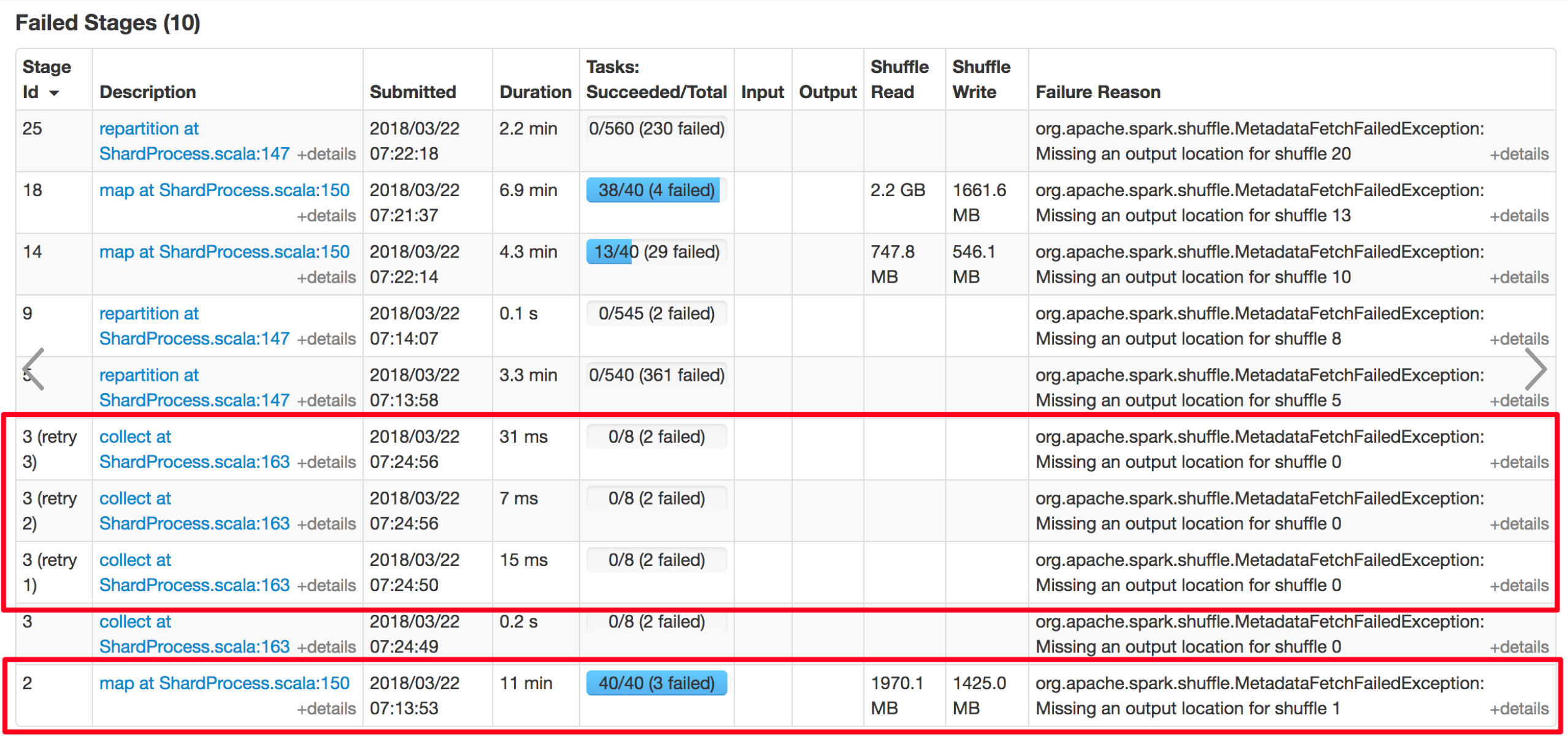
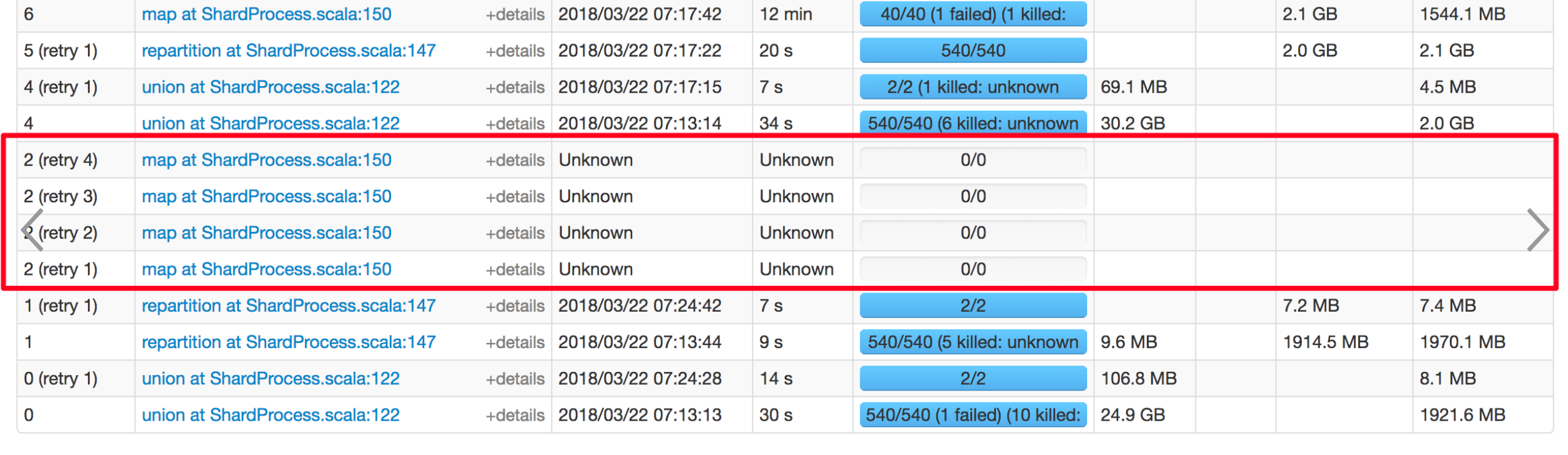
|
What's your proposed fix? it sounds like we can just ignore |
I fix this by killing other attempts while receive a FetchFailed in |
There was a problem hiding this comment.
if this is async, we can't guarantee to not have task success events after marking staging as failed, right?
There was a problem hiding this comment.
This should not work. Maybe we shall just ignore the finished tasks submitted to a failed stage?
There was a problem hiding this comment.
@cloud-fan Yes you're right, I should guarantee this in TaskSetManager.
There was a problem hiding this comment.
@jiangxb1987 Yes, ignore the finished event is necessary, maybe it's also needed to kill useless task?
There was a problem hiding this comment.
I don't think so. Useless tasks should fail soon(FetchFailure usually means mapper is down).
There was a problem hiding this comment.
Got it, I remove the code and UT in next commit.
|
Test build #88806 has finished for PR 20930 at commit
|
There was a problem hiding this comment.
Why are you making this change? I don't quite get it.
There was a problem hiding this comment.
The change of fetchFailedTaskIndexSet is to ignore the task success event if the stage is marked as failed, as Wenchen's suggestion in before comment.
There was a problem hiding this comment.
We should handle this case in DAGScheduler, then we can look up the stage by task id, and see if the stage is failed or not. Then we don't need fetchFailedTaskIndexSet.
There was a problem hiding this comment.
