[SPARK-21117][SQL] Built-in SQL Function Support - WIDTH_BUCKET #18323
There are no files selected for viewing
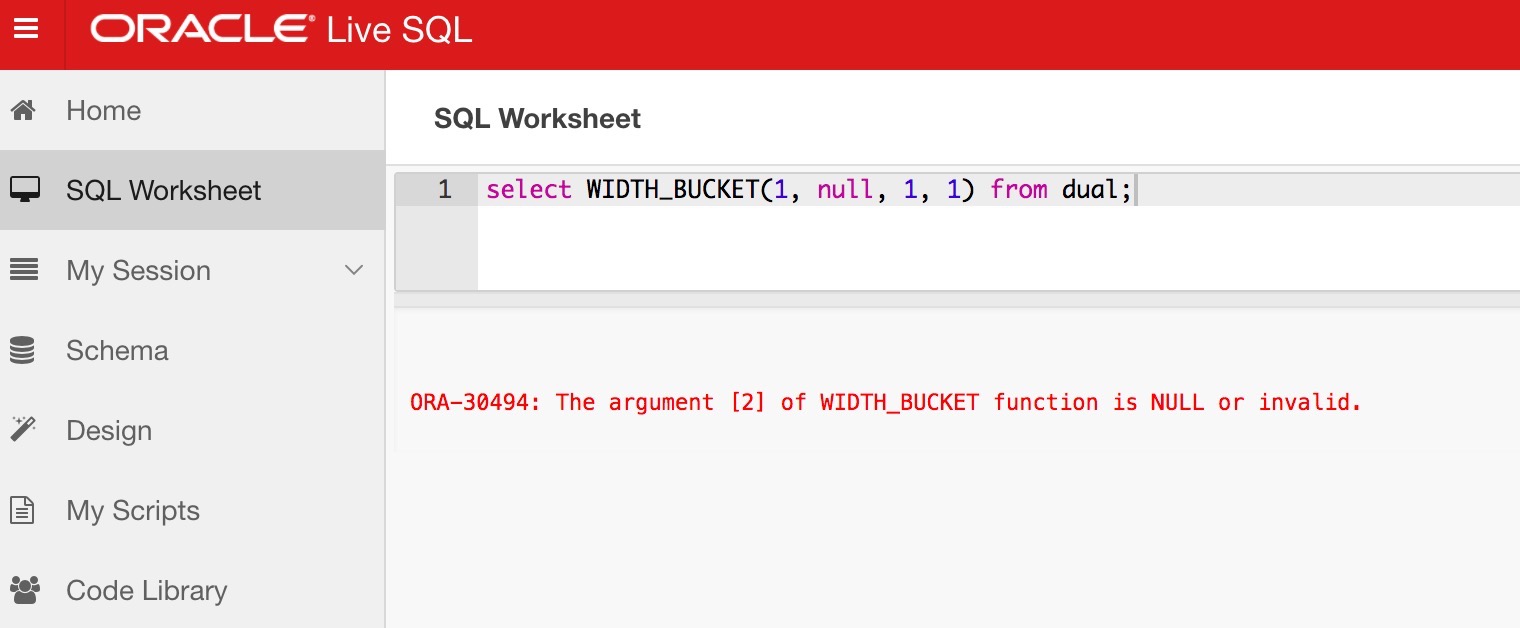
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,52 @@ | ||
| /* | ||
| * Licensed to the Apache Software Foundation (ASF) under one or more | ||
| * contributor license agreements. See the NOTICE file distributed with | ||
| * this work for additional information regarding copyright ownership. | ||
| * The ASF licenses this file to You under the Apache License, Version 2.0 | ||
| * (the "License"); you may not use this file except in compliance with | ||
| * the License. You may obtain a copy of the License at | ||
| * | ||
| * http://www.apache.org/licenses/LICENSE-2.0 | ||
| * | ||
| * Unless required by applicable law or agreed to in writing, software | ||
| * distributed under the License is distributed on an "AS IS" BASIS, | ||
| * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | ||
| * See the License for the specific language governing permissions and | ||
| * limitations under the License. | ||
| */ | ||
|
|
||
| package org.apache.spark.sql.catalyst.util | ||
|
|
||
| import org.apache.spark.sql.AnalysisException | ||
|
|
||
| object MathUtils { | ||
|
|
||
| /** | ||
| * Returns the bucket number into which | ||
| * the value of this expression would fall after being evaluated. | ||
| * | ||
| * @param expr is the expression for which the histogram is being created | ||
| * @param minValue is an expression that resolves | ||
| * to the minimum end point of the acceptable range for expr | ||
| * @param maxValue is an expression that resolves | ||
| * to the maximum end point of the acceptable range for expr | ||
| * @param numBucket is an expression that resolves to | ||
| * a constant indicating the number of buckets | ||
| * @return Returns an long between 0 and numBucket+1 by mapping the expr into buckets defined by | ||
| * the range [minValue, maxValue]. | ||
| */ | ||
| def widthBucket(expr: Double, minValue: Double, maxValue: Double, numBucket: Long): Long = { | ||
| val lower: Double = Math.min(minValue, maxValue) | ||
| val upper: Double = Math.max(minValue, maxValue) | ||
|
Contributor
There was a problem hiding this comment. Does other databases allow max value to appear first? i.e.
