[SPARK-21039] [Spark Core] Use treeAggregate instead of aggregate in DataFrame.stat.bloomFilter #18263
Conversation
|
I think we need some figures here. Would you test before/after and share some figures? |
|
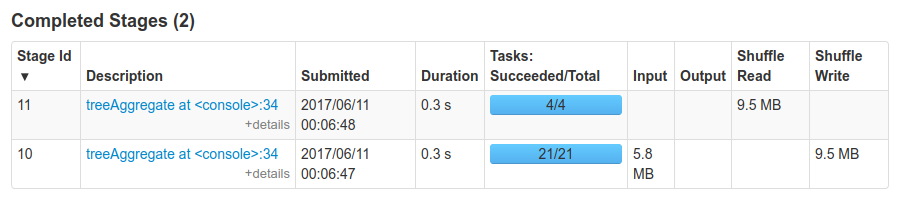
I ran some tests on a cluster with 5 nodes, 5 executors, and 5 threads per executor. The cluster
ResultsUsing
|
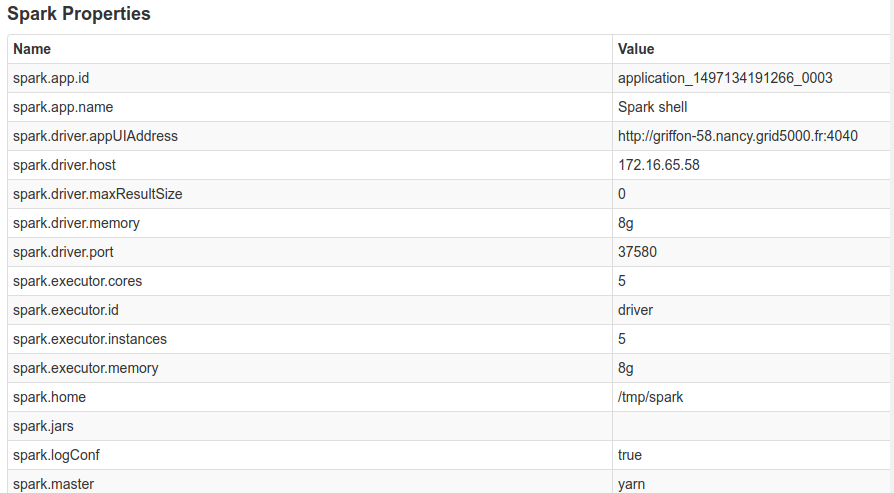

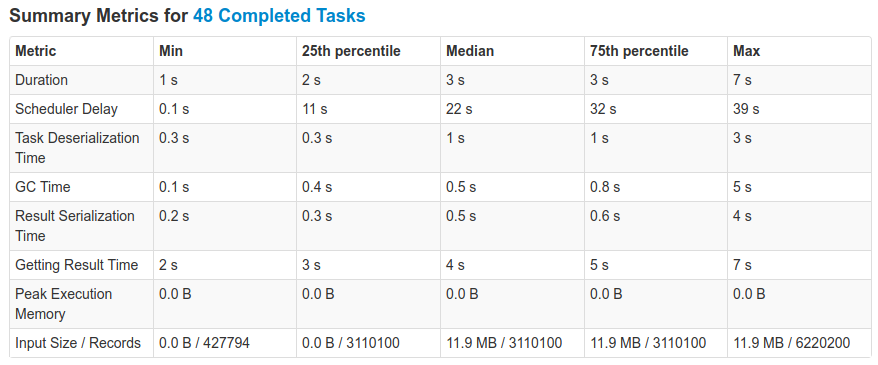
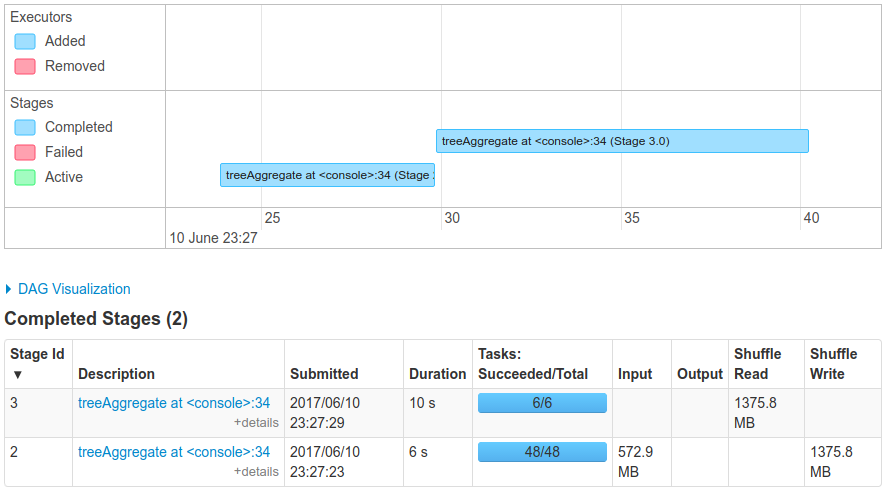
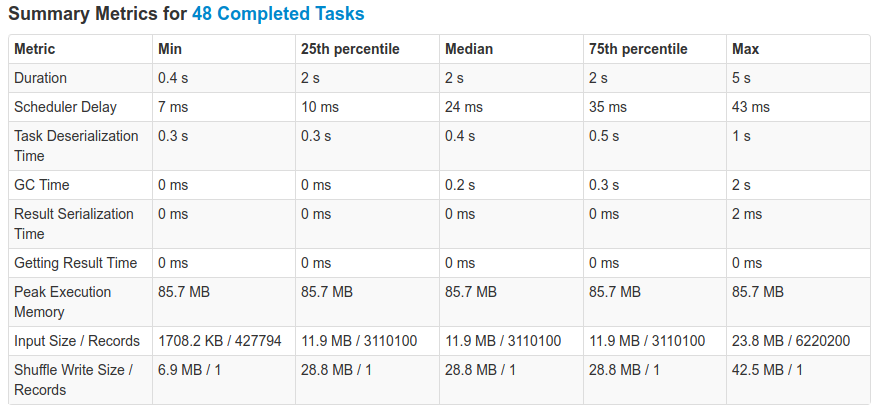
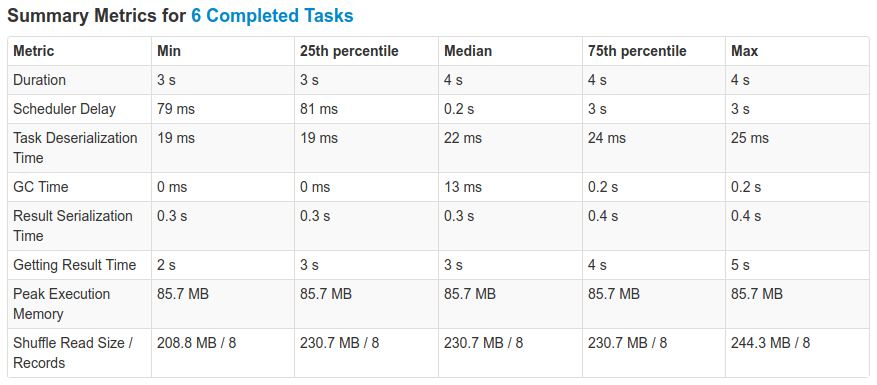
Smaller dataYou might be wondering: what about smaller data ? I repeated the same experiment as mentioned above, but with a scale factor of 1, (and 1.5M elements in the bloom filter). With
|

 srowen
left a comment
srowen
left a comment
There was a problem hiding this comment.
I'm inclined to use treeAggregate where possible. I think the win for larger data sets is worthwhile.
 HyukjinKwon
left a comment
HyukjinKwon
left a comment
There was a problem hiding this comment.
LGTM too given both are semantically identical and the same reason with ^.
|
Test build #3796 has finished for PR 18263 at commit
|
|
Merged to master |
…ataFrame.stat.bloomFilter ## What changes were proposed in this pull request? To use treeAggregate instead of aggregate in DataFrame.stat.bloomFilter to parallelize the operation of merging the bloom filters (Please fill in changes proposed in this fix) ## How was this patch tested? unit tests passed (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Rishabh Bhardwaj <[email protected]> Author: Rishabh Bhardwaj <[email protected]> Author: Rishabh Bhardwaj <[email protected]> Author: Rishabh Bhardwaj <[email protected]> Author: Rishabh Bhardwaj <[email protected]> Closes apache#18263 from rishabhbhardwaj/SPARK-21039.
What changes were proposed in this pull request?
To use treeAggregate instead of aggregate in DataFrame.stat.bloomFilter to parallelize the operation of merging the bloom filters
(Please fill in changes proposed in this fix)
How was this patch tested?
unit tests passed
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.