Great thanks for you two's guidance, that's more clear and the UT added for reproducing this problem can also used for checking it!
…s will cause child stage never succeed
08f6930 to
0defc09
Compare
|
@cloud-fan @jiangxb1987 |
|
retest this please |
There was a problem hiding this comment.
Hi, @xuanyuanking. I have some questions with the screenshot you post. Does stage 2 is correspond to the never success stage in PR description ? So, why stage 2 retry 4 times when there's no more missing tasks? As I know, if a stage has 0 task to submit, then, a child stage will be submitted soon. So, in my understanding, there's no retry for stage 2. Hope you can explain more about the screenshot. Thanks.
| } else if (fetchFailedTaskIndexSet.contains(index)) { | ||
| logInfo("Ignoring task-finished event for " + info.id + " in stage " + taskSet.id + | ||
| " because task " + index + " has already failed by FetchFailed") | ||
| return |
There was a problem hiding this comment.
We can not simply return here. And we should always send a task CompletionEvent to DAG, in case of there's any listeners are waiting for it.
There was a problem hiding this comment.
Maybe, we can mark task asFAILED with UnknownReason here. And then, DAG will treat this task as no-op, and registerMapOutput will not be triggered. Though, it is not a elegant way.
There was a problem hiding this comment.
Yep, as @cloud-fan 's suggestion, handle this in DAGScheduler is a better choice.
|
Test build #89389 has finished for PR 20930 at commit
|
|
@Ngone51 Thanks for your review.
Stage 3 is the never success stage, stage 2 is its parent stage.