Member
Author
There was a problem hiding this comment. Yes, Oracle support it. |
||
|
|
||
| val result: Long = if (expr < lower) { | ||
|
Member
There was a problem hiding this comment. // an underflow bucket numbered 0
Member
Author
There was a problem hiding this comment. Added 2 test case: |
||
| 0 | ||
| } else if (expr >= upper) { | ||
| numBucket + 1L | ||
|
Member
There was a problem hiding this comment. // an overflow bucket numbered num_buckets+1
Member
Author
There was a problem hiding this comment. Added 2 test case: |
||
| } else { | ||
| (numBucket.toDouble * (expr - lower) / (upper - lower) + 1).toLong | ||
|
|
||
| } | ||
|
|
||
| if (minValue > maxValue) (numBucket - result) + 1 else result | ||
| } | ||
| } | ||
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,46 @@ | ||
| /* | ||
| * Licensed to the Apache Software Foundation (ASF) under one or more | ||
| * contributor license agreements. See the NOTICE file distributed with | ||
| * this work for additional information regarding copyright ownership. | ||
| * The ASF licenses this file to You under the Apache License, Version 2.0 | ||
| * (the "License"); you may not use this file except in compliance with | ||
| * the License. You may obtain a copy of the License at | ||
| * | ||
| * http://www.apache.org/licenses/LICENSE-2.0 | ||
| * | ||
| * Unless required by applicable law or agreed to in writing, software | ||
| * distributed under the License is distributed on an "AS IS" BASIS, | ||
| * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | ||
| * See the License for the specific language governing permissions and | ||
| * limitations under the License. | ||
| */ | ||
|
|
||
| package org.apache.spark.sql.catalyst.util | ||
|
|
||
| import org.apache.spark.SparkFunSuite | ||
| import org.apache.spark.sql.AnalysisException | ||
| import org.apache.spark.sql.catalyst.util.MathUtils._ | ||
|
|
||
| class MathUtilsSuite extends SparkFunSuite { | ||
|
|
||
| test("widthBucket") { | ||
| assert(widthBucket(5.35, 0.024, 10.06, 5) === 3) | ||
| assert(widthBucket(0, 1, 1, 1) === 0) | ||
| assert(widthBucket(20, 1, 1, 1) === 2) | ||
|
|
||
| // Test https://docs.oracle.com/cd/B28359_01/olap.111/b28126/dml_functions_2137.htm#OLADM717 | ||
| // WIDTH_BUCKET(credit_limit, 100, 5000, 10) | ||
| assert(widthBucket(500, 100, 5000, 10) === 1) | ||
| assert(widthBucket(2300, 100, 5000, 10) === 5) | ||
| assert(widthBucket(3500, 100, 5000, 10) === 7) | ||
| assert(widthBucket(1200, 100, 5000, 10) === 3) | ||
| assert(widthBucket(1400, 100, 5000, 10) === 3) | ||
| assert(widthBucket(700, 100, 5000, 10) === 2) | ||
| assert(widthBucket(5000, 100, 5000, 10) === 11) | ||
| assert(widthBucket(1800, 100, 5000, 10) === 4) | ||
| assert(widthBucket(400, 100, 5000, 10) === 1) | ||
|
|
||
| // minValue == maxValue | ||
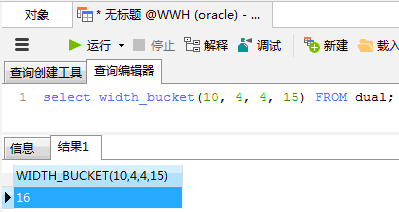
| assert(widthBucket(10, 4, 4, 15) === 16) | ||
|
Contributor
There was a problem hiding this comment. Is this behavior consistent with other databases? If so, then I'm fine with this and please ignore my previous comment.
Member
Author
There was a problem hiding this comment. Yes, This is Oracle's behavior: |
||
| } | ||
| } | ||
Uh oh!
There was an error while loading. Please reload this page.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
nit: how about the format and the rephrasing below?