Stage 2 retry 4 times triggered by Stage 3's fetch failed event. Actually in this scenario, stage 3 will always failed by fetch fail. |
| * before. | ||
| */ | ||
| test("[SPARK-23811] FetchFailed comes before Success of same task will cause child stage" + | ||
| " never succeed") { |
There was a problem hiding this comment.
nit: the test name should describe the expected behavior not the wrong one.
SPARK-23811: staged failed by FetchFailed should ignore following successful tasks
There was a problem hiding this comment.
Thanks, I'll change it.
| // The second task's speculative attempt fails first, but task self still running. | ||
| // This may caused by ExecutorLost. | ||
| runEvent(makeCompletionEvent( | ||
| taskSets(1).tasks(1), |
There was a problem hiding this comment.
Sorry I'm not very familiar with this test suite, how can you tell it's a speculative task?
There was a problem hiding this comment.
Here we only need to mock the speculative task failed event came before success event, makeCompletionEvent with same taskSets's task can achieve such goal. This also use in task events always posted in speculation / when stage is killed.
There was a problem hiding this comment.
Maybe, you can runEvent(SpeculativeTaskSubmitted) first to simulate a speculative task submitted before you runEvent(makeCompletetionEvent()).
| } | ||
| if (failedEpoch.contains(execId) && smt.epoch <= failedEpoch(execId)) { | ||
| logInfo(s"Ignoring possibly bogus $smt completion from executor $execId") | ||
| } else if (failedStages.contains(shuffleStage)) { |
There was a problem hiding this comment.
Why we only have a problem with shuffle map task not result task?
There was a problem hiding this comment.
This also confuse me before, as far as I'm concerned, the result task in such scenario(speculative task fail but original task success) is ok because it has no child stage, we can use the success task's result and markStageAsFinished. But for shuffle map task, it will cause inconformity between mapOutputTracker and stage's pendingPartitions, it must fix.
I'm not sure of ResultTask's behavior, can you give some advice?
There was a problem hiding this comment.
Sorry I may nitpick kere. Can you simulate what happens to result task if FechFaileded comes before task success?
There was a problem hiding this comment.
seems we may mistakenly mark a job as finished?
There was a problem hiding this comment.
Sorry I may nitpick here.
No, that's necessary, I should have to make sure about this, thanks for your advice! :)
Can you simulate what happens to result task if FechFaileded comes before task success?
Sure, but it maybe hardly to reproduce this in real env, I'll try to fake it on UT first ASAP.
There was a problem hiding this comment.
Added the UT for simulating this scenario happens to result task.
|
Hi, @xuanyuanking , I'm still confused (smile & cry).
Stage 2 has no missing tasks, right? So, there's no missing partitions for Stage 2 (which means Stage 3 can always get Stage 2's MapOutputs from Hope you can explain more. Thank you very much! |
|
Test build #89479 has finished for PR 20930 at commit
|
|
@Ngone51 |
|
@Ngone51 Ah, maybe I know how the description misleading you, the in the description 5, 'this stage' refers to 'Stage 2' in screenshot, thanks for your check, I modified the description to avoid misleading others. |
|
Hi, @xuanyuanking , thank for your patient explanation, sincerely. With regard to your latest explanation:
However, I don't think stage 2's skip will lead to stage 3 got an error shuffleId, as we've already created all As I struggle for understanding this issue for a while, finally, I got my own inference: (assume the 2 ShuffleMapTasks below is belong to stage 2, and stage 2 has two partitions on map side. And stage 2 has a parent stage named stage 1, and a child stage named stage 3.)
But if the issue is what I described above, we should get Please feel free to point my wrong spot out. Anyway, thanks again. |
|
Stage 0\1\2\3 same with 20\21\22\23 in this screenshot, stage2's shuffleId is 1 but stage3's is 0 can't happen. Good description for the scenario, can't get a FetchFailed because we can get the MapStatus, but get a 'null'. If I'm not mistaken, this also because the ExecutorLost trigger Happy to discuss with all guys and sorry for can't giving more detailed log after checking the root case, this happened in Baidu online env and can't keep all logs for 1 month. I'll keep fixing the case and catching details log as mush as possible. |

If there's a As for stage 3's shuffle Id, that's really weird. Hope you can fix it! @xuanyuanking |
|
Test build #89849 has finished for PR 20930 at commit
|
|
Test build #89850 has finished for PR 20930 at commit
|
| assert(taskSets(1).tasks(1).isInstanceOf[ResultTask[_, _]]) | ||
| runEvent(makeCompletionEvent( | ||
| taskSets(1).tasks(1), Success, makeMapStatus("hostB", 2))) | ||
| assertDataStructuresEmpty() |
There was a problem hiding this comment.
I add this test for answering your previous question "Can you simulate what happens to result task if FechFaileded comes before task success?". This test can pass without my code changing in DAGScheduler.
There was a problem hiding this comment.
I mean the last line, assertDataStructuresEmpty
There was a problem hiding this comment.
Ah, it's used for check job successful complete and all temp structure empty.
There was a problem hiding this comment.
Right. It is a check that we are cleaning up the contents of the DAGScheduler's data structures so that they do not grow without bound over time.
| // The second result task self success soon. | ||
| assert(taskSets(1).tasks(1).isInstanceOf[ResultTask[_, _]]) | ||
| runEvent(makeCompletionEvent( | ||
| taskSets(1).tasks(1), Success, makeMapStatus("hostB", 2))) |
There was a problem hiding this comment.
where is the code in DAGScheduler we ignore this task?
There was a problem hiding this comment.
The success task will be ignored by OutputCommitCoordinator.taskCompleted, in the taskCompleted logic, stageStates.getOrElse will return because the current stage is in failed set.
Wrong answer above, ShuffleMapStage with the same logic, coordinator didn't filter the complete event.
The detailed log providing below:
18/04/26 10:50:24.524 ScalaTest-run-running-DAGSchedulerSuite INFO DAGScheduler: Resubmitting ShuffleMapStage 0 (RDD at DAGSchedulerSuite.scala:74) and ResultStage 1 () due to fetch failure
18/04/26 10:50:24.535 ScalaTest-run-running-DAGSchedulerSuite DEBUG DAGSchedulerSuite$$anon$6: Increasing epoch to 2
18/04/26 10:50:24.538 ScalaTest-run-running-DAGSchedulerSuite INFO DAGScheduler: Executor lost: exec-hostA (epoch 1)
18/04/26 10:50:24.540 ScalaTest-run-running-DAGSchedulerSuite INFO DAGScheduler: Shuffle files lost for executor: exec-hostA (epoch 1)
18/04/26 10:50:24.545 ScalaTest-run-running-DAGSchedulerSuite DEBUG DAGSchedulerSuite$$anon$6: Increasing epoch to 3
18/04/26 10:50:24.552 ScalaTest-run-running-DAGSchedulerSuite DEBUG OutputCommitCoordinator: Ignoring task completion for completed stage
18/04/26 10:50:24.554 ScalaTest-run-running-DAGSchedulerSuite INFO DAGScheduler: ResultStage 1 () finished in 0.136 s
18/04/26 10:50:24.573 ScalaTest-run-running-DAGSchedulerSuite DEBUG DAGScheduler: Removing stage 1 from failed set.
18/04/26 10:50:24.575 ScalaTest-run-running-DAGSchedulerSuite DEBUG DAGScheduler: After removal of stage 1, remaining stages = 1
18/04/26 10:50:24.576 ScalaTest-run-running-DAGSchedulerSuite DEBUG DAGScheduler: Removing stage 0 from failed set.
18/04/26 10:50:24.576 ScalaTest-run-running-DAGSchedulerSuite DEBUG DAGScheduler: After removal of stage 0, remaining stages = 0
There was a problem hiding this comment.
INFO DAGScheduler: ResultStage 1 () finished in 0.136 s
This is unexpected, isn't it?
There was a problem hiding this comment.
and it seems Spark will wrongly isssue a job end event, can you check it in the test?
There was a problem hiding this comment.
Yep, you're right. The success completely event in UT was treated as normal success task. I fixed this by ignore this event at the beginning of handleTaskCompletion.
|
Test build #89870 has finished for PR 20930 at commit
|
|
Have you applied this patch: #17955 ?
|
No, this happened on Spark 2.1. Thanks xingbo & wenchen, I'll port back this patch to our internal Spark 2.1.
Yeah, the description is similar with currently scenario, but there's also a puzzle about the wrong ShuffleId, I'm trying to find the reason. Thanks again for your help, I'll first port back this patch. |
|
No wonder I can't understand the issue for a long time since I've thought it happened on Spark2.3 . And now it makes sense. Thanks @jiangxb1987 |
|
We're closing this PR because it hasn't been updated in a while. This isn't a judgement on the merit of the PR in any way. It's just a way of keeping the PR queue manageable. |
What changes were proposed in this pull request?
This is a bug caused by abnormal scenario describe below:
mapOutputTracker.removeOutputsOnExecutor(execId), shuffleStatus changed.mapOutputTracker.registerMapOutput, this is also the root case for this scenario.I apply the detailed screenshots in jira comments.
How was this patch tested?
Add a new UT in
TaskSetManagerSuite